2020 年 8 月 7 日,由中国计算机学会(CCF)主办的第五届全球人工智能与机器人峰会(CCF-GAIR 2020)在深圳正式开幕。
在本次大会第二天的「视觉智能•城市物联」专场上,微软亚洲研究院首席研究员王井东博士分享了其在新一代视觉识别网络结构上的研究成果。
他介绍,目前学界的网络结构都是围绕分类任务而发明,除了分类以外,在计算机视觉里面还有其它的重要任务,比如图像分割、人脸关键点的检测、人体姿态估计、目标检测等等。
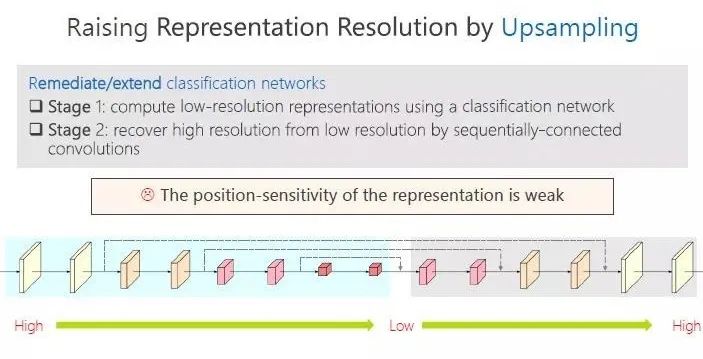
王井东博士首先分享了分类网络结构学习高分辨率表征的方式,是通过上采样的方法。包括两个步骤,第一个步骤是分类的网络架构,表征空间尺度开始比较大,然后慢慢变小;第二个步骤,通过上采样的方法逐步从低分辨率恢复高分辨率。这样的方法获得的特征空间精度较弱。
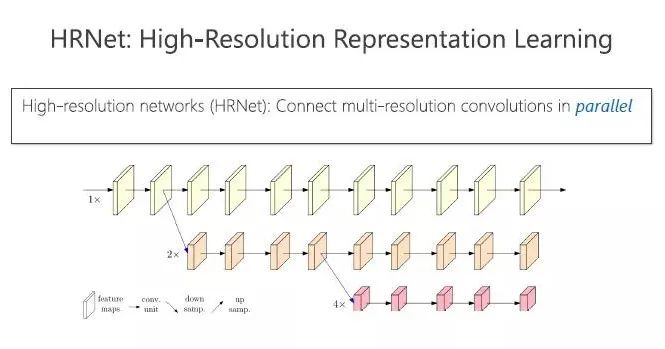
而王井东团队研发的高分辨率网络架构(HRNet)没有沿用以前的分类架构,也不是从低分辨率恢复到高分辨率,自始至终维持高分辨率。
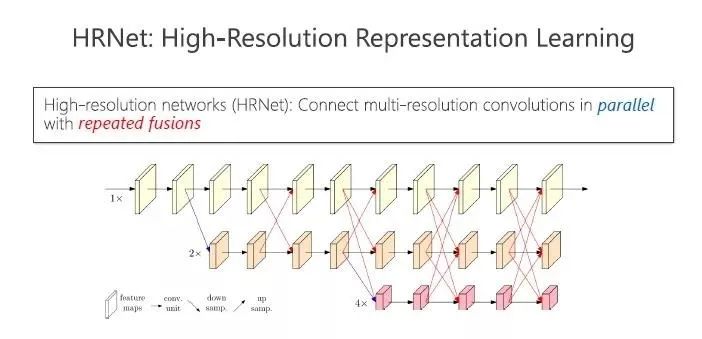
他们让高中低分辨率不停地交互,使得高分辨率可以拿到低分辨率语义性比较强的表征,低分辨率可以拿到高分辨率的空间精度比较强的表征,不停地融合,最终取得更强的高分辨率表征。
在人体姿态、分割、人脸关键点检测、目标检测等任务中,HRNet 从参数量、计算量以及最终结果看,高分辨率结构都非常有优势。HRNet 在人体姿态估计的任务上,已经成为标准的方法;在分割任务上,由于其更好的性能,也被大家广泛使用。
以下是王井东博士大会现场全部演讲内容:
注: 完整版演讲 PPT 可点击阅读原文获取。
非常荣幸能够在这里跟大家分享我们的工作,今天我报告的题目是“高分辨率网络,一种面向视觉识别的通用网络结构”。
