前沿分享-基于区块链技术的机器学习行业概述
以区块链市场数据为基础的训练出来的机器学习有可能创造出世界上最强大的人工智能。它们结合了两个强大的源力:私有机器学习,它允许在敏感的私有数据上进行训练而不泄露数据;以及基于区块链的激励措施(incentive),它可以使这些系统获取最佳数据和模型,使它们变得更智能。结果是开放的市场,任何人都可以出售他们的数据,并保护他们的数据隐私,而开发人员可以利用激励措施来获得他们的算法所需要的最佳数据。
构建这些系统是一项挑战,必要的构建块仍在创建中,但简单的初始版本似乎已开始成为可能。我相信这些市场将把我们从目前的Web 2.0数据垄断时代转变为一个数据和算法公开竞争的Web 3.0时代,两者都直接货币化。
起源
这个想法的基础来自于2015年与Numerai的理查德的谈话。Numerai是一家对冲基金公司,它将加密的市场数据发送给任何希望参与股市建模竞争的数据科学家。Numerai将最佳模型提交组合成一个“元模型”,交易该元模型,并向模型性能良好的数据科学家支付报酬。
让数据科学家之间进行竞争似乎是一个强大的想法。所以它让我想到:是否可以创建一个完全分散的系统版本,可以推广到任何问题?我相信答案是肯定的。
构建
例如,让我们尝试创建一个完全分散的系统,用于在分散的交易所之间交易密码货币。这是许多潜在构件之一:
数据:数据提供者将数据与模型相关联并提供给建模人员。
模型构建(Model Building):建模人员选择需要使用的数据并创建模型。
训练是使用一种安全的计算方法来完成的,该方法允许在不暴露底层数据的情况下训练模型。模型也被固定了。
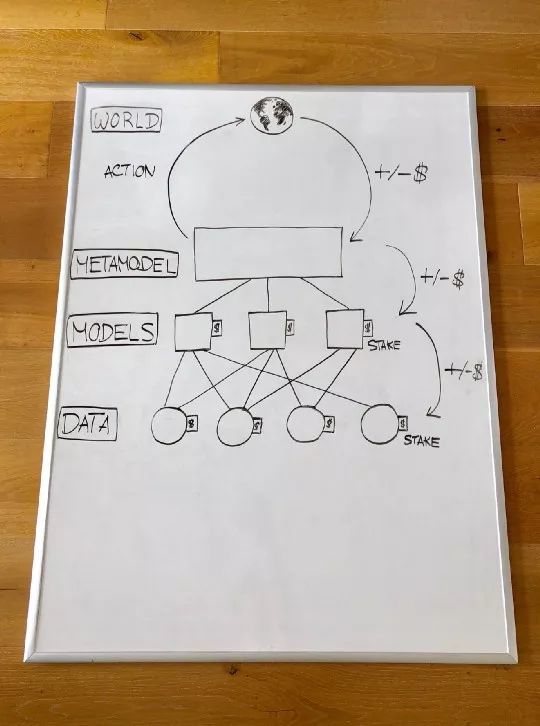
元模型(Metamodel)构建:元模型是基于每个固定的模型的为基础构造的算法创建的。
创建元模型是可选的—构造模型时,也可以不适用一些元模型。
使用元模型:一个智能协议(smart contract)将获取元模型,通过链上分散的交换机制(Decentralized exchange mechanism on-chain)以编程方式进行交易。
分散gains/losses:经过一段时间后,交易会产生利润(profits)或loss。这种profits或loss在元模型的贡献者之间根据他们的聪明程度进行分配。起负贡献的模型采用了部分或全部的注资(staked funds)。然后,模型会发生变化,并对其数据提供者执行类似的分发/stake。
验证性计算:每个步骤的计算或者使用诸如Truebit的验证游戏集中执行,但是可以验证和挑战,或者使用安全多方计算(secure multiparty computation)分散执行。
托管(Hosting):数据和模型或者托管在IPFS上,或者托管在安全多方计算网络中的节点上,因为链上存储太昂贵。
是什么使这个系统强大?
