论文 | 中文词向量论文综述(一)
| 作者:黑龙江大学nlp实验室研究生刘宗林
最近在做中文词向量相关工作,其中看了一些中文词向量的相关论文,在这篇文章,将把近几年的中文词向量进展及其模型结构加以简述,大概要写3-4篇综述,每篇包含2-3篇论文。
论文来源
这是一篇2015年发表在EMNLP(Empirical Methods in Natural Language Processing)会议上的论文,作者来自于香港理工大学 — 李嫣然。
Abstract
在目前的NLP各项任务中,词向量已经得到了广泛的应用并取得了很好的效果,然而大多数是对于英文等西方语言,对于中文,由于中文汉字包含了巨大的信息,在中文词向量的工作中有很大的提升,这篇论文认为汉字的组件(部首)包含了大量的语义信息,基于此提出了两个词向量模型,对中文字向量进行了改善,实验结果表明在文本分类已经词相似度上都得到了提升。
Model
模型结构图如下,具体做法是抽取每个汉字的组件组成一个component列表(可以从在线新华词典获取component列表),部首信息要比其他的组件信息包含更加丰富的语义信息,所以,把部首放在了component列表的首位进行训练,下图中的E代表的就是component列表,C代表的是上下文词, Z代表的是目标词。
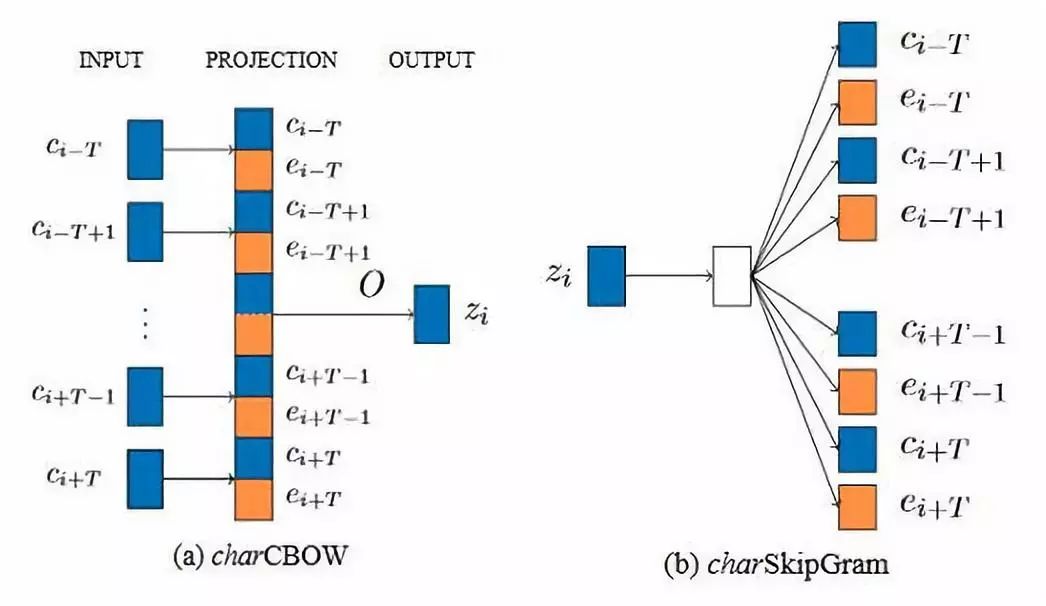
具体做法,以charCBOW为例,charCBOW是在原始的CBOW的基础之上进行的改善,把E和C进行cat连接作为特征。
也提供了一些部首信息,如下图

Experiment Result
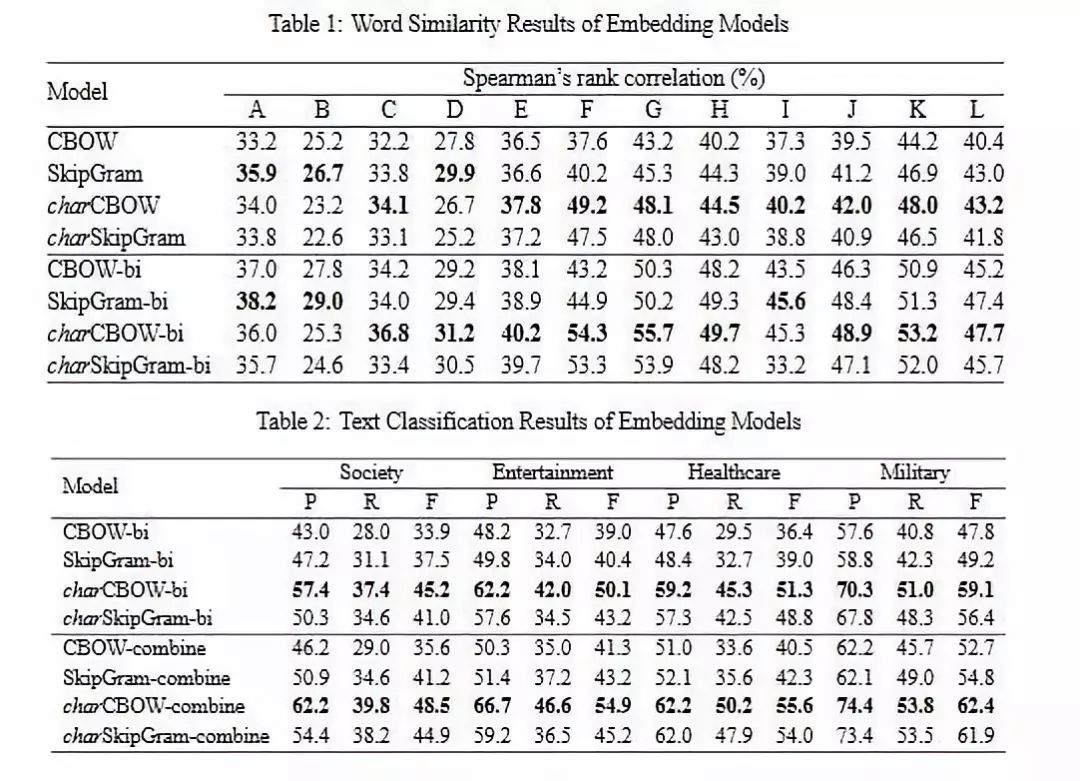
在Word Similarity 和 Text Classification 上面进行了实验,对于Word Similarity任务,可以参考以前写的一篇文章 — 中英文词向量评测。
Word Similarity采用的评估文件大多数都是基于英文构建的,像 WS-353,RG-65等,对于中文来说,仅有HowNet和 E-TC(哈工大词林),由于HowNet包含较少的现代词,选择采用E-TC进行评测;Text Classification 选择的数据集是腾讯新闻(Tencent news datasets),在Word Similarity 和 Text Classification上面都验证了论点。下图是实验结果。
论文来源
这是一篇2015年发表在IJCAI (International Joint Conference on Artificial Intelligence)会议上的论文,作者来自于清华大学 — 陈新雄,徐磊。
Abstract
目前,大多数词向量的建模方法都是基于词的,而在中文词语包含多个汉字,并且每个汉字都包含了大量丰富的信息,一个词的语义信息也是与组成它的汉字有很深的关联,比如,智能 這个词,智 和 能 也能够表达一部分其语义,基于這个思想,论文提出了训练中文词向量新的方法,使用汉字来增强词的效果(CWE)。