在计算机视觉里面,视觉识别是一个非常重要的领域,这里面我列举了几种代表性的研究课题:图像分类、目标检测、图像分割、人脸关键点的检测和人体关键点的检测。
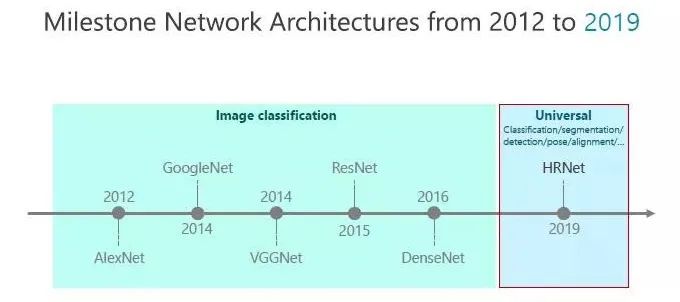
从2012年以来,随着 AlexNet 横空出世,深度神经网络在计算机视觉领域成为主流的方法。2014年,谷歌发明出了 GoogleNet,牛津大学发明了 VGGNet,2015年微软发明了 ResNet,2016年康奈尔大学和清华大学发明了 DenseNet,以上都是围绕分类任务而发明的网络结构。
除了分类以外,在计算机视觉里面还有其它的任务,比如说图像分割、人脸关键点的检测、人体姿态估计等等。
下一代的网络结构是什么样的?是否适用于更为广泛的视觉识别问题?
在解答这些问题之前,我们先了解分类网络、我们为什么提出这样的问题,以及现在的分类网络存在的问题。
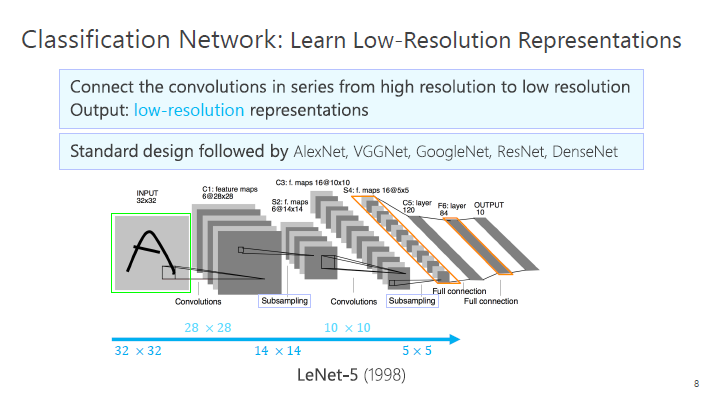
LeNet-5 分类网络是1998年发明的一种网络结构(如上图),包括一系列减小空间大小的过程,具体来讲就是把空间从大的特征变成小的特征,然后通过变换的向量,最后进行分类。
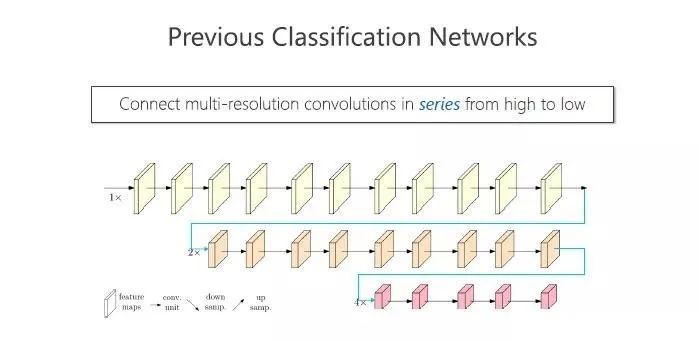
前面提到的几个结构,包括 GoogleNex、VGGNet、ResNet 等等,都是通过这种方式,逐步减小空间的大小,最终得到一个低分辨率的表征。低分辨率的表征在图像分类任务中是足够的,因为在图像分类里面,只需要给一个全局的标签,而不需要详细的空间信息,我们称之为空间粗粒表征的学习。
但是在其它任务中,比如检测,我们需要知道检测框的空间位置,比如分割,我们需要每个像素的标签,在人脸和人体的关键点的检测中,我们需要关键点的空间位置,这样一系列的任务实际上需要空间精度比较高的表征,我们称之为高分辨率表征。
目前业内学习高分辨率表征有几个原则,一般是以分类的网络架构作为主干网络,在此基础上学习一些高分辨率的表征。