吸引全球最佳数据的激励措施:吸引数据的激励措施是系统中最有效的部分,因为数据往往是大多数机器学习系统中最重要的部分。就像比特币通过开放式激励机制创建了一个拥有全球最高计算能力的应急系统一样,一个经过适当设计的数据激励结构将使你的的应用程序获得世界上最好的数据。而且几乎不可能关闭一个可以从数千或数百万来源获取数据的系统。
算法之间的竞争:在不同的模型/算法之间创建一个公开的竞争,在以前是不存。想象一下一个分散的Facebook上有成千上万种相互竞争的新闻推荐算法。
报酬的透明度:数据和模型提供者可以看到他们得到了他们所提交的数据的公正的价值,因为所有计算都是可验证的,这使得他们更有可能参与。
自动化:在链上执行操作并直接在token中生成值的方法,创建了一个自动化且不可信的闭环系统。
网络效应:来自用户、数据提供者和数据科学家的多方面网络效应使系统自我强化(self-reinforce)。它表现得越好,吸引的资本就越多,这就意味着潜在的回报也就越多,这就吸引了更多的数据提供商和数据科学家,他们使系统变得更智能,从而吸引了更多的资本,然后又回到原来的位置。
隐私
除了以上几点之外,一个主要特征是隐私。它允许1 )人们提交一些会太私人而无法共享的数据,2 )防止数据和模型的经济价值泄露。如果未加密,数据和模型将被免费复制,并由没有贡献任何工作的人使用(“搭便车(Free rider)”问题)。
Free rider问题的一些解决方案是私下出售数据。即使购买者选择转售或发布数据,其价值也会随着时间而衰减。然而,这种方法限制了我们的短时用例,并且仍然产生典型的隐私问题。因此,更复杂但更强大的方法是使用一种安全计算的方法。
安全计算
安全计算方法允许模型在不暴露数据本身的情况下对数据进行训练。目前使用和研究的安全计算主要有三种形式:同态加密(Homomorphic encryption,HE )、安全多方计算(secure multi-party computation,MPC )和零知识证明(zero knowledge proofs,ZKPs )。多方计算是木器于私有机器学习最常用的方法,因为同态加密往往太慢,如何将ZKPs应用于机器学习还不清楚。安全计算方法正处于计算机科学研究的前沿。它们通常比常规计算慢几个数量级,是系统的主要瓶颈,但近年来一直在改进。
最终推荐系统(Ultimate Recommender System)
为了说明私人机器学习的潜力,想象一个叫做“最终推荐系统”的应用。它会监视你在设备上所做的一切:浏览历史记录、应用程序中所做的一切、手机上的图片、位置数据、消费历史记录、可穿戴传感器、短信、家中的相机、未来AR眼镜上的相机。然后它会给你一些建议:你应该访问的下一个网站,要阅读的文章,要听的歌曲,或者要购买的产品。
这种推荐系统将是非常有效的。比Google、Facebook或其他公司现有的任何数据都要多,因为它可以最大限度地纵向查看您的信息,并且可以从本来就太私人而无法考虑共享的数据中学习。类似于先前的密码货币交易系统,它将通过允许集中于不同领域的模型市场(例如:网站推荐、音乐)来竞争对加密数据的访问权限,并向您推荐内容,甚至可能会因为您贡献了数据或关注了生成的推荐而向您付费。