但是训练CWE存在一些问题,像单个汉字可能存在多种意义,有些汉字组成的词,其中的汉字分开时没有意义的等一些问题,文中提出了 multiple-prototype character embedding 和 an effective word selection method 分别来解决问题。在 Word Relatedness Computation 和 Analogical Reasoning任务上验证了其有效性。
Model
Character-Enhanced Word Embedding
CWE是在CBOW的基础之上进行的改进,CWE和CBOW的模型结构图如下图所示。
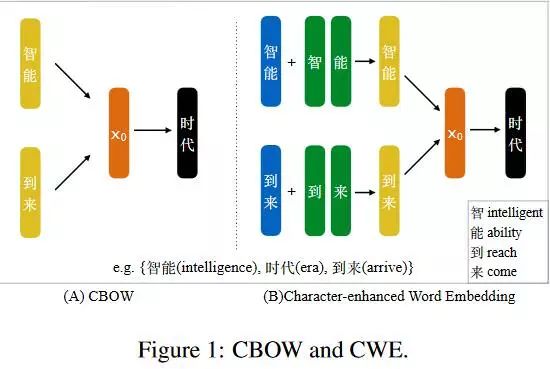
像上图表示的一样,词由词和组成它的字联合表示,具体表示是下面的公式, w代表word embedding,c代表的是character embedding,N代表一个词有多少字组成,有两种联合方式,一种是 addition ,一种是 concatenation。
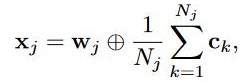
在实验过程中发现 addition 要优于 concatenation,后续实验过程中都采用addition的联合方式,并且对公式进行了简化,在上个公式基础之上,取词和字的平均,如下图。
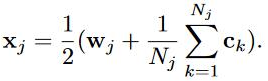
CWE的核心思想是把CBOW中的词替换成词和字的联合表示,但是仍然和CBOW共用相同的目标函数,這样做的一个好处在于,即使词没有出现在上下文的窗口之中,word embedding也会根据character embedding进行调整,完善了CBOW的這个缺点。
Multiple-Prototype Character Embeddings
由于有些中文汉字存在很大的歧义性,在CWE模型中可能会带来消极的影响,为了解决汉字的歧义性问题,提出了Multiple-Prototype Character Embeddings,核心的思想是一个汉字使用多个character embedding表示,具体的又提出了三种方案,Position-based character embeddings,Cluster-based character embeddings,Nonparametric cluster-based character embeddings。下面简单的看一下這三种方案。
1. Position-based character embeddings 在一个词的内部,字的位置有很大的作用,不同的位置表达不同的意思,這个方案里面,保持单字三个不同的位置embedding,分别是B---Begin,M---Middle,E---End,如下图所示。
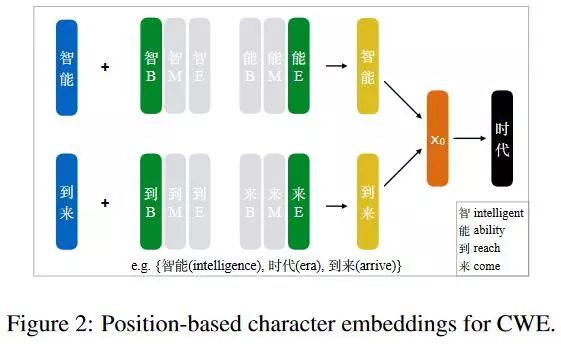
和CWE最初的方式差不多,不同在于character embedding的表示采用了BME的平均,具体如下。
