详解深度学习中的双下降现象
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
作者:Preetum Nakkiran,Gal Kaplun,Yamini Bansal,Tristan Yang,Boaz Barak,Ilya Sutskever
编译:ronghuaiyang
深度学习中的双下降现象,可能大家也遇到过,但是没有深究,OpenAI这里给出了他们的解答。
我们展示了 CNN,ResNet 以及 transformers 中的双下降现象,随着模型的尺寸,数据集的大小以及训练时间的增加,performance 先提升,然后变差,然后再次提升。这种效果通常可以通过仔细的正则化来避免。虽然这种行为似乎是相当普遍的,但我们还没有完全理解它为什么会发生,并把对这种现象的进一步研究作为一个重要的研究方向。
论文:https://arxiv.org/abs/1912.02292
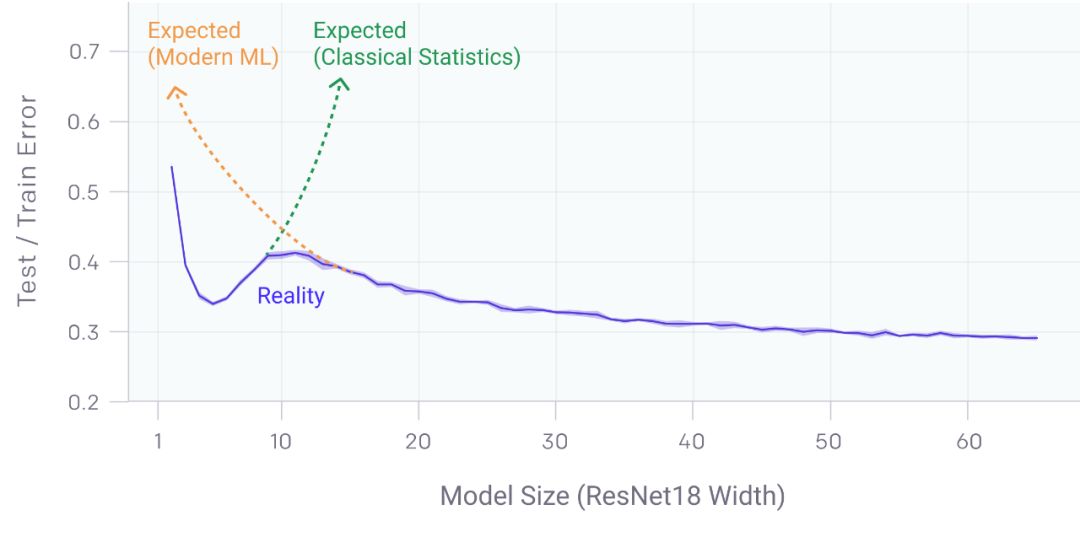
包括 CNNs、ResNets、transformer 在内的许多现代深度学习模型,在不使用 early stopping 或正则化时,都表现出之前观察到的双下降现象。峰值发生在一个可以预见的“特殊的时刻”,此时模型刚好可以去拟合训练集。当我们增加神经网络参数的数量,刚开始的时候,测试误差减少,然后会增加,而且,模型开始能够拟合训练集,进行了第二次下降。
传统统计学家认为“模型越大越糟”的传统观点,以及“模型越大越好”的现代机器学习范式,都没有得到支持。我们发现双下降也发生在训练过程中。令人惊讶的是,我们发现这些现象会导致数据越多效果越差,此时在更大的训练集上训练一个深层网络的效果实际上更差。
模型的双下降
-
在一段时间内,模型越大效果越差。
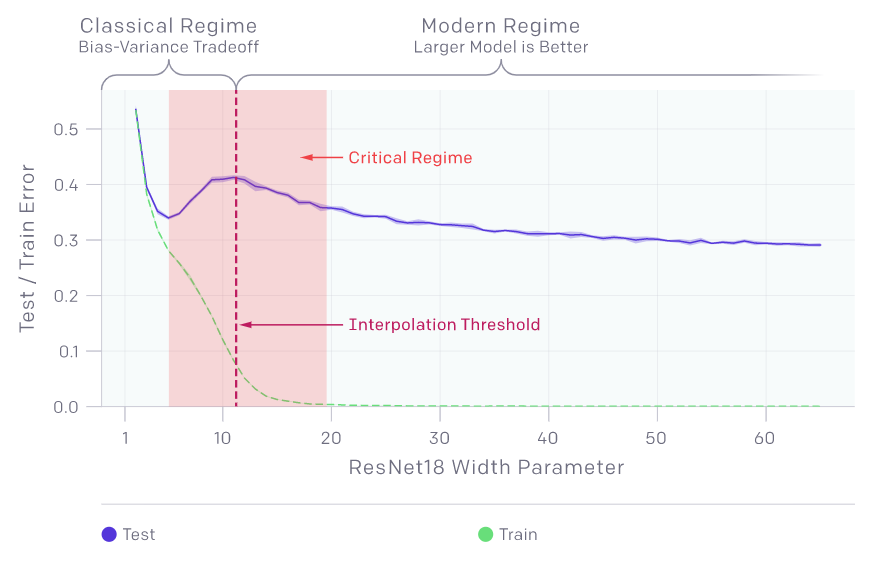
模型的双下降现象会导致对更多数据的训练效果越差。在上面的图中,测试误差的峰值出现在插值阈值附近,此时模型刚好足够大到能拟合训练集。
