如何训练你的ResNet(一):复现baseline,将训练时间从6分钟缩短至297秒
在这一系列文章中,我们主要研究如何用单独的GPU,在CIFAR-10图像分类数据集上高效地训练残差网络(Residual networks)。
为了记录这一过程,我们计算了网络从零开始训练到94%的精确度所需的时间。这一基准来自最近的DAWNBench竞赛。在竞赛结束后,单个GPU上的最好成绩是341秒,八个GPU上最好成绩是174秒。
Baseline
在这部分中,我们复制了一个基线,在6分钟内训练CIFAR10,之后稍稍加速。我们发现,在GPU的FLOPs计算完之前,仍有很大的提升空间。
过去几个月,我一直在研究如何能更快度训练深度神经网络。这个想法是从今年年初萌生的,当时我正和Myrtle的Sam Davis进行一个项目。我们将用于自动语音识别的大型循环神经网络压缩后,部署到FPGAs上,重新训练模型。来自Mozilla的基线在16个GPU上训练了一个星期。后来,经过Sam的努力,我们在英伟达的Volta GPUs上进行混淆精度训练,得以将训练时间缩短了100倍,迭代时间在单个GPU上只需要不到一天的时间。
这一结果让我思考还有什么可以实现加速?几乎与此同时,斯坦福大学的研究人员们开启了DAWNBench挑战赛,比较多个深度学习基线上的训练速度。最受人关注的就是训练图像分类模型在CIFAR10上达到94%的测试精确度,在ImageNet上达到93%、top5的成绩。图像分类是深度学习研究的热门领域,但是训练速度仍需要数小时。
到了四月份,挑战赛接近尾声,CIFAR10上最快的单个GPU训练速度来自fast.ai的一名学生Ben Johnson,他在不到6分钟(341秒)的时间里训练出了94%的精确度。这一创新主要是混淆精度的训练,他选择了一个较小的网络,有足够的能力处理任务并且可以用更高的学习速率加速随机梯度下降。
这时我们不禁提出一个问题:这种341秒训练出来的94%测试精度,在CIFAR10上的表现怎么样?该网络的架构是一个18层的残差网络,如下所示。在这个案例中,图层的数量表示卷积(紫色)和完全连接层(蓝色)的序列深度:

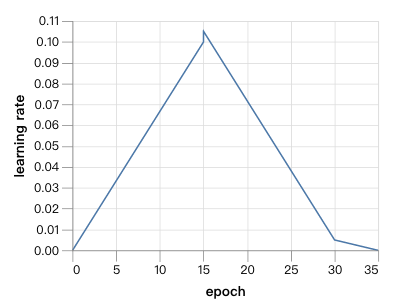
网络通过随机梯度下降训练了35个epoch,学习速率图如下:
现在我们假设在一个英伟达Volta V100 GPU上用100%的计算力,训练将需要多长时间。网络在一张32×32×3的CIFAR10图像上进行前向和后向传递时需要大约2.8×109FLOPs。假设参数更新不耗费计算力,那么在50000张图像训练35个epoch应该会在5×1015FLOPs以内完成。
Tesla V100有640个Tensor Cores,能支持125 TeraFLOPS的深度学习性能。
假设我们能发挥100%的计算力,那么训练会在40秒内完成,这么看来341秒的成绩还有很大的提升空间。
有了40秒这个目标,我们就开始了自己的训练。首先是用上方的残差网络重新复现基线CIFAR10的结果。我用PyTorch创建了一个网络,重新复制了学习速率和超参数。在AWS p3.2的图像上用单个V100 GPU训练,3/5的运行结果在356秒内达到了94%的精确度。
基线建好后,下一步是寻找可以立即使用的简单改进方法。首先我们观察到:网络开头是由黄色和红色的两个连续norm-ReLU组成的,在紫色卷积之后,我们删去重复部分,同样在epoch 15也发生了这样的情况。进行调整后,网络架构变得更简单,4/5的运行结果在323秒内达到了94%的精确度!刷新了记录!
另外我们还观察到,图像处理过程中的一些步骤(填充、标准化、位移等等)每经过训练集一次就要重新处理一遍,会浪费很多时间。虽然提前预处理可以用多个CPU处理器减轻这一结果,但是PyTorch的数据下载器会从每次数据迭代中开始新一次的处理。这一配置时间是很短的,尤其在CIFAR10这样的小数据集上。只要在训练前做了准备,减少预处理压力,就能减少处理次数。遇到更复杂的任务,需要更多预处理步骤或多个GPU时,就会在每个epoch之间保持数据下载器的处理。溢出了重复工作、减少了数据下载器后,训练时间达到了308秒。
继续研究后我们发现,大部分预处理时间都花在了召集随机数字生成器,选择数据增强而不是为它们本身增强。在完全训练时期,我们对随机数字生成器执行了几百万个单独命令,把它们结合在一个较小的命令中,每个epoch可以省去7秒训练时间。最终的训练时间缩短到了297秒。这一过程的代码可以点击:github.com/davidcpage/cifar10-fast/blob/master/experiments.ipynb
在下一篇文章中,我们将提高batch的大小,训练时间将会进一步缩短,敬请期待!
原文地址:www.myrtle.ai/2018/09/24/howtotrainyourresnet_1

星标论智,每天获取最新资讯