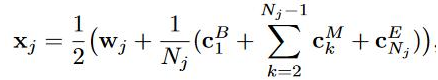
2. Cluster-based character embeddings 根据2012年Huang的一篇论文(multiple-prototype word embeddings)提出的一个方法,提出了Cluster-based character embeddings的方法,对 character 所有出现的情况做聚类, 为每个聚类分配一个向量,具体的如下图。
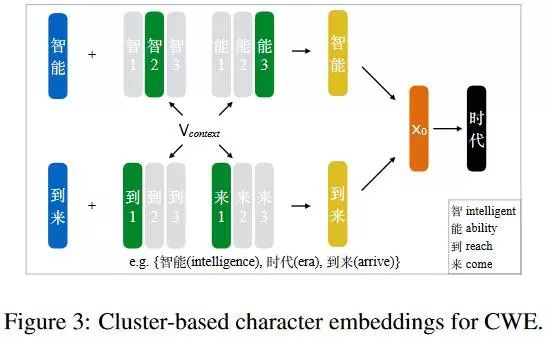
這时候词的表示如下图
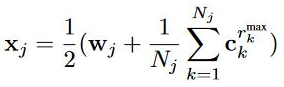
其中r_max是计算余弦相似度(S),计算公式如下
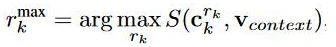
v_context如下,其中c_most代表的是在聚类中最频繁被选择的。
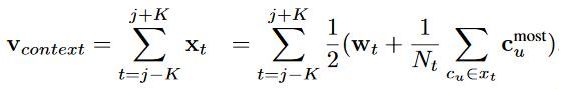
3. Nonparametric cluster-based character embeddings Cluster-based character embeddings具有固定的类数, 而无参聚类方法能分配不同的数量, 在训练的时候学习,非常灵活。
Word Selection for Learning
中文词语中,有很多的字并不能够表示其语义信息,这些包括以下几个方面。
1. 像徘徊,琵琶這样的词语,其中的单字很难在其他的词语中使用。
2. 音译过来的一些词,像沙发(sofa),巧克力(chocolate) 主要是语音合成。
3. 一些实体的名字,像人名,地名,组织机构名等。
为了去解决這样的问题,提出在学习這些词的时候,不要去考虑其character,具体的做法是手工构建這样的词表来处理。
Experiment Result
在 Word Relatedness Computation 和 Analogical Reasoning任务上验证了其有效性,对于這两个任务,可以参考以前写的一篇文章 — 中英文词向量评测。
1. Word Relatedness Computation 采用的评测数据是 wordsim-240,wordsim-296,以下是评测结果。
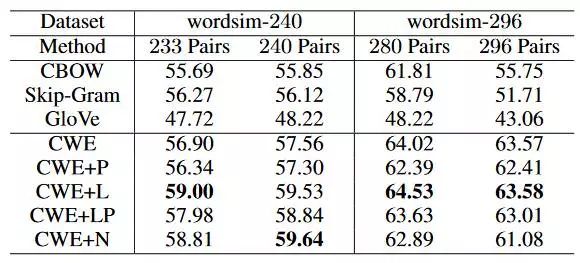
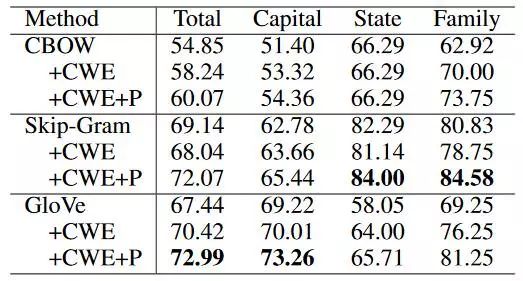
2. 对于Analogical Reasoning,由于没有中文的评测数据,手工构建了一份数据集,并且這个数据集在后续的中文词向量评测中被广泛使用。
[1] Component-Enhanced Chinese Character Embeddings
[2] Joint Learning of Character and Word Embeddings


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流