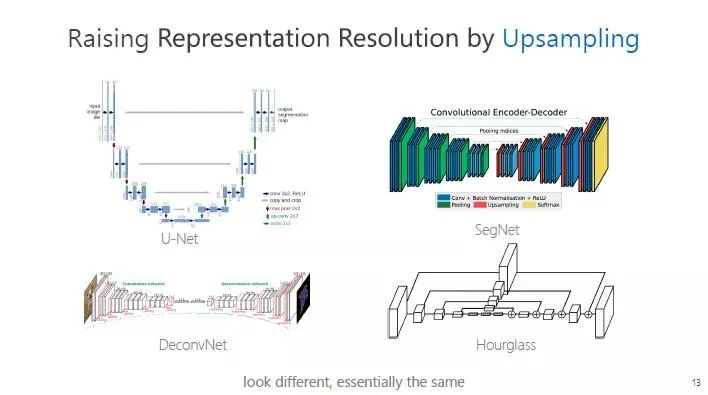
学习高分辨率表征,有一种叫上采样的方法。包括两个步骤,第一个步骤是分类的网络架构,表征开始比较大,然后慢慢变小;第二个步骤,通过上采样的方法逐步从低分辨率恢复高分辨率。
常见的网络架构,比如 U-Net,主要应用在医学图像,SegNet 主要是用于计算机视觉领域,这几个结构看起来很不同,其实本质都一样。
如此一来,分辨率开始高,然后降低了,然后升高。在这个过程中,先失去了空间精度,然后慢慢恢复,最终学到的特征空间精度较弱。
为了解决这个问题,我们提出了一种新型的高分辨率表征学习方法,简称为 HRNet。HRNet 可以解决前面提到的从 AlexNet 到 DenseNet 都存在的问题,我们认为下一个网络结构是 HRNet。
HRNet 与以前的网络结构不同,它不是从分类任务出发,它可以解决更广泛的计算机视觉问题。
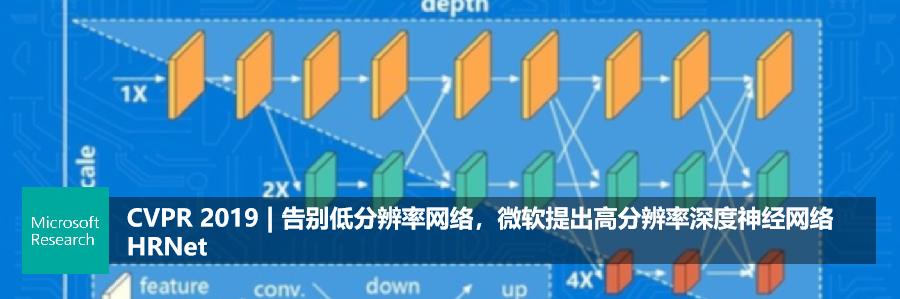
我们的目的是学习一个空间精度强的表征,我们设计的 HRNet 不是沿用以前的分类结构,也不是从低分辨率恢复到高分辨率,而是从零开始,自始至终都维持高分辨率,可以学到空间分辨率较强的表征。
这个结构是如何设计?作为对比,我们先分析分类的网络结构原理。
在下图的例子里,有高分辨率的卷积(箭头代表卷积等的计算操作,这些框是表征),有中等分辨率的卷积,最终得到低分辨率的表征。
分类网络中,这三路是串联的,现在我们把这三路并联,最终拿到一个高分辨率的表征。
大家也许会有疑问,三路是独立的,除了输入的相关联之外,其它的都不产生关系,这样会损失什么?在低分辨率方面,它可以学习到很好的语义信息,在高分辨率里,它的空间精度非常强,这三路之间的信息没有形成互补。
我们采用的方法,是让三路不停地交互,使得高分辨率可以获得低分辨率语义信息较强的表征,低分辨率可以获得高分辨率的空间精度较强的表征,不停地融合,最终取得更强的高分辨率表征。
