弹性伸缩服务实战:我是如何节省80%的机器成本的
前言
今年一直在做的事情就是成本优化,今天分享的是如何打造一个弹性可伸缩服务。
Why? 为什么需要弹性伸缩?
一个网站,通常流量大小不是每时每刻都一样,有高峰,有低谷,如果每时每刻都要保持能够扛住高峰流量的机器数目,那么成本会很高。一个诱人的想法就是根据流量大小自动调节机器的数量,这就需要我们开发弹性伸缩服务。
How?怎么实现弹性伸缩?
我们公司使用的是阿里的ECS,而它提供弹性伸缩组机器,按秒计费,可以随时申请随时释放,它是我们能够进行弹性伸缩的最基本条件。由于这个How内容较多,接下来就详细说一下这个How如何实现。
弹性伸缩服务
这块着实是做了不少的工作,前前后后经历了大半年的时间,接下来一一详述。
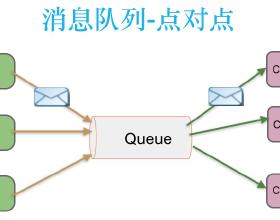
工作模式由“推”改“拉”
我们的弹性分配策略依赖实时的qps,需要实时的获取流量大小,所以必须能够在某个地方获取当前请求的QPS,自然而然会想到使用消息队列,我们可以使用队列提供的接口,获取某段时间内的qps,并根据速率调整我们的机器服务数,这涉及到服务的改造。由于我们的一些服务都是以RPC调用进行交互(即“推”模式),所以势必要改造这些服务,使其主动从队列中拉取消息并处理。如下图所示。
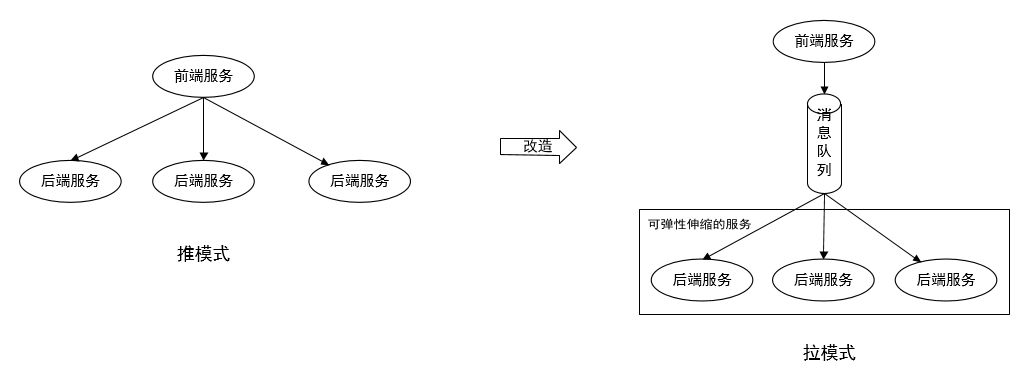
服务拆分,机器降配
我们的计算服务使用的高配置机器(16核16G),而阿里云伸缩组的机器配置很低(最高配置4核,内存大小可调),所以一些计算型服务需要拆分,使其能够在低配机器运行。如下图,是我们做的一个拆分示意。
服务快速部署
由于需要随时增加和减少机器,这需要服务有快速部署上线和下线的能力,所以可以使用docker。具体使用方法本文不赘述。
日志收集
由于弹性伸缩服务随时上下线,但是日志不能扔。需要日志收集服务跟随业务服务一同部署,同样可以利用docker,日志随时收走。
实时分配算法
完成了如上3个基本工作,接下来就好办多了,我们设计一个弹性分配算法:根据队列中进去的消息速率来决定机器数目。
每个服务都需要有一个配置文件
[strategy]
#一个服务能够扛多少qps
speed_ratio = 2.5
#部署一个服务大概需要多少秒
start_time = 300
#每次部署多少个,至少为1
incr_num = 2
#固定机器有多少个
persistence = 16
算法大致流程:
取一段时间间隔内队列中消息速率,假设为A。
获取当前正在运行的服务数S。
计算当前已经启动的服务(固定+弹性分配)能够扛住的速率B(B=S*speed_ratio)。
假设队列中速率波动幅度C(通过观察流量波动写死的固定值)。
如果A>B+C,则申请新机器,根据配置文件,申请incr_num个机器,并部署服务。
如果A<B-C,则释放机器,根据配置文件,释放incr_num个机器,并下线服务。
注意要保持至少persistence指定的机器数,这些机器不能释放,它主要是应付平时低谷时的流量。
问题:
可不可以根据队列中unack的数目来分配机器?
答案是不行。能够唯一表示当前请求大小的指标只有qps,而我们服务可以提前知道的只有性能数据:即单台机器能扛多少qps,而不是单台机器能够减少多少个unack。此外如果使用unack为分配指标,当服务出现bug,大面积宕机时,unack累积非常快,会导致算法分配无限多的机器,而此时解决问题的正解为:回滚服务-查找bug-修正-上线,而不是分配更多的机器,因为新分配的机器部署的服务可能也会宕机。
如何应对流量突增?
本算法主要应对正常情况下的机器分配,对于突增流量分为两种情况。1:正常可预测的突增(比如淘宝双11,双12),这种情况下我们可以先提前准备好大量固定机器,然后把配置中的incr_num调的尽可能大,这样只要流量上涨,可以一次增加几百台甚至上千台机器扛过突增流量。2:异常突增,这种情况对于各种部署方式的服务(即使随时随地保证扛过平时正常情况下的流量峰值)都可能造成危害,并不是只有弹性分配的服务专有,这个时候的正解的是防攻击、流量过滤、降级。
阿里云机器分配集中造成接口失败
当短时间内频繁调用阿里云的机器分配接口,会返回错误信息,造成分配失败。解决方法为,调用加入时间间隔(比如每隔1s调用一次机器分配接口),并且进行失败重试。
阿里云ECS启动失败
有的时候机器申请成功,但是启动失败,情况有两种,1:启动时间过长,2:根本启动不起来。解决这两种问题的方法为,尝试启动一段时间,超过一定时间(比如start_time)后果断放弃,重新申请新机器,防止整个服务启动过程过长跟不上qps的上涨速度。
总结
如今,弹性伸缩服务稳定运行半年有余,节省了大概60%~70%的机器成本,加上前面两个算法优化《我是如何利用跳表优化搜索引擎的?》(http://www.cnblogs.com/haolujun/p/8011776.html),《最长公共子序列与最小编辑距离-你有更快的算法么?》(http://www.cnblogs.com/haolujun/p/7819716.html),使得我负责的服务机器成本下降了80%以上。这也导致了阿里云的小伙伴对我们产生了质疑,怀疑我们正在逐步把服务迁出阿里云,但是这真的是冤枉了我们,谁规定使用阿里云的ECS就不能对服务进行优化了。对于同样使用云ECS的小伙伴,可以考虑用弹性伸缩节省成本,这将是一件很有意思并且富有挑战的事情。
出处:http://www.cnblogs.com/haolujun/p/8075226.html
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。

架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文
相关内容

阿里云(阿里云-为了无法计算的价值)创立于2009年,是全球领先的云计算及人工智能技术公司,为全球200多个国家和地区的创新创业企业、政府机构等提供服务。
阿里云致力于提供安全、可靠的计算和数据处理能力,让计算成为普惠科技和公共服务,为万物互联的DT世界提供源源不断的新能源。阿里云在全球各地部署高效节能的绿色数据中心,利用清洁计算支持不同的互联网应用。目前,阿里云在中国、新加坡、美西、美东等地域设有数据中心。