CVPR 2019 | 全新缺失图像数据插补框架—CollaGAN

在同一域下的图像和数据是符合一个整体流形分布的,一旦域中的数据缺失,能否利用已有的域中数据去还原丢失的数据呢?
Collaborative GAN 提出了一种新的缺失图像数据插补框架,称为协同生成对抗网络 (CollaGAN)。CollaGAN 是在现在已经成熟的单图像到图像生成的基础上,研究多域图像到图像的翻译任务,以便单个生成器和判别器网络可以使用剩余的干净数据集成功估计丢失的数据。
作者丨武广
学校丨合肥工业大学硕士生
研究方向丨图像生成


论文引入
无论是人眼还是摄像头都不可能实现单采样下全视角的视角采集,往往一个物体的描述需要多视角的结合才能得到完整的性质描述。所以一个完整的数据在实现视觉分析起到很重要的作用,例如在从多个视图相机图像生成三维体积时,大多数算法都需要预先定义视角集,可是由于采集成本和时间,数据集中的(系统)错误等,通常很难获得完整的输入数据集。
估算缺失数据对于物体建模和分析影响很大,有几种标准方法可以根据整组的建模假设来估算缺失数据,如均值插补,回归插补,随机插补等 [1]。然而,这些标准算法对诸如图像这类高维数据具有限制,因为图像插补需要知道高维图像数据流形。图像到图像翻译试图解决高维图像的缺失修复,诸如超分辨率、去噪、去模糊、风格迁移、语义分割、深度预测等任务可被视为将图像从一个域映射到另一个域中的对应图像。
图像翻译的高质量决定着缺失模态估算的准确性,生成对抗网络 (GAN) 的提出大大改善了图像翻译的实现任务。已经很熟悉的模型有 CycleGAN、DiscoGAN、UNIT,这一类实现了两个域之间的单图像到单图像的转换。
StarGAN [2] 和 MUNIT [3] 则可以实现单个生成器学习多个域之间的转换映射,这就是单张图像转换到多张图像。这些基于 GAN 的图像传输技术与图像数据插补密切相关,因为图像翻译可以被认为是通过对图像流形结构建模来估计丢失图像数据库的过程。
然而,图像插补和图像转换之间存在根本差异。例如,CycleGAN 和 StarGAN 有兴趣将一个图像转移到另一个图像,但不考虑剩余的域数据集。然而,在图像插补问题中,丢失的数据不经常发生,并且目标是通过利用其他清洁数据集来估计丢失的数据。
因此 Collaborative GAN 通过设计一个生成器去使用剩余的有效数据集来估计丢失的数据。由于丢失的数据域不难以估计先验,因此应该设计插补算法,使得一种算法可以通过利用其余域的数据来估计任何域中的丢失数据。这一过程和之前所提模型的区别可由下图展示:
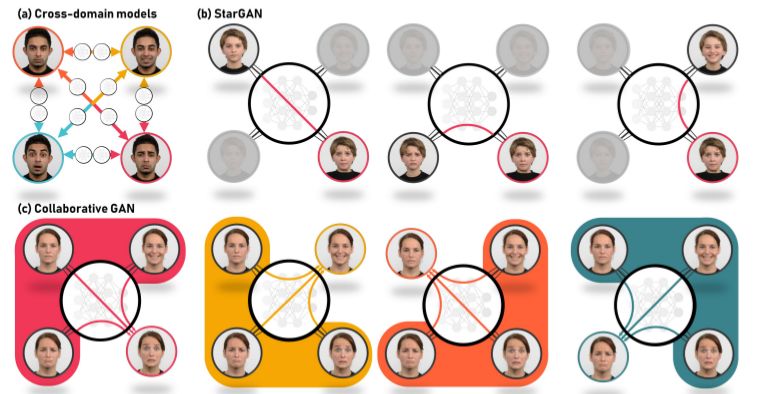