Google的联合学习(federated learning)和Apple的差异隐私(differential privacy)是这种私人机器学习方向实用化发展的一步,但仍然需要信任,不允许用户直接检查他们的安全性,并保持数据私有化。
现行办法
太早了。没有几个小组有任何工作,大多数人都试图一次能往前进一大步。
Algoria Research的一个简单框架(construction)为准确超过某个回溯测试阈值的模型提供奖励:
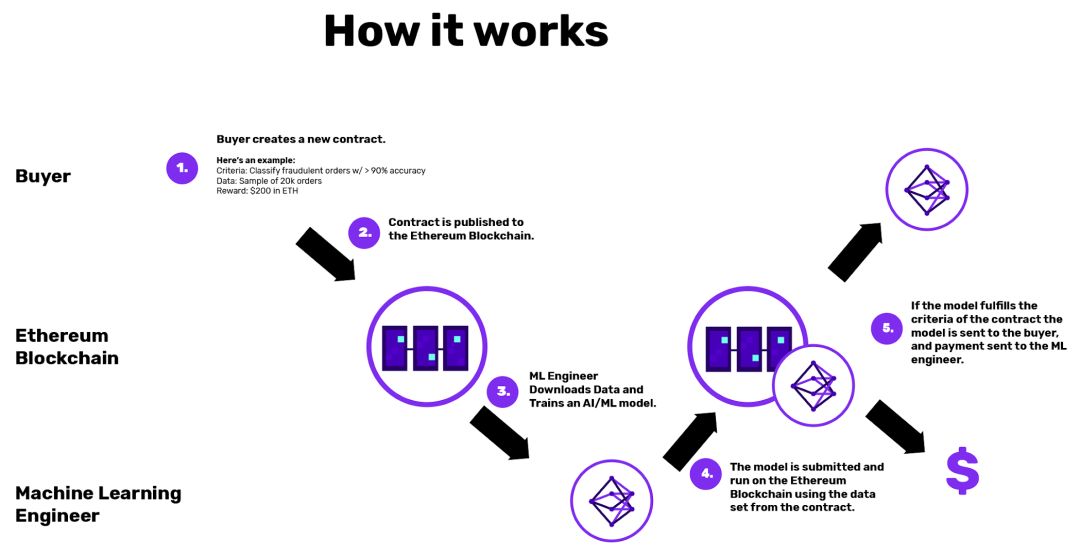
Algorithmia Research在机器学习模型上创建奖励的简单框架
Numerai目前更进一步,采取了三个步骤:使用加密数据(虽然不是完全同态),将众包模型组合成元模型,并且基于未来的性能(在本例中,是一周的股票交易)而不是通过名为Numeraire的本地 Ethereum token进行回溯测试。数据科学家必须在游戏中以数字作为赌注,在将要发生的事情(未来的表现)上鼓励人们表现(performance),而不是在已经发生的事情(事后测试的表现)上表现。但是,目前集中分发数据,限制了最重要的内容。
迄今为止,还没有人成功创建基于区块链技术的数据市场。Ocean公司最早尝试去勾勒这个市场的框架。
还有一些公司则开始构建安全的计算网络。Openmined正在创建一个多方(multiparty)计算机网络,用于在Unity之上训练机器学习模型,该网络可以在任何设备上运行,包括游戏控制台(类似于在家里Folding),然后扩展到安全的MPC。Enigma也有类似的策略。
一个令人着迷的最终状态是相互拥有的元模型,它赋予数据提供者和模型创建者与他们变得聪明程度成正比的所有权。这些模型将被标记化,可以随着时间的推移而产生红利,甚至可能由训练它们的人来管理。一种相互拥有的蜂箱思维(Hive mind)。原始的开放视频是我迄今为止看到的最接近的结构。
哪些方法可能首先起作用?
我不会说什么是最好的、最精确的结构,但我有一些想法。
我用来评价区块链思想的一个观点是:在一系列物理上(physically)的native到数字上(digitally)的native,再到区块链(blockchain)的native,区块链native越多越好。区块链native越少,引入的第三方就越可信,从而增加了复杂性并降低了与其他系统一起作为构建块的易用性。
在这里,我认为这意味着,如果创造的价值是可以量化的,那么一个系统更有可能发挥作用—理想的是直接以货币的形式,更好的是以token的形式。这使得一个清洁的闭环系统(clean,closed-loop system)成为可能。将密码货币交易系统的先例与在X射线中识别肿瘤的例子进行比较。在后一种情况下,您需要让保险公司相信X射线模型是有价值的,协商其价值,然后找一群实际在场的一小群人来验证模型的成败。
这并不是说更清楚且肯定的、社会的数字native相关的用途不会出现。像前面提到的推荐系统可能非常有用。如果连接到营销市场,则是另一种情况,在这种情况下,模型可以以编程方式在链上执行操作,系统的回报是token(在这种情况下,来自营销市场),从而再次创建一个干净的闭环。现在看起来很模糊,但我预计区块链native任务的范围会随着时间的推移而扩大。
