
1. 摘要
序列推荐是根据用户的历史交互预测其下一个感兴趣的物品。近来,由于大语言模型(LLM)具有广泛的世界知识和内在的推理能力,驱动着推荐领域的研究者探索大语言模型在序列推荐中的应用潜力。基于大语言模型的推荐系统,其核心是将序列推荐重塑为语言建模(Language Modeling)任务 —— 也就是说,将行为序列转化为文本输入提示(Prompt),例如,“该用户已经观看了[物品1]、[物品2]、...、[物品𝑛],请预测这个用户接下来会看什么电影。” 当考虑如何在提示中表示物品(例如,[物品𝑘])时,先前的研究可分为基于ID的表征(如ID 数字或随机初始化的ID token)和基于文本的表征(如标题和文本描述等)两类。然而,这些方法往往无法全面利用世界知识或展示足够的行为理解能力。
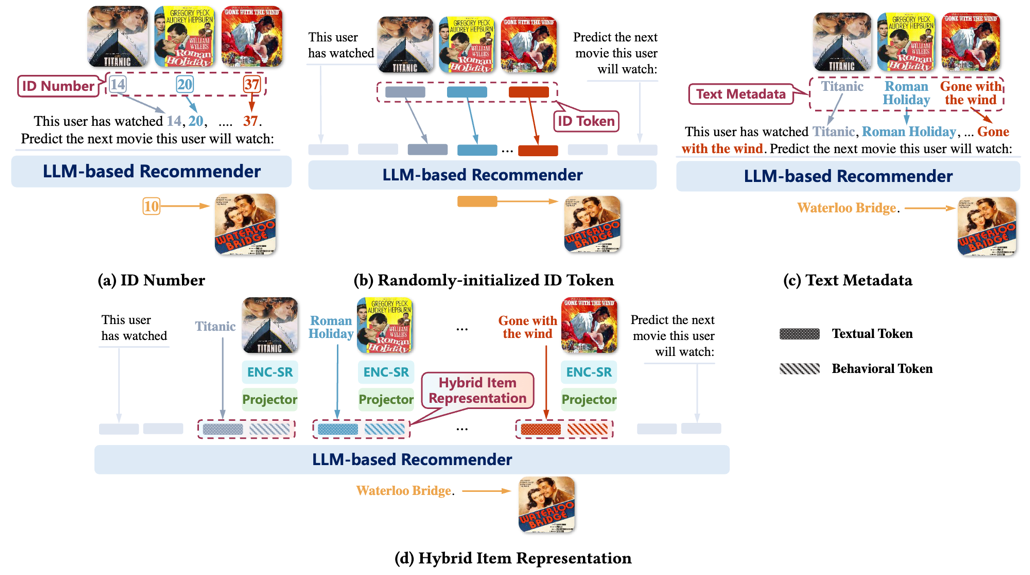
图1:不同的物品表征方式对比 近日,来自中国科学技术大学和香港理工大学的研究团队,针对基于大语言模型的推荐系统在将序列推荐任务转换为语言建模时的物品表征问题,提出了一种混合提示(Hybrid