上图 (a) 可以表示单图到单图的模型,代表由 CycleGAN;(b) 图为 StarGAN 转换图示,它是由原输入去转换成对应标签的图像;(c) 则是利用除目标域图像外的其余图像一起作用生成目标标签图像。总结一下协同生成对抗网络(CollaGAN)的优点:
可以从共享相同流形结构的多输入数据集而不是单个输入中更加协同地学习基础图像流形,达到更准确估计丢失数据。
CollaGAN 保留了 StarGAN 类似的单生成器架构,与 CycleGAN 相比,它具有更高的内存效率。
模型实现
首先贴上 CollaGAN 的模型实现框图:
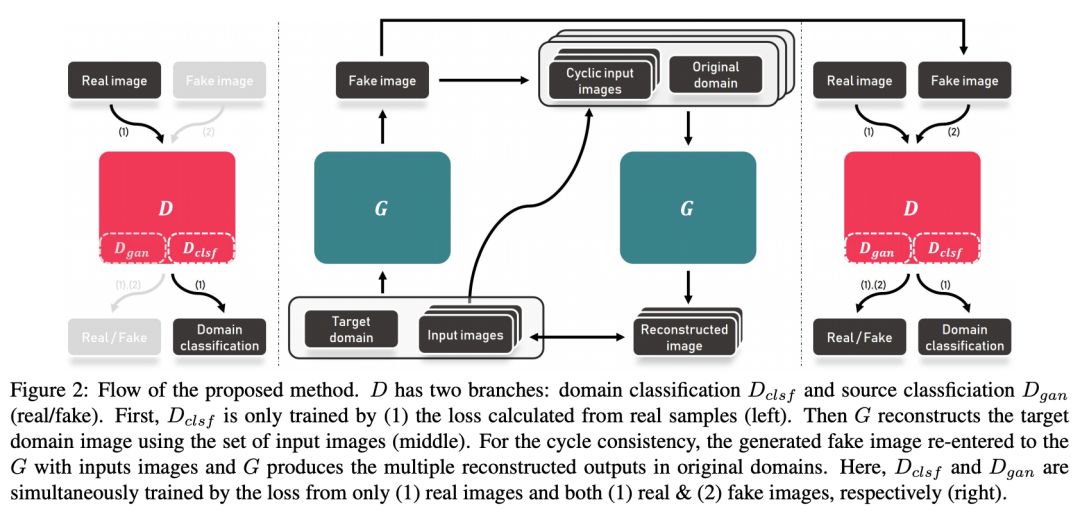
这个图咋一看有些抽象,我们待会再详细分析,先把涉及到的参量做个定义。原文为了便于解释,假设域中含有 4 类样本:a、b、c、d。比如,生成器为了生成域a的样本,则生成器则会参考图像域 b、c、d,将 b、c、d 协同送入生成器获得图像集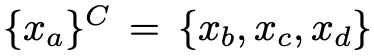
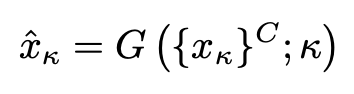
其中 k∈{a,b,c,d} 表示目标域索引,用于指导生成适当目标域的输出 κ。由于存在多个输入和单输出组合的 N 个组合,在训练期间随机选择这些组合,以便生成器学习到多个目标域的各种映射。
我们来分析一下如何实现 CollaGAN,类似于 StarGAN,判别器的作用有两个,一个是实现对生成图像判断真假,另一个是实现域分类作用,确定图像是来自哪一个域。判别器的分类和判断只在最后一层分出,其余网络部分均共享参数,模型框图的最左侧就是预训练判别器的分类参数。
通过固定网络的其余部分只对判别器实现图像域分类做优化,这一实现可以通过仅送入真实域图像下利用交叉熵损失实现:
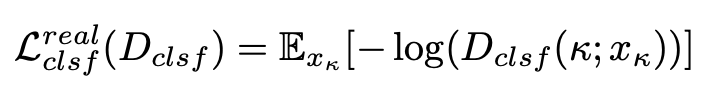
其中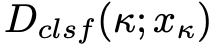
训练好判别器的分类就可以对模型的正式部分进行训练,对于生成器 G(图中的中间部分)输入的是要生成目标域的类别标签 Target Domain,和其余域类的协同输入 Input Image,经过生成器得到目标域图像 Fake Image,为了实现循环一致的思想,用生成的 Target Image 作为协同输入的一部分去生成其余的域图像。
对于 a、b、c、d 的 4 类输入下,假设目标域是 a,这个循环思想的思想就要再重构其余 3 类:
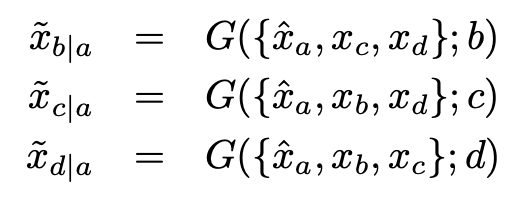
优化循环一致损失为:
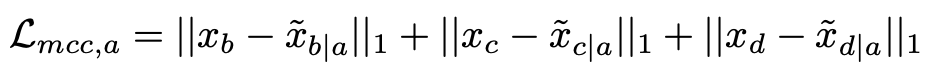
这里的 ‖⋅‖ 表示的是 L1 损失,这个循环一致的推广到各类域可进一步表示为:
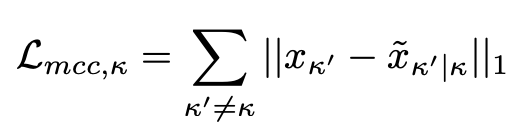
