
【导读】2024年国际万维网大会The Web Conference(旧称WWW)将于2023年5月13日-5月17号日召开。TheWebConf是中国计算机学会(CCF)推荐的A类国际学术会议,是互联网技术领域最重要的国际会议之一,由国际万维网会议委员会(IW3C2)和主办地地方团队合作组织,每年召开一次。WWW-2024共接受投稿2008篇,录用率为20.2%。刚刚最佳论文一系列奖项出炉了!来自谷歌的大语言模型《 Mechanism Design for Large Language Models**》获得最佳论文,爱森堡大学《Stable-Sketch: A Versatile Sketch for Accurate, Fast, Web-Scale Data Stream Processing》获得最佳学生论文!**

自从1989年万维网发明以来,“WWW”会议作为计算机与互联网领域的国际性顶级学术会议,不仅一直是全球互联网发展的风向标,而且也是网络业界的专家、学者、企业家们展示和讨论互联网相关研究课题、发展成果、标准设定和应用场景的主要场所。同时,“WWW”会议也被中国计算机学会(CCF)列为《中国计算机学会推荐国际学术会议和期刊目录》的A类学术会议。
详情可登陆以下会议官网查询: https://www2024.thewebconf.org 最佳论文: https://www2024.thewebconf.org/program/awards/

「最佳论文奖」(Best Paper Award)

大规模语言模型的机制设计
作者: Paul Dütting Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, Song Zuo摘要:我们研究了支持新兴的AI生成内容格式的拍卖机制。特别是,我们研究了如何以激励兼容的方式聚合多个大语言模型(LLMs)。在这个问题中,每个代理对随机生成内容的偏好被描述/编码为一个LLM。设计AI生成广告创意的拍卖格式,以结合不同广告商的输入,是一个关键动机。我们认为这个问题虽然通常属于机制设计范畴,但具有几个独特的特征。我们提出了一种通用的形式化模型——代币拍卖模型——来研究这个问题。该模型的一个关键特征是,它在逐个代币的基础上运行,并允许LLM代理通过单维出价影响生成的内容。
我们首先探讨了一种稳健的拍卖设计方法,其中我们仅假设代理偏好包含对结果分布的部分顺序。我们提出了两个自然的激励属性,并表明这些属性等价于分布聚合的单调性条件。我们还表明,对于这种聚合函数,可以设计一个第二价格拍卖,尽管缺乏竞标者的估值函数。然后,我们通过专注于基于KL散度(LLM中常用的损失函数)的具体估值形式,转向设计具体的聚合函数。福利最大化的聚合规则被证明是所有参与者目标分布的加权(对数空间)凸组合。我们最后以实验结果支持代币拍卖的形式化。
https://www.zhuanzhi.ai/paper/e500bc8777f1ed5f10e89f7cff72355c

「最佳学生论文奖」(Best Student Paper Award)

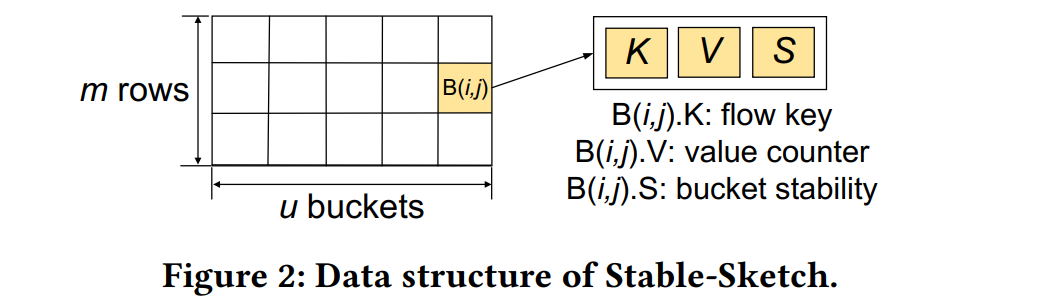
Stable-Sketch:一种用于准确、快速、Web规模数据流处理的多功能Sketch
A Single Vector Is Not Enough: Taxonomy Expansion via Box Embeddings
数据流处理在包括点击欺诈检测、异常识别和推荐系统在内的各种与Web相关的应用中发挥着关键作用。然而,在数据流中准确和快速地检测与这些任务相关的项目(如重击者、重大变化者和持久项目)并非易事。这是由于流速不断增加、当前系统中可用的快速内存(L1缓存)有限以及实践中遇到的高度偏斜的项目分布。因此,仅基于其特征(如项目频率或持久性值)跟踪感兴趣的项目容易被无关项目替换,导致检测精度适中,正如我们揭示的那样。
在这项工作中,我们引入了桶稳定性这一概念,它量化了记录项目变化的程度,并表明这是识别不同项目类型的有力指标。我们提出了Stable-Sketch,这是一种优雅且多功能的Sketch,利用多维信息(包括项目统计和桶稳定性)并采用随机方法来驱动替换决策。我们提出了Stable-Sketch的误差界理论分析,并进行了广泛的实验,证明我们的解决方案在各种项目检测任务中,即使在内存紧张的情况下,也能比最先进的Sketch实现显著更高的精度和更快的处理速度。我们进一步利用单指令多数据(SIMD)指令提高了Stable-Sketch的更新吞吐量,并用P4实现了我们的解决方案,展示了其在现实世界中的部署可行性。
https://dl.acm.org/doi/pdf/10.1145/3589334.3645581
(Seoul Test of Time Award)

在原始的PageRank算法中,为了改进搜索查询结果的排名,使用Web的链接结构计算单个PageRank向量,以捕捉网页的相对“重要性”,而不依赖于任何特定的搜索查询。为了产生更准确的搜索结果,我们提出计算一组基于代表性主题的PageRank向量,以更准确地捕捉与特定主题相关的重要性概念。通过使用这些(预计算的)有偏PageRank向量在查询时生成特定于查询的网页重要性得分,我们证明了可以生成比单个通用PageRank向量更准确的排名。
对于普通关键词搜索查询,我们使用查询关键词的主题来计算满足查询的网页的主题敏感PageRank得分。对于在上下文中进行的搜索(例如,通过在网页中突出显示单词进行的搜索查询),我们使用查询出现的上下文主题来计算主题敏感的PageRank得分。