Prompting)方法,结合传统推荐系统对用户行为模式的理解和大语言模型关于物品的背景知识,并以课程学习(Curriculum learning)的策略渐进实现了传统推荐系统与大语言模型之间的对齐,提升了语言模型完成序列推荐任务的效果。

该论文发表于SIGIR’ 2024 论文地址:https://arxiv.org/abs/2312.02445项目地址:https://github.com/ljy0ustc/LLaRA
2.方法
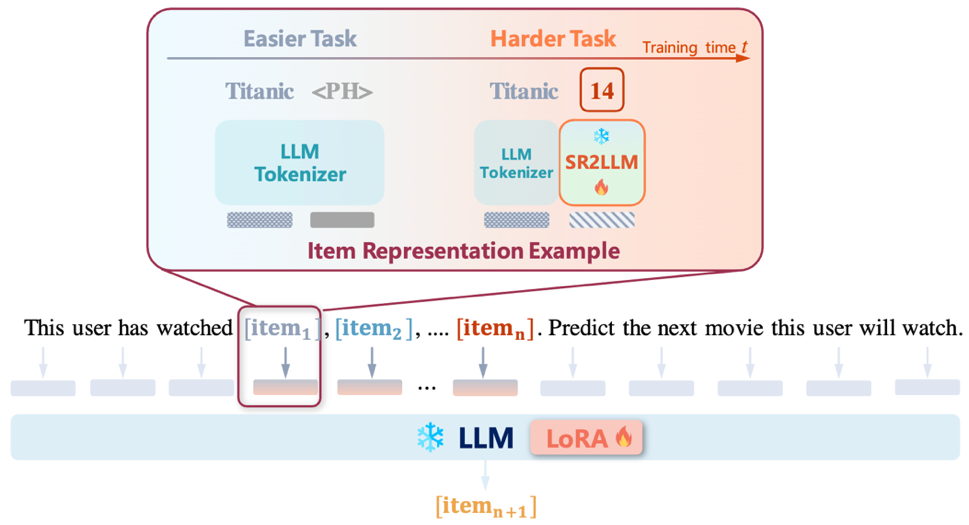
图2:LLaRA整体框架尽管现有工作已展示出大语言模型具有一定的序列推荐能力,但仅仅在文本模态对用户交互序列进行建模仍存在局限性:无法充分地挖掘用户的行为模式。为对交互序列中的物品寻求更好的表征的方式,我们将传统推荐模型对物品的表征视为文本之外的一个新的模态,提出了LLaRA框架:(1)LLaRA设计了传统推荐模型的物品表征-文本projector来弥合传统推荐模型与语言模型之间的模态差异,使得LLM能够理解传统推荐模型学习到的用户行为模式。 (2)LLaRA采用混合提示,在表征物品时融合文本token和行为token,从而同时利用了传统模型对用户行为序列的理解能力,和大语言模型关于物品的背景知识及推理能力。(3)LLaRA以课程学习策略,由易到难,渐进地对大语言模型进行微调,注入新模态。
2.1 提示中的物品表示
1)文本token物品的文本特征,例如标题和描述,是激发LLM中内在的常识知识的关键。对具有文本元数据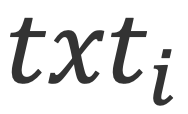
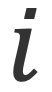
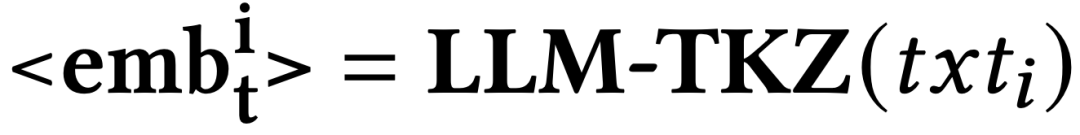
传统的序列推荐模型,如 GRU4Rec、Caser 和 SASRec ,在对历史交互数据进行训练后,有效地捕获了基于ID的物品嵌入中的序列模式。对物品
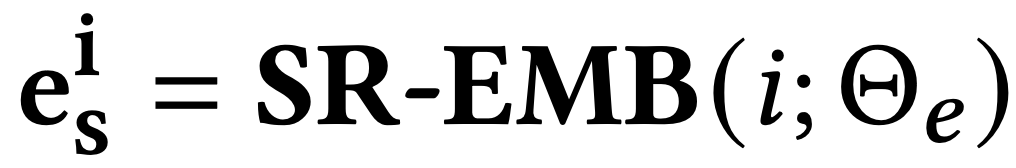
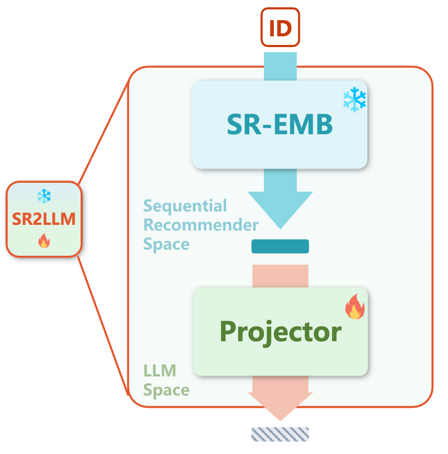