意义
第一,分散的机器学习市场可以打破当前科技巨头的数据垄断。过去20年来,它们使互联网价值创造的主要来源标准化和商品化:专有数据网络及其强大的网络效应。因此,价值创建将从数据向上移动到算法。
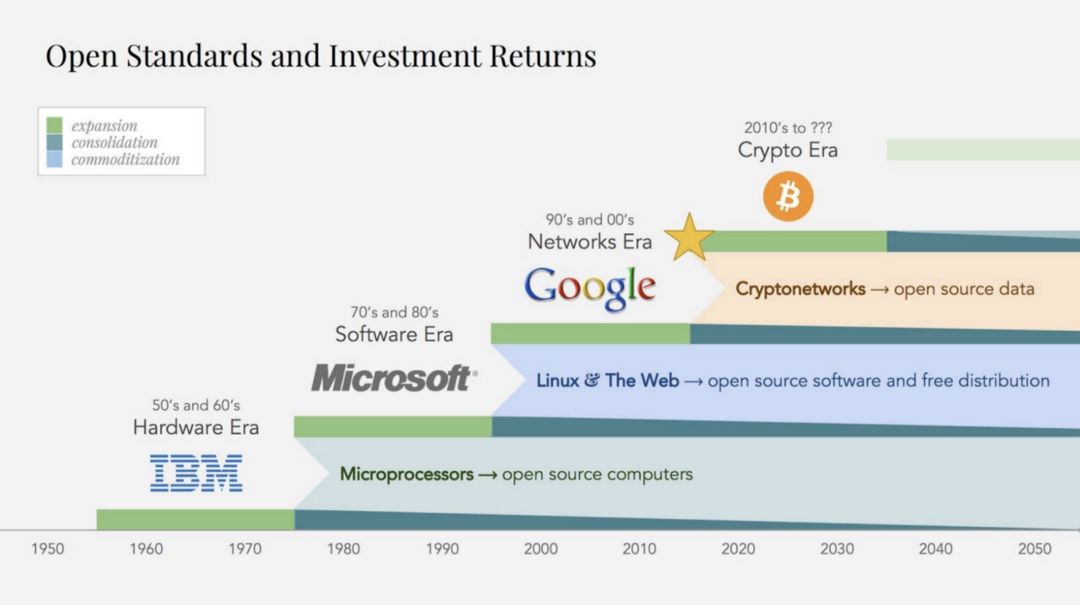
技术领域的标准化和商品化周期,数据垄断的网络时代即将结束
换句话说,他们为人工智能创建了一个直接的商业模式。同时Feeding和训练它。
第二,它们创造了世界上最强大的人工智能系统,通过直接的经济激励(economic incentives)吸引了最好的数据和模型。它们的强度(strength)通过多面网络效应(multi-sided network effects)而增加。随着Web 2.0时代的数据网络垄断变得商品化,它们似乎是下一个重聚合点(re-aggregation)的理想选择。我们可能离这点还有几年时间,但方向似乎是正确的。
第三,如推荐系统例子所示,搜索得到反转。不是人们搜索产品,而是产品搜索和用户的竞争。每个人都可能有自己的推荐市场,推荐系统在那里竞争把最相关的内容放在他们的feed中,相关性是由个人定义的。
第四,它们可以让我们从谷歌和Facebook等公司那里得到同样的好处,而不用泄露我们的数据。
第五,机器学习可以更快进步,因为任何工程师都可以访问开放的数据市场,而不仅仅是大型Web 2.0公司中的一小部分工程师。
挑战
首先,安全计算方法目前非常慢,并且机器学习目前非常消耗计算资源。另一方面,人们对安全计算方法的兴趣开始升温,性能也在不断提高。在过去的6个月中,我看到了HE、MPC和ZKPs提出了显著改进性能的新方法。
将特定数据集或模型提供给元模型(metamodel)计算是很困难的。
清理和格式化众包数据具有挑战性。我们可能会看到一些将工具、标准化和小型企业(small businesses)的组合来解决这个问题。
最后,具有讽刺意味的是,创建这种系统的通用结构的业务模型不如创建单个实例清晰。这似乎对于许多新的crypto primitive是真的,包括curation market。
结论
将私人机器学习与区块链incentives相结合可以在各种各样的应用中产生最强的机器智能。随着时间的推移,有一些重大的技术挑战可以被解决。他们的长期潜力是巨大的,这是一个可喜的转变,摆脱了目前大型互联网公司对数据的掌控。它们也有点可怕—它们引导自己生存、自我强化、消耗私人数据,而且几乎无法关闭,这让我怀疑创建它们是否比以往任何时候都更能召唤出一个强大的Moloch。无论如何,它们是另一个例子,说明密码货币(cryptocurrencies)是如何慢慢进入各个行业的。
往期内容推荐
麻省理工学院-2018年最新深度学习算法及其应用入门课程资源分享
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
2017-最全手势识别/跟踪相关资源大列表分享(论文、数据集、比赛等)



DeepLearning_NLP


深度学习与NLP
商务合作请联系微信号:lqfarmerlq



