

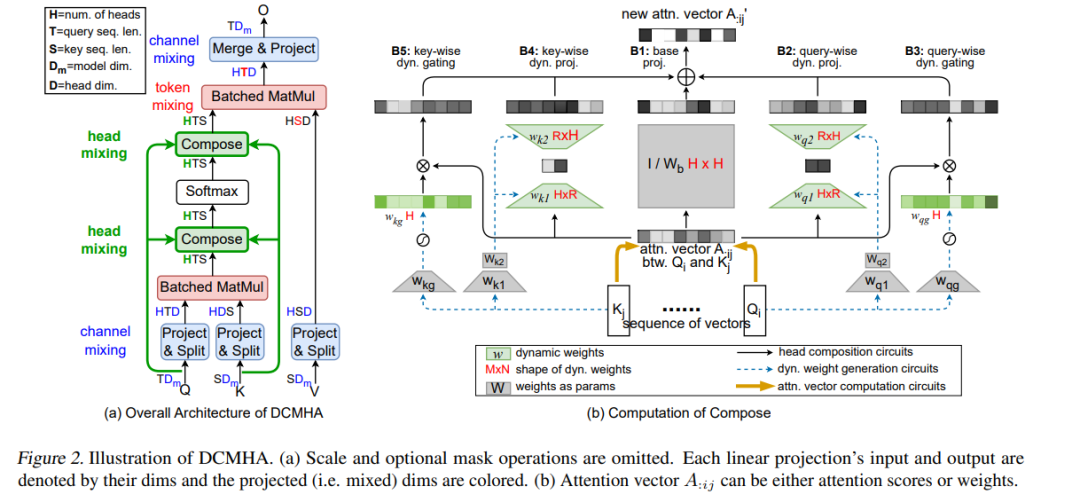
多头注意力机制(Multi-Head Attention, MHA)是Transformer的关键组件之一。在MHA中,各个注意力头独立工作,这会导致一些问题,如注意力分数矩阵的低秩瓶颈和头部冗余。我们提出了动态可组合多头注意力机制(Dynamically Composable Multi-Head Attention, DCMHA),这是一种参数和计算高效的注意力架构,旨在解决MHA的缺点并通过动态组合注意力头来增强模型的表达能力。
**DCMHA的核心概念
DCMHA的核心是一个Compose函数,该函数以输入为依赖动态变换注意力分数矩阵和权重矩阵。DCMHA可以作为MHA的直接替代品应用于任何Transformer架构,从而获得相应的DCFormer。DCFormer在不同架构和模型规模的语言模型任务中显著优于传统的Transformer,匹配计算量约为1.7至2.0倍的模型的性能。例如,DCPythia-6.9B在预训练困惑度和下游任务评估上均优于开源的Pythia-12B模型。
**动态可组合多头注意力机制的优势
- 参数和计算效率:DCMHA通过动态组合注意力头,在不显著增加参数和计算量的情况下,增强了模型的表达能力。
- 注意力矩阵的动态调整:Compose函数能够根据输入动态调整注意力分数和权重矩阵,避免了传统MHA中的低秩瓶颈问题。
- 减少头部冗余:通过动态组合,DCMHA能够有效减少注意力头的冗余,提升模型的整体性能。
**实验结果
DCFormer在多种架构和模型规模的语言模型任务中表现出了优异的性能。例如,DCPythia-6.9B在预训练困惑度和下游任务评估上均优于开源的Pythia-12B模型,展示了动态可组合多头注意力机制的巨大潜力。
**获取代码和模型
代码和模型可在以下链接获取:https://github.com/Caiyun-AI/DCFormer。 通过引入DCMHA,我们能够有效提升Transformers在各种任务中的表现,使其成为更强大、更高效的深度学习模型。
成为VIP会员查看完整内容
相关内容
相关主题
相关VIP内容
相关资讯
相关论文