在我们观察到的所有情况下,影响插值阈值的变化(如改变优化算法、训练样本数量或标签噪声量)也会相应地影响测试误差峰值的位置。在添加标签噪声的情况下,双下降现象最为突出,如果没有它,峰值会更小,很容易被忽略。添加标签噪声会放大这种普遍的行为,让我们可以很容易地进行研究。
样本的非单调性
在一段时间内,样本越多效果越差。
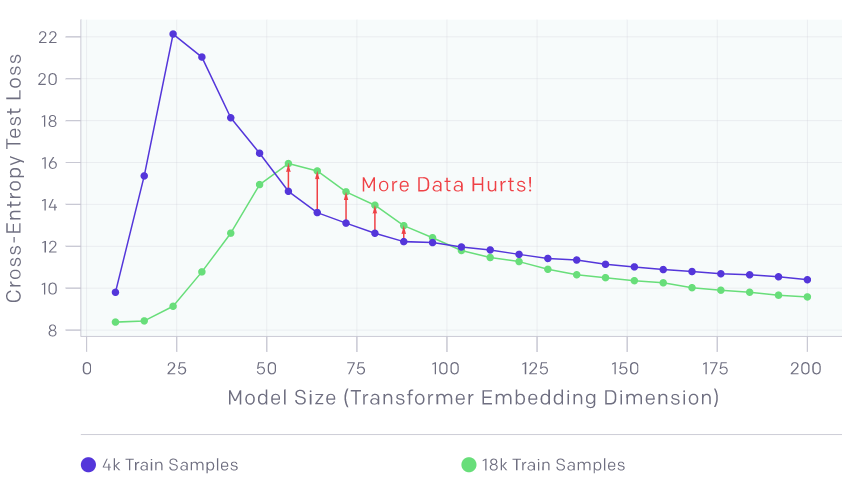
上面的图显示了在没有添加标签噪声的情况下,在语言翻译任务训练的 transformers。正如预期的那样,增加样本数量会使曲线向下移动,从而降低测试误差。然而,由于更多的样本需要更大的模型来拟合,增加样本的数量也会使插值阈值(以及测试误差的峰值)向右移动。对于中等大小的模型(红色箭头),这两个效果结合在一起,我们可以看到在 4.5 倍的样本上进行训练实际上会影响测试性能。
训练 epoch 的双下降
-
在一段时间内,训练时间越长,过拟合情况就越严重。
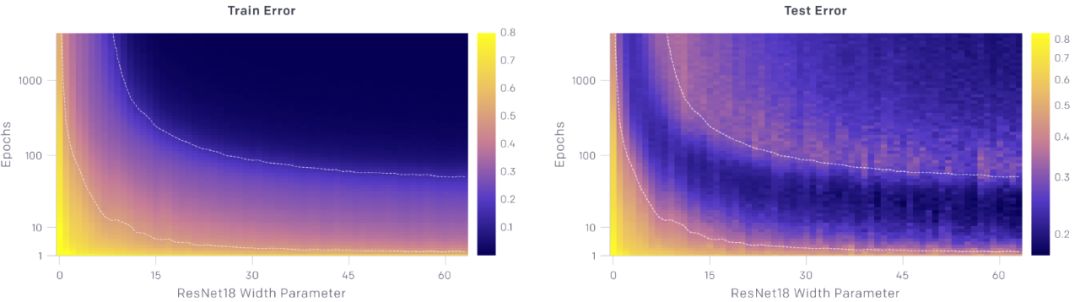
上面的图显示了测试和训练误差与模型大小和优化步骤数量的关系。对于给定数量的优化步骤(固定 y 坐标),测试和训练误差表现为随着模型的大小出现了双下降。对于给定的模型尺寸(固定的 x 坐标),随着训练的进行,测试和训练误差不断地减小、增大、再减小,我们把这种现象称为 epoch-wise 的双下降。
一般情况下,当模型刚好能够拟合训练集时,会出现测试误差的峰值
我们的直觉是,对于插值阈值处的模型,实际上只有一个模型正好拟合了数据集,而强迫它拟合即使是稍微有一点噪声或错误的标签也会破坏它的全局结构。也就是说,没有既能在插值阈值处拟合训练集又能在测试集上表现良好的“好模型”。然而,在参数化的情况下,有许多模型可以拟合训练集,并且存在这样的好模型。此外,随机梯度下降法(SGD)的隐式偏差导致了这样好模型出现,其原因我们还不清楚。
我们把对深层神经网络的双下降机制仍的充分认识作为一个重要的开放性问题。

英文原文:https://openai.com/blog/deep-double-descent/
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
推荐阅读
最新AI干货,我在看