简单来讲,以前的高分辨率是通过升高、降低再升高获得,我们通过将不同分辨率的卷积由串联变成并联,自始至终保持高分辨率,并且还加入不同分辨率之间的交互,使得高分辨率表征和低分辨率表征的变强,获得对方的优势特征,最终获得非常强的高分辨率表征。
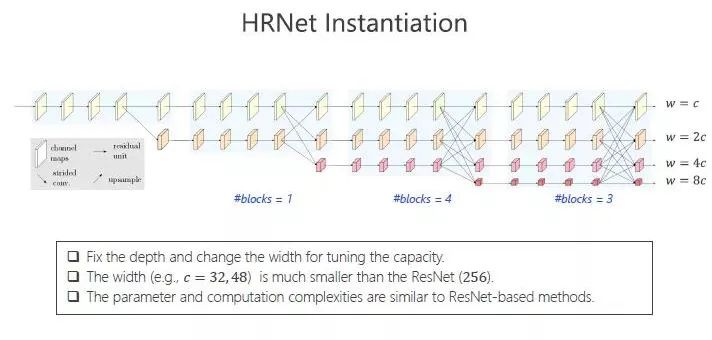
HRNet 实际上固定了它的深度,把这个结构分成若干个模块,每个模块是由若干个可重复的组织设计出来的。比如第三个部分,它由4个模块形成。
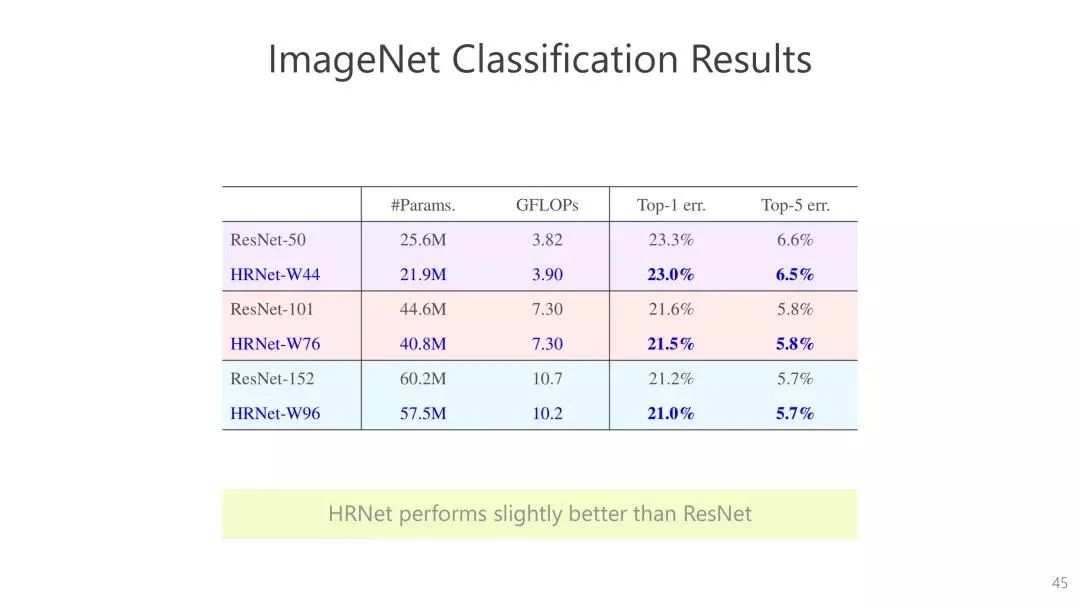
我们采用变化宽度的方式。与 ResNet 比,这个结构中的宽度小很多,比如之前ResNet 的宽度是256,HRNet 的宽度是32-48。正因为这样的设计,我们最终得到的参数和计算复杂度与 ResNet 的结果是可比的。
人体姿态估计中,每个图片中人数很多,我们的任务是要找出每个人的关键点,并区分不同人的关键点。
做法有两种,一种是自上而下(Top-Down),首先使用一种检测器,把人检测出来,然后每个人单独做关键点的检测。另外一种是自下而上(Bottom-Up),直接检测关键点,然后进行一些聚类的操作,把不同人再分开来。
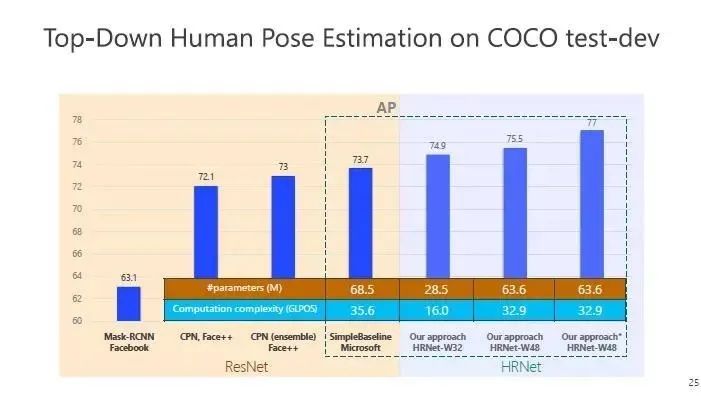
我们看看自上而下的方法的结果,下图左边是基于 ResNet 的方法,右边是 HRNet的方法,比较的指标是关键点位置寻找准确与否。我们的结果是74.9%,结果要好于ResNet,同时参数量上,ResNet 是68.5,我们是28.5。通过进一步加宽 HRNet 网络结构后,可以进一步提高结果。
这个方法自从2019年在 CVPR 发表以来,已经成为在人体姿态构建里一个标准的网络,一些文章或者比赛都会采用 HRNet 架构。
在分割任务中。采用街景分割的例子,街景分割在自动驾驶、无人驾驶、辅助驾驶中都非常重要。
