![]()
公交车、出租车等交通工具的到达时间是影响公众出行的一大因素。所以,预估到达时间(ETA)准确率成为非常实际的研究课题。近日,DeepMind 与谷歌地图展开合作,利用图神经网络等 ML 技术,极大了提升了柏林、东京、悉尼等大城市的实时 ETA 准确率。
![]()
很多人使用谷歌地图(Google Maps)获取精确的交通预测和预估到达时间(Estimated Time of Arrival,ETA)。这是很重要的工具,尤其是当你将途经交通拥堵路段或者需要按时参加重要的会议。
此外,对于拼车服务公司等企业而言,这些功能也很有用。它们使用 Google Maps 平台获取接送时间信息并基于乘车时间估计价格。
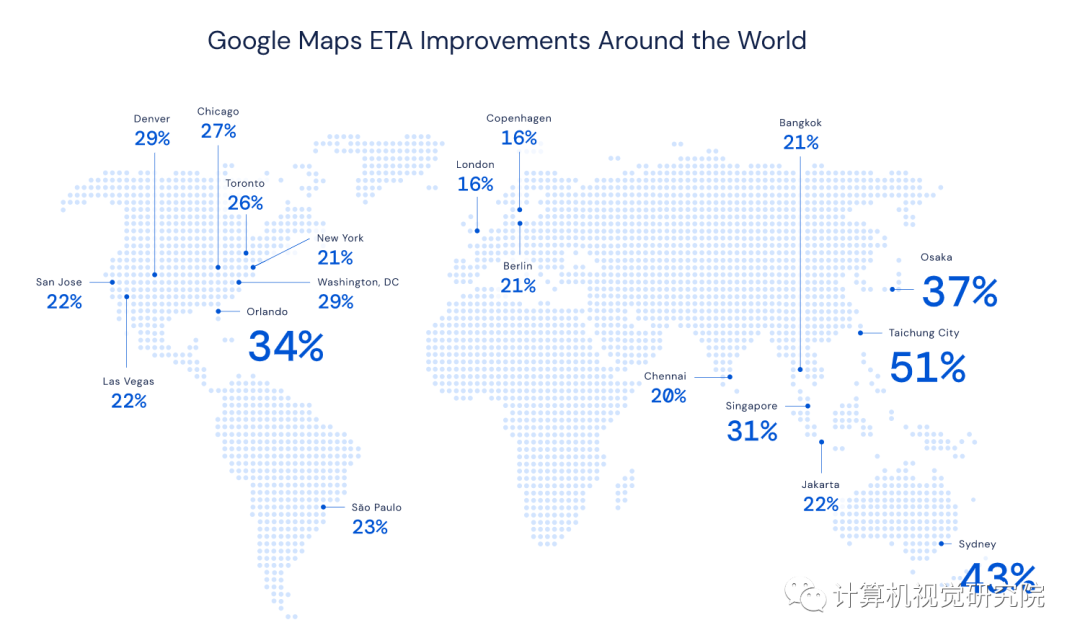
DeepMind 研究者与 Google Maps 团队展开合作,尝试通过图神经网络等高级机器学习技术,提升柏林、雅加达、圣保罗、悉尼、东京和华盛顿哥伦比亚特区等地的实时 ETA 准确率,最高提升了 50%。下图为这些城市的 ETA 提升率:
一、Google Maps 如何预测 ETA
为了计算 ETA,Google Maps 分析了世界各地不同路段的实时交通数据。这些数据为 Google Maps 提供了目前交通状况的精确图景,但是它却无法帮助司机预计车程时间是 10 分钟、20 分钟,还是 50 分钟。
所以,为了精确地预测未来交通状况,Google Maps 使用机器学习将全球道路的实时交通状况和历史交通模式结合起来。这一过程非常复杂,原因很多。例如,早晚高峰每天都会有,但每一天、每一月的高峰期确切时间有很大不同。道路质量、限速、交通事故等因素也增加了交通预测模型的复杂度。
DeepMind 团队与 Google Maps 合作尝试提升 ETA 准确率。Google Maps 对超过 97% 的行程有着精确的 ETA 预测,DeepMind 与 Google Maps 的合作目的是将剩下那些预测不准确的情况最小化,例如台中(Taichung)的 ETA 预测准确率提升了 50% 多。
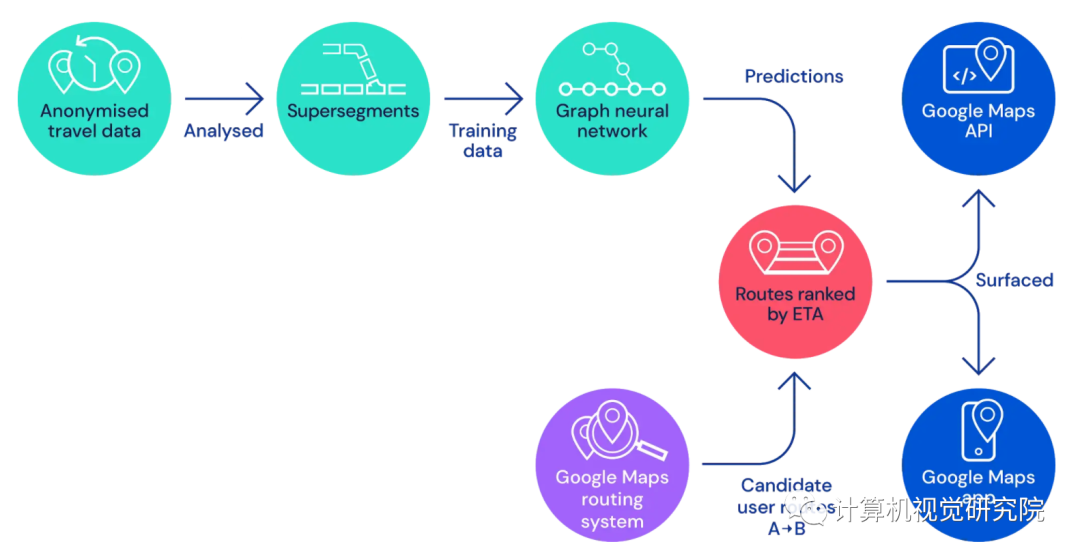
为了在全球范围内实现这一目的,DeepMind 利用了一种通用机器学习架构——图神经网络(GNN),通过向模型添加关系学习偏置来进行时空推理,进而建模现实世界道路网络的连通性。
具体步骤如下:
将世界上的道路分割为超级路段(Supersegment)
该团队将道路网络分割为包含多个邻近路段的「超级路段」,超级路段都具有极大的交通流量。目前,Google Maps 交通预测系统包括以下组件:
路线分析器:具备数 TB 的交通信息,可用于构建超级路段;
新型 GNN 模型:使用多个目标函数进行优化,能够预测每个超级路段的行程时间。