此时:
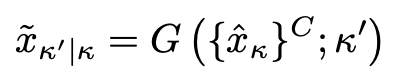
模型框图的最右侧就是训练中判别器的,判别器在训练阶段除了分清图片的真假还有就是通过分类器去优化生成器网络。我们解释下怎么通过分类去优化生成器,通过训练发生器 G 以产生由 Dclsf 正确分类的假样本。因此,对于 G,在优化生成域分类当最小化损失:
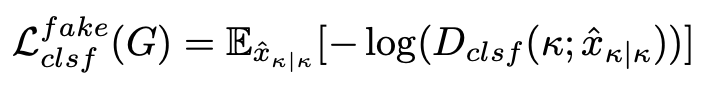
至于生成对抗损失,文章采用的是较为稳定的 LSGAN:
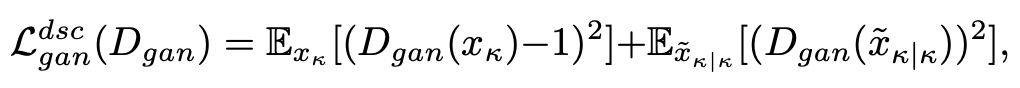
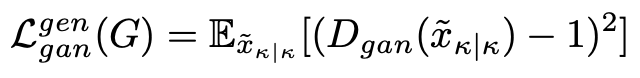
域标签的嵌入采用经典的 one-hot 形式。
这里提一下如何实现生成器输入端的协同输入,这个的实现在文章中是根据不同的数据集采取的方式是不同的,对于面部表情数据集 RaFD 下八个面部表情,对生成器重新设计有八个编码器分支,并且在生成器的中间阶段的编码处理之后将它们连接起来。生成器的架构是包含编码解码过程的,整体采用 U-Net 实现,判别器采用 PatchGAN 的设计思路。
实验
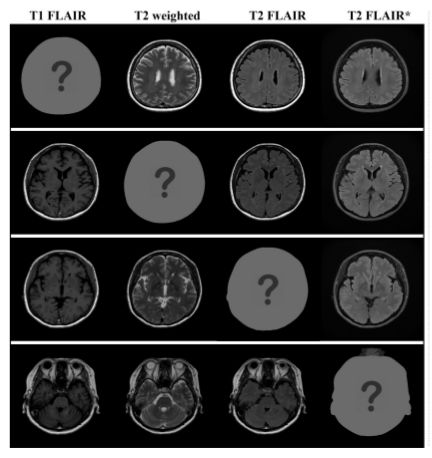
文章主要在三个数据集下进行实验测试,MR contrast synthesis 数据集是通过多动态多回波序列和来自 10 个受试者的附加 T2 FLAIR(流体衰减反转恢复)序列扫描总共 280 个轴脑图像。
在数据集中有四种类型的 MR 对比图像:T1-FLAIR (T1F),T2-weighted(T2w),T2-FLAIR (T2F) 和 T2-FLAIR (T2F)。前三个对比度是从磁共振图像编译(MAGiC,GE Healthcare)获得的,T2-FLAIR * 是通过第三对比度(T2F)的不同MR扫描参数的附加扫描获得的。MR contrast synthesis 数据集也是作者进行本次研究的目的性数据集。
CMU Multi-PIE 数据集使用了 Carnegie Mellon Univesity 多姿态照明和表情面部数据库的子集,250 名参与者,并且在以下五种照明条件下选择中性表情的正面:-90°(右), - 45°,0°(前),45° 和 90°(左),并将图像裁剪为 240×240,其中面部居中。
对于此数据集的实验上,使用 YCbCr 颜色编码代替 RGB 颜色编码。YCbCr 编码由 Y 亮度和 CbCr 色空间组成。在五种不同的照明图像,它们几乎共享 CbCr 编码,唯一的区别是 Y-亮度通道。因此,处理唯一的 Y 亮度通道用于照明转换任务,然后重建的图像转换为 RGB 编码图像。