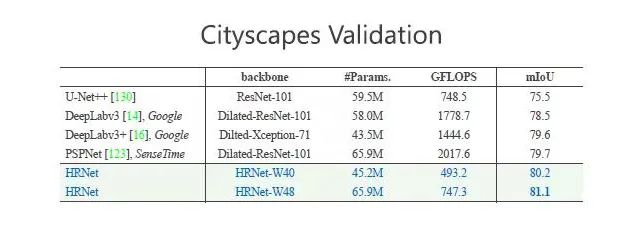
以一个非常重要的数据集 Cityscapes validation 比较,其中,mIoU 是衡量分割好坏的一个非常重要的指标,从下图看到,HRNet-W40 的结果优于其他方法,而体现计算量的 GFLOPS 指标中,HRNet 是三位数,其他方法大多为四位数,HRNet 计算量更小。在参数量、计算量上,HRNet 的过程和最终结果都具有优势,将网络结构规模变大后,优势进一步提高。
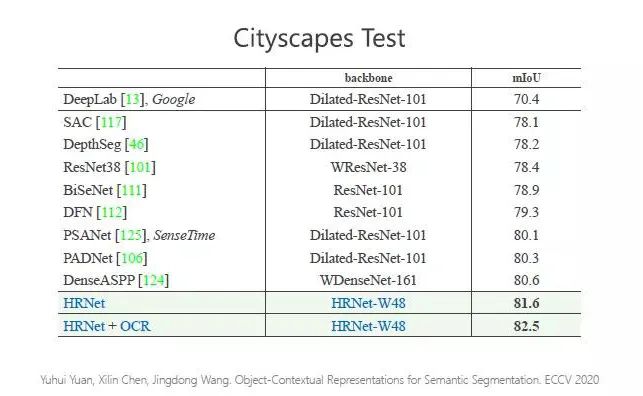
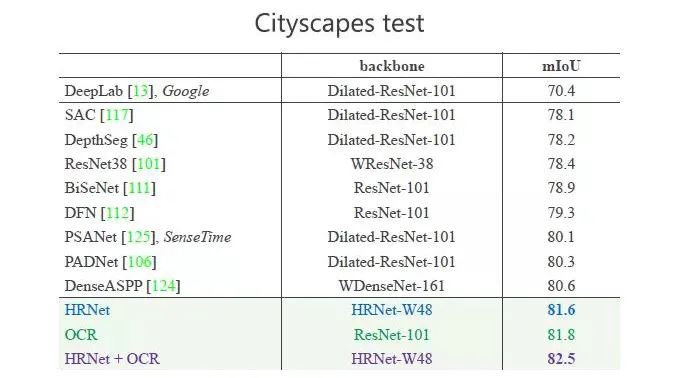
Cityscapes Test 数据集的结果看,HRNet 的表现也是最好的。
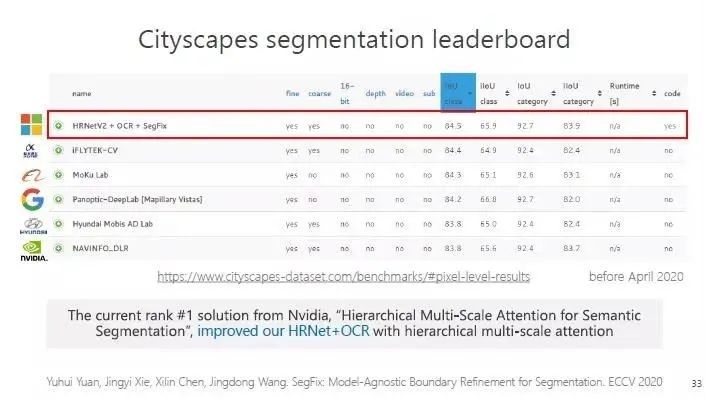
在今年4月份之前,我们在 Cityscapes 分割的榜单中排名第一。5月份,英伟达的一个新方法排名第一,了解过他们的方法后,发现它最终的结果是基于 HRNet,再加上它的模块,从这个角度看,说明 HRNet 的影响力在分割任务上逐步变大。
人脸的关键点检测应用非常多,娱乐、短视频中的美颜功能,都需要人脸关键点的检测,定位出眼睛、鼻子等位置。
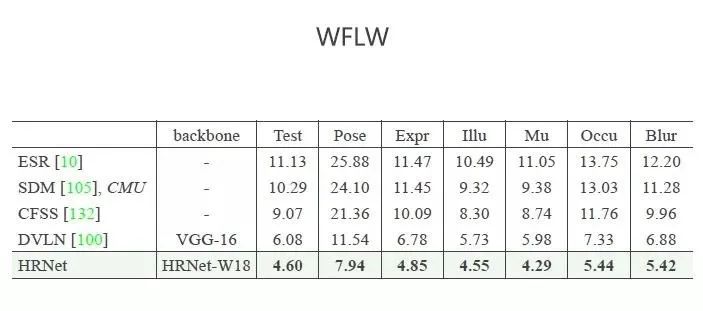
下图展示的是在一个最新数据集上的结果,人脸关键点上有98个点,在测试数据集上,指标衡量的是预测的点与人工标注的点之间的差距,HRNet 的数值比之前的都小,差距最小。除此之外还列出了6种不同复杂条件,比如人脸姿态的变化、表情的变化、光照、是否化妆、是否遮挡,图片清晰程度,一系列的情况下,我们的结果都比以前的方法好。
下面再看我们的方法用在目标检测任务上。我们需要把物体框出来,同时要预测框中的物体种类。
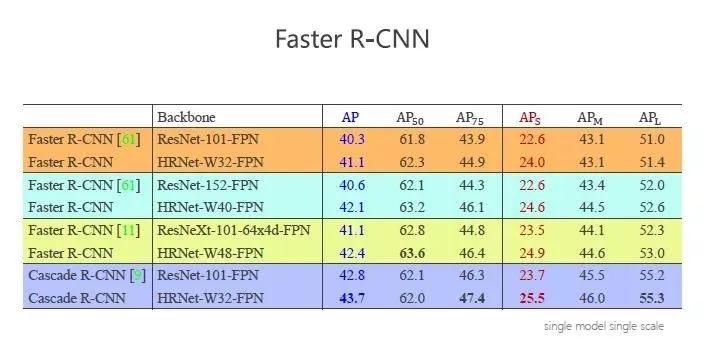