与可以自然地插入到提示中并可以被轻易理解的物品文本表示相比,基于ID的物品表示可能与大语言模型提示的文本性质不兼容。因此,我们将基于ID的表示视为一个与文本数据分离的新模态。为了弥合模态间的差距,将传统推荐模型的基于ID的表示空间以如下方式映射到大语言模型的输入空间: 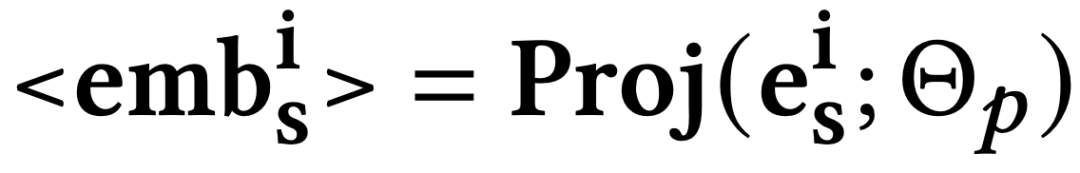
进行全面的描述,有效地结合了每个token捕获的独特而互补的各个方面:
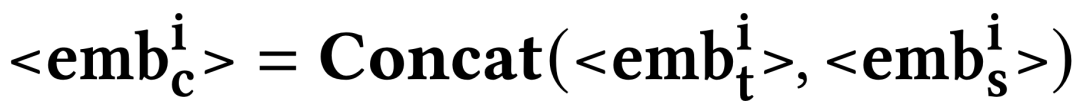
2.2 提示设计
我们设计了两种提示——1)仅文本的提示,2)混合提示;它们各自都包含序列推荐任务定义,用户交互序列和下一个物品的候选集。两种提示中物品的表示方法分别为文本token和混合token。
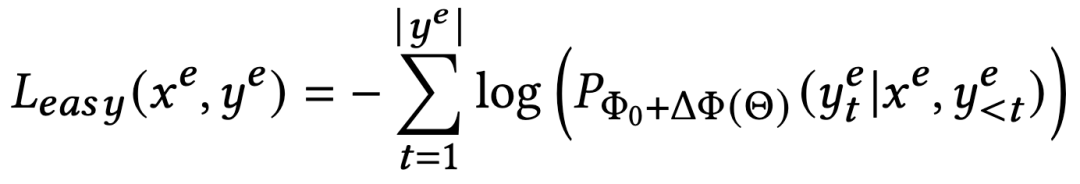
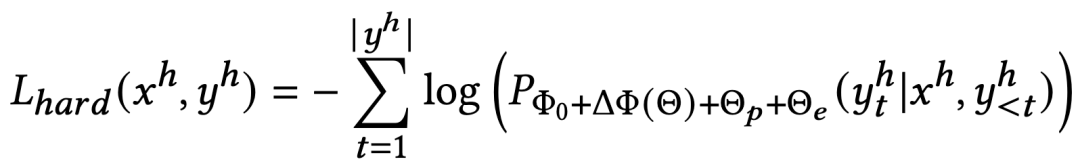
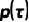
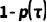