Radboud Faces 数据集(RaFD)包含从 67 名参与者收集的八种不同的面部表情;中立,愤怒,轻蔑,厌恶,恐惧,快乐,悲伤和惊讶(这个数据集在 StarGAN 中也被使用)。此外,有三个不同的凝视方向,总共 1,608 个图像,并将图像裁剪为 640×640 并将 resize 为 128×128。
在 MR 的数据集上,实验对比了 CycleGAN、StarGAN 和 CollaGAN:
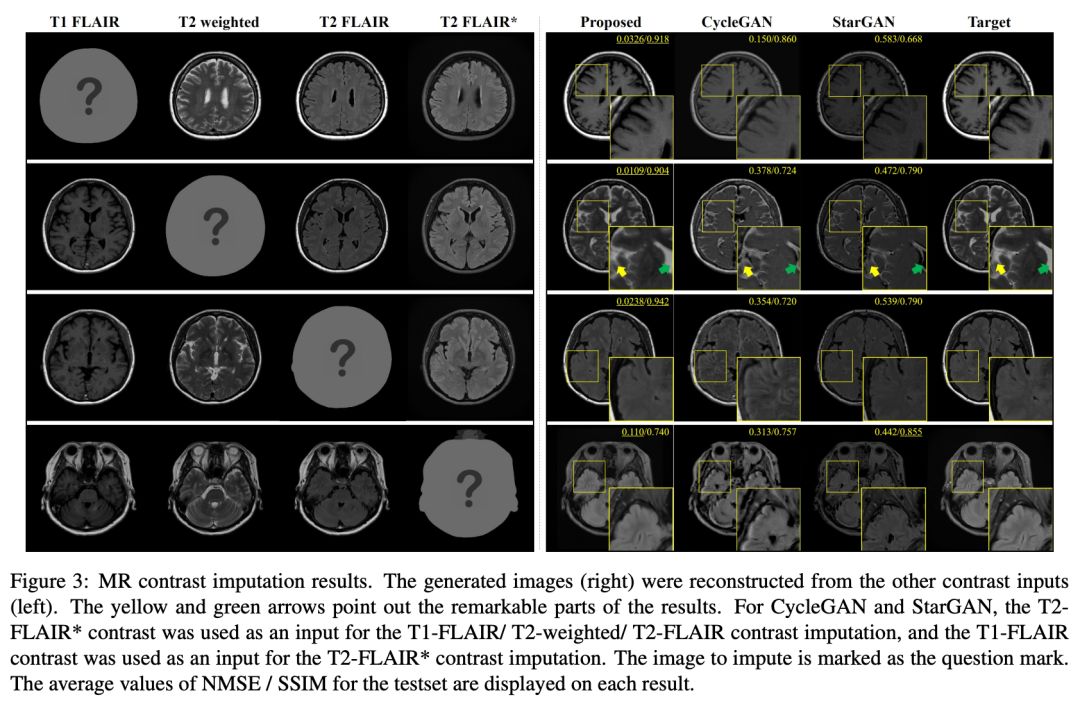
从医学分析上 T2-weighted 图像中的脑脊液(CSF)应该是明亮的,上图中的第二行结果,这个在 CollaGAN 上效果最佳,在 StarGAN 和 CycleGAN 上则是暗淡的,在另外两个数据集下的定性测试上,CollaGAN 也展示优势:


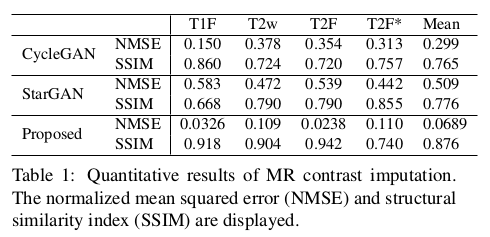
文章还对不同域下的图像弥补缺失输入下进行了测试,得到的结果依旧是正向的:

在定量分析上,作者采用重建和目标之间计算归一化均方误差(NMSE)和结构相似性指数(SSIM)来衡量,文章还花了一定篇幅介绍了 SSIM 的度量计算公式(感兴趣的可以自行阅读原文)。在定量上对比 CycleGAN 和 StarGAN 得到了优异的效果。
总结
CollaGAN 通过在单个发生器和判别器的帮助下协同组合来自可用数据的信息,提出了一种新颖的 CollaGAN 架构,用于丢失图像数据插补。与现有方法相比,所提出的方法产生了更高视觉质量的图像。
CollaGAN 的创新在于生成器的多输入下生成域中缺失信息,这个想法是以往模型中没有的,同时利用多域下的有效信息去恢复缺失信息也很符合人类的思考方式。
参考文献
[1] A. N. Baraldi and C. K. Enders. An introduction to modern missing data analyses. Journal of school psychology,48(1):5–37, 2010.
[2] Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo.StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. arXiv preprint, 1711,2017.
[3] Huang X, Liu M, Belongie S J, et al. Multimodal Unsupervised Image-to-Image Translation[J]. european conference on computer vision, 2018: 179-196.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文