在最流行的 Faster R-CNN 框架里,我们用 HRNet 和 ResNet 的方法进行对比,为保证公平,分成4组,在每组参数量和计算量可比的情况下进行对比。
前三组在 Faster R-CNN 上比较,最后一个在 Cascade R-CNN 上比较,蓝色数值表示预测的整体好坏情况,从结果看,HRNet 都远优于 ResNet。除此以外,HRNet 有非常好的高分辨率表征,在大量存在的小物体上更有优势。
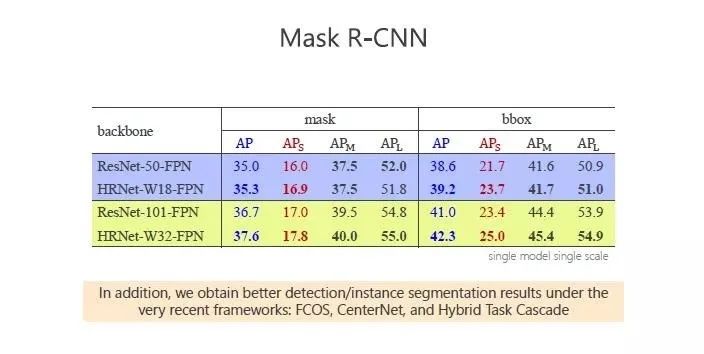
实体分割中 Instance Segmentation,需要表征出物体的轮廓,而不仅仅是一个框,我们在 Mask R-CNN 中和 ResNet 对比,我们的表现有提高,尤其在小物体上体现更加明显。当然,仅仅在 Mask 框架里做不能说明问题,所以我们也在发表的研究论文里列举其他的方法,结果都比 ResNet 的表现好,这里不一一列举。
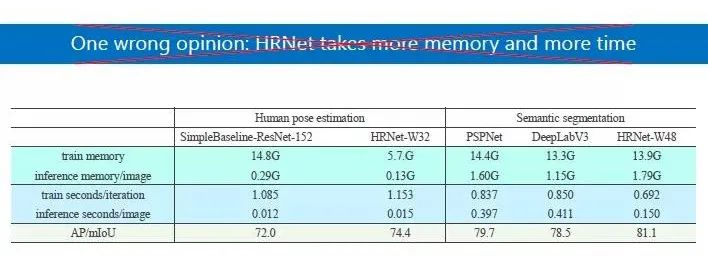
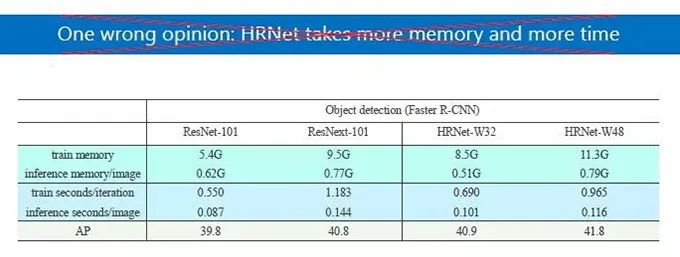
HRNet 出来时,有人怀疑是否其参数量、计算量变大,事实上,我们并没有增加参数量和计算量,或者说增加网络结构的复杂度来提升性能,比如上图中,各项参数中两者计算量差不多,但是结果是 HRNet 更好。
下面我们看看分类。在视觉领域,预训练非常重要,它需要帮网络进行初始化,通过迁移学习应用到其他领域,或者给网络结构做更好的初始化以帮助优化。
当初我们做这个网络结构的目的是为了提出一个高分辨率表征,以帮助分类以外的任务。后来发现,在同等参数量和计算量基础上,HRNet 的结果比 ResNet 好。
2012年以来 AlexNet、GoogleNet、VGGNet、ResNet、DenseNet 等是为了做分类任务,HRNet 除了可以做分类任务,且性能很好,还可以做分割、检测、识别等等各种任务,面部检测、行人的检测、高空图像识别,卫星图象识别,也都有很好的效果。