Google Maps 确定最优路线和行程时间的模型架构图示
利用超级路段创建估计行程时间的机器学习系统,所面临的最大挑战是架构问题。如何以任意准确率表示连接路段的规模可变样本,进而保证单个模型也能预测成功?
DeepMind 团队最初的概念证明始于一种简单明了的方法,该方法尽可能地利用现有的交通系统,特别是已有的路网分割和相关的实时数据 pipeline。这意味着超级路段覆盖了一组路段,其中每个路段都有特定的长度和相应的速度特征。
首先,该团队为每个超级路段训练了一个全连接神经网络模型。初步结果良好,表明神经网络在预测行程时间方面是很有潜力的。但是,鉴于超级路段的可变规模,该团队需要为每个超级路段单独训练神经网络模型。要想实现大规模部署,则必须训练数百万个这样的模型,这就对基础设施构成了巨大的挑战。
因此,该团队开始研究能够处理可变长度序列的模型,例如循环神经网络(RNN)。但是,向 RNN 添加来自道路网络的结构是很难的。于是,研究者决定使用图神经网络。在对交通情况进行建模时,车辆如何穿过道路网络是该研究的关注点,而图神经网络可以对网络动态和信息传播进行建模。
该团队提出的模型将局部道路网络视为一个图,其中每个路段对应一个节点,连接两个路段(节点)的边要么在同一条道路上,要么通过交叉点(路口)连接。在图神经网络中执行消息传递算法时,其传递的消息及其对边和节点状态的影响均由神经网络学得。从这个角度看,超级路段是根据交通密度随机采样的道路子图。因此,使用这些采样的子图能够训练单个模型,且单个模型可以进行大规模部署。
图神经网络通过泛化「相似度(proximity)」概念,扩展了
卷积神经网络
和循环神经网络所施加的学习偏置(learning bias),进而具备任意复杂度的连接,不仅可以处理道路前后方的交通情况,还可以处理相邻和相交道路的情况。在图神经网络中,相邻节点之间互相传递消息。在保持这种结构的情况下,研究者施加了局部偏置,节点将更容易依赖于相邻节点(这仅需要一个消息传递步)。这些机制使图神经网络可以更高效地利用道路网络的连通性结构。
实验表明,将考虑范围扩展到不属于主要道路的相邻道路能够提高预测能力。例如,考虑小路上的拥堵状况对大路交通情况的影响。通过跨越多个交叉路口,该模型能够预测转弯处的延误、并道引起的延误,以及走走停停交通状况的通行时间。图神经网络在组合空间上的泛化能力使得该研究的建模技术具备强大能力。
每个超级路段的长度和复杂度可能各有不同(从简单的两段路到包含了数百个节点的较长路径),但它们都可以使用同一个图神经网络模型进行处理。
在学术研究中,生产级机器学习系统存在一个常常被忽视的巨大挑战,即同一模型在多次训练运行中会出现巨大的差异。虽然在很多学术研究中,细微的训练质量差别可以简单地作为 poor 初始化被丢弃,但数百万用户的细微不一致累加在一起就会产生极大的影响。