随时间以如下方式递增:
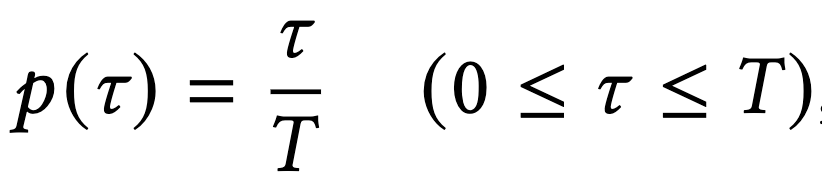
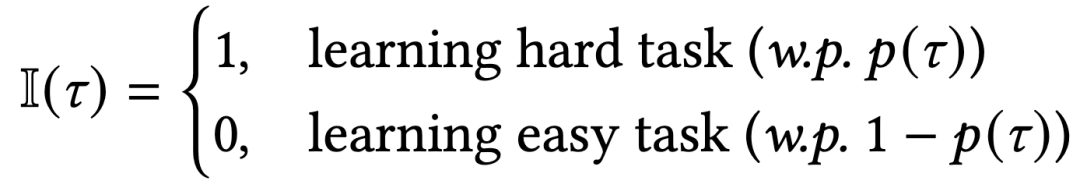
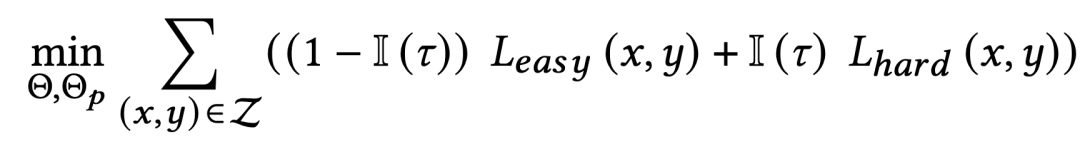
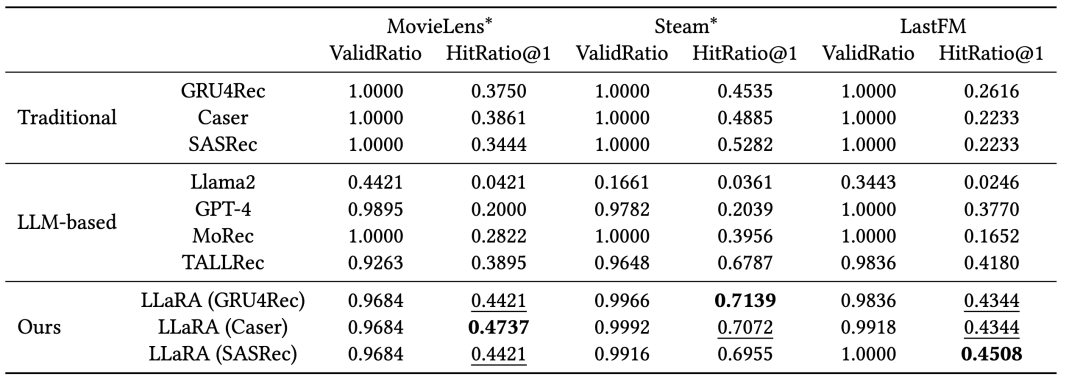
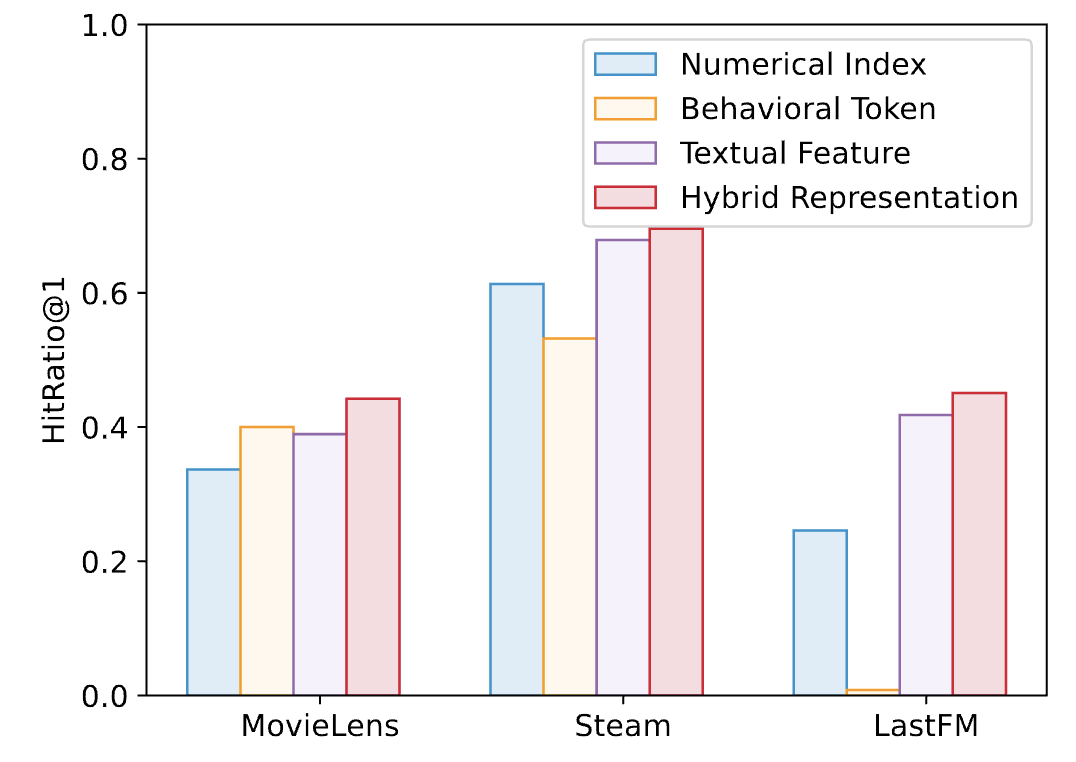
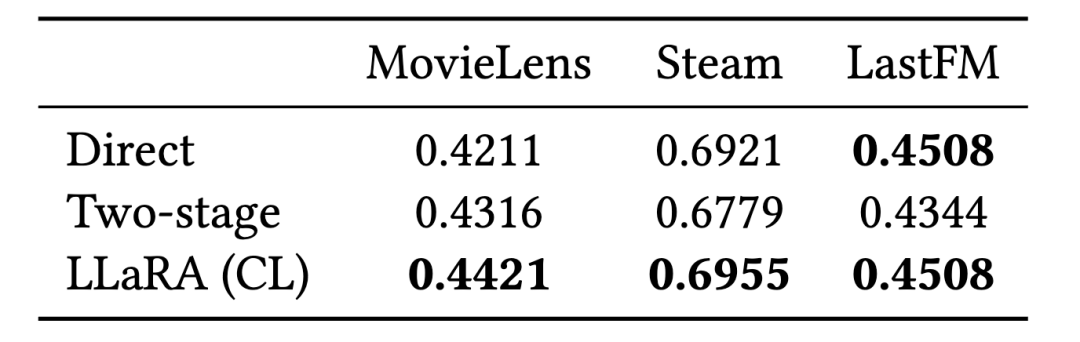
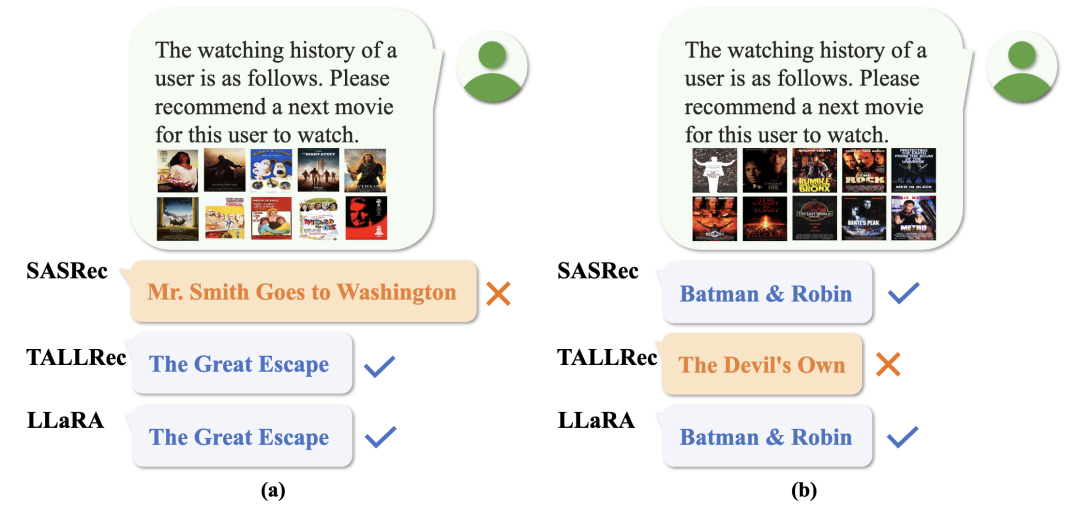
4.未来展望LLaRA标志着从传统推荐模型向更复杂的、以大语言模型为基础的方法过渡的初步尝试,并开启了新的研究可能性。它通过一种对齐机制,为传统推荐模型与大语言模型之间搭建了桥梁。在未来,研究者们可以继续探索一个统一的推荐框架,以自然语言为接口,用于更复杂和多样化的推荐场景。我们希望LLaRA的发展为个性化、集成化、通用推荐系统的新时代铺平道路。