HRNet 去年10月推出后,被很多比赛的参赛者使用。比如去年 ICCV keypoint and densepose 比赛中,几乎所有参赛选手都使用了 HRNet,谷歌、商汤团队用 HRNet做 panoptic segmentation 和 openimage instance segmentation 比赛,也取得了最好的效果。
最近大家对网络结构搜索了解较多,既然有了搜索,为什么还要有网络结构设计?网络结构设计实际上是为搜索提供了一个空间,这也是非常重要的。今年 CVPR 上的一篇来自谷歌的文章,它的出发点与 HRNet 非常相似,认为以前的网络都是通过空间变大然后变小再恢复,这样对一些识别和检测任务非常不友好,他设计一个 NAS 的算法,来解决这个问题。
网络结构除了以上所述 HRNet 一系列东西之外,还有很多非常重要的研究,比如怎么利用人的常识帮助网络设计,怎么设计轻量化网络,怎么与计算机硬件联系一起。
计算机视觉中,怎么为具体的任务设计网络结构的研究也非常多。我给大家简单介绍一下我们在 ECCV 2020 和 CVPR 2020 的关于 Head Architecture Design 的工作,主要研究如何把人的常识加进设计中。
这里给大家讲一下语义分割,语义分割要预测每个像素点的标签。深度学习在该领域内的应用非常广泛,FCN 是一个标准方法,一个图像经过一个网络结构,最后预测像素点的标签。由于每个像素点本身没有标签,它的标签来自对周围信息的判断,所以通常会加上上下文的信息。
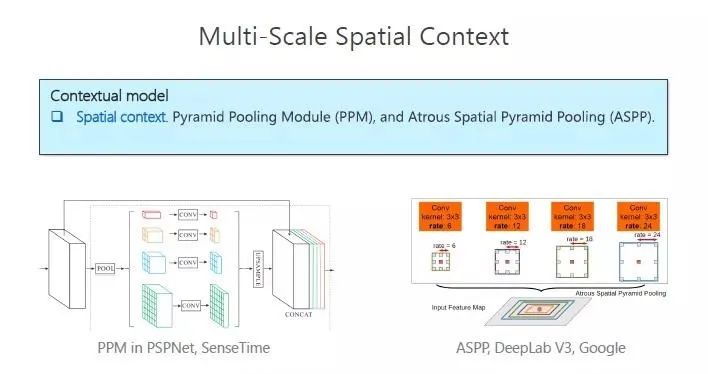
以前的方法主要是 Spatial context(空间上下文)比如有 PPM、ASPP,它是在像素点周围有规律地选出一些像素点,以求得当前像素点表征,进而进行标注,我们把它称为空间式。
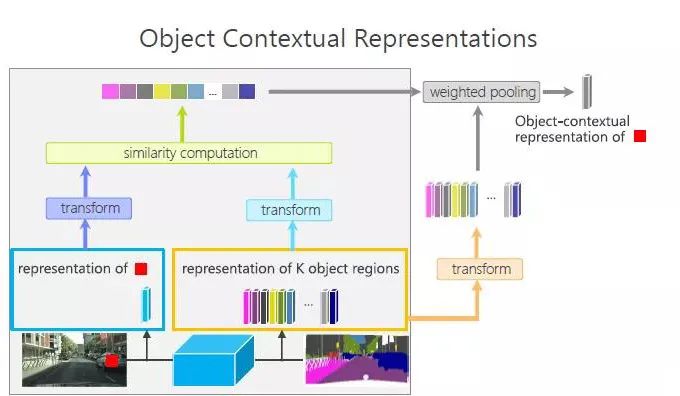