因此,在将该模型投入生产时,图神经网络对训练中这种变化的鲁棒性就成为了重中之重。研究者发现,图神经网络对训练过程中的变化特别敏感,造成这种不稳定性的原因是训练中使用的图结构之间存在巨大差异。单批次图可以涵盖从两节点小图到 100 节点以上的大图。
然而,在反复试错之后,研究者在有监督设置下采用了一种新型强化学习
技术,解决了以上问题。
在训练机器学习系统的过程中,系统的学习率决定了自身对新信息的「可塑性」。随着时间推移,研究人员常常会降低模型的学习率,这是因为学习新东西和忘记已经学得的重要特征之间存在着权衡,就像人类从儿童到成人的成长历程一样。
所以,在预定义训练阶段之后,研究者首先采用一种指数衰减学习率计划来稳定参数。此外,研究者还探究和分析了以往研究中被证明有效的模型集成技术,从而观察是否可以减少训练运行中的模型差异。
最后,研究者发现,最成功的解决方案是使用 MetaGradient 来动态调整训练期间的学习率,从而可以有效地使系统学得自身最优的学习率计划。通过在训练期间自动地调整学习率,该模型不仅实现了较以往更高的质量,而且还学会了自动降低学习率。最终实现了更稳定的结果,使得该新型架构能够应用于生产。
虽然建模系统的最终目标是减少行程预估中的误差,但是研究者发现,利用多个损失函数
(适当加权)的线性组合极大地提升了模型的泛化能力。具体而言,研究者利用模型权重的正则化
因子、全局遍历时间上的 L_2 和 L_1 损失、以及图中每个节点的 Huber 和负对数似然(negative-log likelihood, NLL)损失,制定了一个多损失目标。
通过结合这些损失,研究者能够指导模型并避免训练数据集的过拟合
。虽然对训练过程的质量衡量标准并没有变化,但是训练中出现的提升更直接地转化到留出(held-out)测试集和端到端实验中。
目前,研究者正在探究,在以减少行程估计误差为指导指标的情况下,MetaGradient 技术是否也可以用来改变训练过程中多成分损失函数
的构成。这项研究受到先前在强化学习
中取得成功的 MetaGradient 的启发,并且早期实验也显示出了不错的结果。
参考内容:https://deepmind.com/blog/article/traffic-prediction-with-advanced-graph-neural-networks
我们开创“
计算机视觉协会
”知识星球一年有余,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。
![]()
如果想加入我们“
计算机视觉研究院
”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”
研究
“。之后我们会针对相应领域分享实践过程,让大家真正体会
摆脱理论
的真实场景,培养爱动手编程爱动脑思考的习惯!