由于硬件资源有限,深度学习模型的训练目标通常是在训练和推理的时间和内存限制下最大化准确性。在这种情况下,我们研究了模型大小的影响,关注于计算受限的NLP任务的Transformer模型:自监督的预训练和高资源机器翻译。我们首先展示了,尽管较小的Transformer模型在每次迭代中执行得更快,但更广、更深入的模型在显著更少的步骤中收敛。此外,这种收敛速度通常超过了使用更大模型的额外计算开销。因此,计算效率最高的训练策略是反直觉地训练非常大的模型,但在少量迭代后停止。

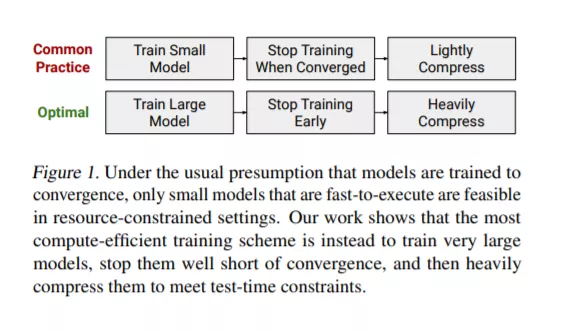
这导致了大型Transformer 模型的训练效率和小型Transformer 模型的推理效率之间的明显权衡。然而,我们表明大模型比小模型在压缩技术(如量化和剪枝)方面更健壮。因此,一个人可以得到最好的两个好处: 重压缩,大模型比轻压缩,小模型获得更高的准确度。
https://www.zhuanzhi.ai/paper/4d7bcea8653fcc448137766511ec7d8a
概述:
在当前的深度学习范式中,使用更多的计算(例如,增加模型大小、数据集大小或训练步骤)通常会导致更高的模型准确度(brock2018large;raffel2019exploring)。最近自监督预训练的成功进一步论证了这种趋势经模型。因此,计算资源日益成为提高模型准确度的关键制约因素。这个约束导致模型训练的(通常是隐含的)目标是最大化计算效率:如何在固定的硬件和训练时间下达到最高的模型准确度。
最大化计算效率需要重新考虑关于模型训练的常见假设。特别是,有一个典型的隐式假设,即模型必须经过训练直到收敛,这使得较大的模型在有限的计算预算下显得不太可行。我们通过展示以收敛为代价来增加模型大小的机会来挑战这一假设。具体地说,我们表明,训练Transformer 模型的最快方法(vaswani2017attention)是大幅度增加模型大小,但很早停止训练。
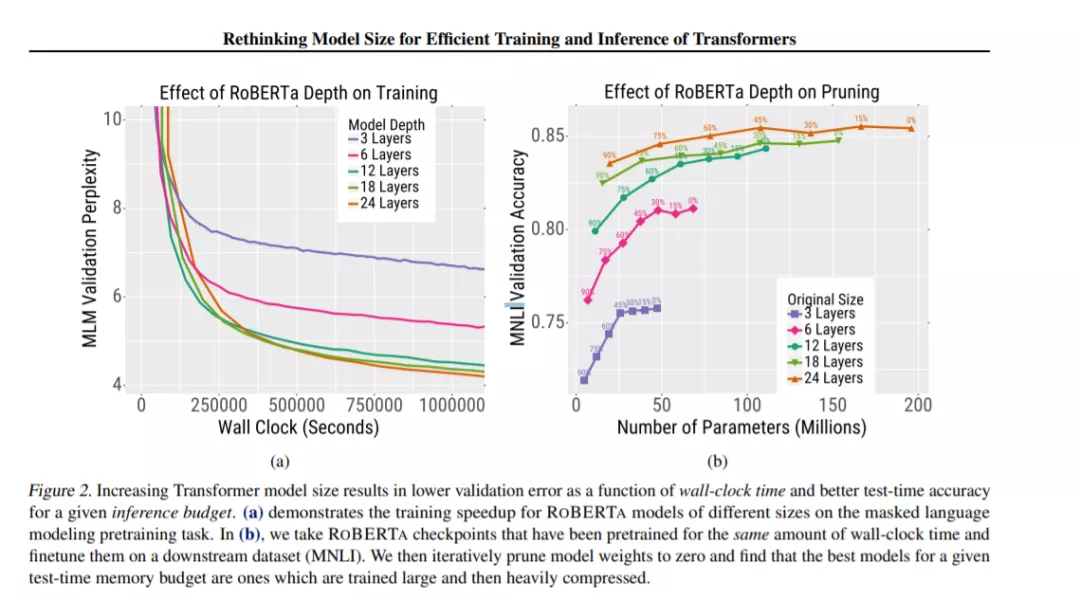
在我们的实验中,我们改变了Transformer模型的宽度和深度,并在自监督的预训练(RoBERTa (liu2019roberta)在Wikipedia和BookCorpus上训练)和机器翻译(WMT14英语→法语)上评估了它们的训练时间和准确性。对于这些任务,我们首先展示了更大的模型比更小的模型在更少的梯度更新中收敛到更低的验证错误(第3节)。此外,这种收敛速度的增加超过了使用更大模型所带来的额外计算开销——计算效率最高的模型是非常大的,并且远远不能收敛(例如,图2,左)。我们还表明,收敛的加速主要是参数计数的函数,只有模型宽度、深度和批大小的微弱影响。
虽然较大的模型训练速度更快,但它们也增加了推理的计算和内存需求。这种增加的成本在现实应用中尤其成问题,推理成本占训练成本的主要比例(jouppi2017datacenter;crankshaw2017clipper;metz2017tpu)。然而,对于RoBERTa来说,这种明显的权衡可以与压缩相协调:与小型模型相比,大型模型在压缩方面更加健壮(第4节)。因此,使用可比较的推理成本,大型重压缩的模型优于小型轻压缩的模型(例如,图2,右)。