我们的方法是 Object context(对象上下文),它的出发点非常简单,正如前面提到,像素点本身没有标签,标签来自于这个像素点所在的物体,比如下图红色的点,这个位置很难有标签,它的标签来自于这个车。运用这个出发点,我们思考路径是:能不能拿到这个红色像素点所在的物体特征,来帮助表达这个红色的像素点。基于这个出发点,我们提出了 OCR 方法。
OCR 的方法涉及鸡生蛋还是蛋生鸡的问题。我们事先并不知道分割,是先估计一个粗略的分割,有一个当前的表达,比如下图,取红色像素点的特征,把它输入到模块里,得到红色像素点当前的特征和其它的若干特征(K object regions),然后把这些特征经过变换,算出它们之间的相似度,根据相似度,经过加权池化(weighted pooling),然后得到像素点的表征,根据这个表征以及以前的表征一起进行预测。
从数据看,HRNet+OCR 的方法的结果为82.5,这是发表文章时业界最好的结果。
另外简短介绍一下自下而上姿态预测(Bottom-Up Pose Estimation)中的工作。
它不需要人体的检测就可以直接预测人体的关键点。
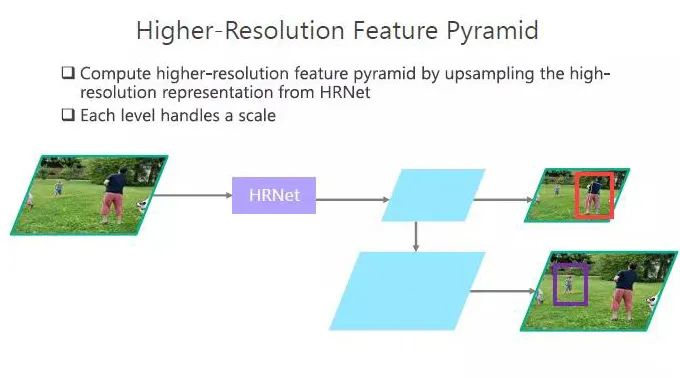
其中有个关于人体大小不一的问题,以前的方法没有确切的解决方式,我们提出“高分辨率特征金字塔”的方法。把图形输入到HRNet中做一个表征,从小的特征中分辨大的,从大的特征里面分辨小的,这个方法的结果表现也是非常好。
最后简单总结一下,我讲的主要是 HRNet,作为一个通用的网络结构,给大家展示了在视觉分割、检测、人体关键点、人脸关键点的预测等任务,一系列的结果都比ResNet 好,目前已经成为一个标准的方法之一。除此以外,我们基于具体任务的网络结构设计,比如加上 OCR 的方法、高分辨率特征金字塔(Higher-Resolution FeaturePyramid)的方法取得的效果都非常好。
你也许还想看:
![]()