生成对抗网络在图像翻译上的应用【附PPT与视频资料】

关注文章公众号
回复"刘冰"获取PPT与视频资料
导读
在图像处理、计算机图形和计算机视觉中,许多问题都可以表现为将输入图像“转换”成相应的输出图像。 正如我们常见的机器翻译中,同一句话可以用英语或中文表达一样,一副场景图可以用RGB图像、梯度场、边缘图,语义标签图等。与自动语言翻译类似,我们定义自动图像翻译如下:将图像从一种domain转换到另一个domain的任务,其本质仍旧是图像生成任务。在本文中,我们依次介绍了pixel2pixel、cycleGAN、StarGAN、ModularGAN一系列文章,目的是探索GAN在图像翻译任务中的应用。
作者简介
刘冰,北京大学信息科学技术学院,博士二年级在读,本科毕业于北京科技大学。目前主要的研究兴趣在基于GAN模型处理生物特征识别中的图像拼接问题。

1.背景
图像翻译是指图像内容从一个域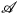
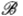
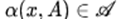
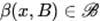
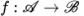
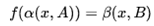
目前主流的深度生成模型主要基于生成对抗网络(GANs),它是通过生成器和判别器双方博弈的过程,迭代优化,训练网络。
2.方法
1.1 Pixel2Pixel(Image-to-Image Translation with Conditional Adversarial Networks)
该方法发表于CVPR2017,是图像翻译系列论文的经典著作。如图1,它采用条件生成对抗网络(CGAN)结构,和原始的生成对抗网络相比, CGAN在生成器的输入和判别器的输入中都加入了条件y。这个y可以是任何类型的数据(可以是类别标签,或者其他类型的数据等)。目的是有条件地监督生成器生成的数据,使得生成器生成结果的方式不是完全自由无监督的。
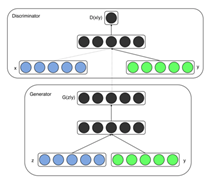
图1 CGAN基本网络结构图
整体的网络结构图如图2所示,其中生成器采用U-Net结构,目的是可以融合图像的底层特征;判别器采用PatchGAN结构,即判别器以类似于卷积核(大小N*N)的方式卷积滑动的穿过整个图像,每次只对N*N的局部patch做0-1判别,其目的是为了生成质量更清晰的图像。
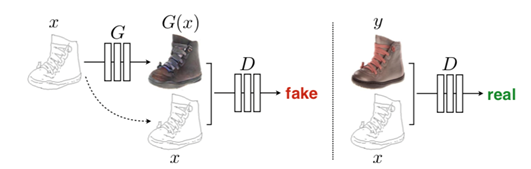
图2 算法整体网络结构图
下面以白天变黑夜的效果图为例,展示算法取得的实验结果:

图3 实验结果图
2.2 CycleGAN(Unpaired Image-to-Image Translation using Cycle-ConsistentAdversarial Network)
首先我们来想想这篇文章的出发点,上篇文章我们已经看到,数据集的一个非常重要的要求就是图像必须是成对的,这一点其实是非常苛刻的,现实中很难找到,就好比同一个场景下的白天和黑夜的两幅图,很难找到这样一个大的数据集里面包含完全相同的同一个场景下的白天与黑夜图。那么这篇文章就是为了解决这样一个问题,就是训练集不在需要同一组完全配对的图,只需要两个模式不同的图即可。
网络结构图如下图4所示,其中的G,F是两个不同的生成器,Dx 、Dy是两个不同的判别器。生成器G、F可以生成与target domain相同分布的图像,然而这种图像可能已经失去了与原图的相似性,因此为了减少可能存在的映射函数的空间,需要加一个cycle的loss函数。
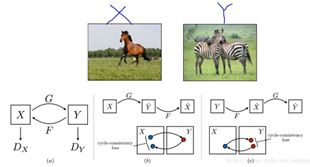
图4 CycleGAN网络结构图
因此,网络整体的loss为:
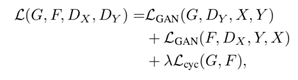
在网络设计方面,生成器的结构采用当下比较流行的框架:包含2个stride-2 的卷积块, 几个residualblocks 和两个0.5-strided卷积完成上采样过程。判别器的结果沿袭上篇pixel2pixel文中提出的PatchGAN方法,其中patch的大小设置为70*70。
实验效果图如下图5所示:

图5 实验效果图
当然,文中也列举出了一些模式转换失败的案例,例如该算法在几何形状的变换上不具有鲁棒性。
2.3 StarGAN: Unified GenerativeAdversarial Networks for Multi-Domain Image-to-Image Translation
前面两篇文章解决的都是一对一的图像翻译任务,如果我们希望在多个领域之间转换,那么对于每两个领域之间都需要重新训练一个模型去解决,对于K个领域,我们则需要训练k(k−1)个生成器(如图6),显然这样的方法效率比较低。本文要解决的问题就是只用一个generator解决多个领域转换的问题。By the way,作者认为不能全部利用训练数据(数据少),也是之前方法不好的原因。
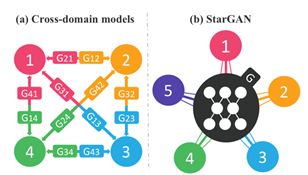
图6 Cross-domain models与StarGAN对比图
如下图7所示,要想让G拥有学习多个领域转换的能力,需要对生成网络G和判别网络D做如下改动:
1)在G的输入中添加目标领域信息,即把图片翻译到哪个领域这个信息告诉生成模型。
2)D除了具有判断图片是否真实的功能外,还要有判断图片属于哪个类别的能力。这样可以保证G中同样的输入图像,随着目标领域的不同生成不同的效果
3)此外,还需要保证图像翻译过程中图像内容要保存,只改变领域差异的那部分。图像重建可以完整这一部分,图像重建即将图像翻译从领域A翻译到领域B,再翻译回来,不会发生变化。
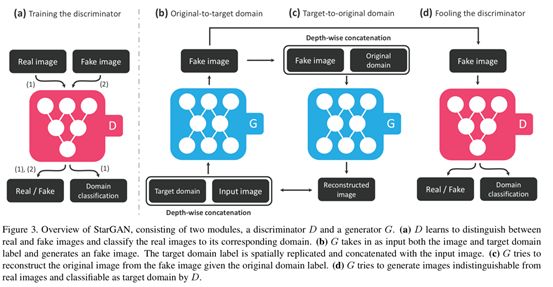
图7 网络示意图
汇总一下此网络所用到的所有的loss函数:
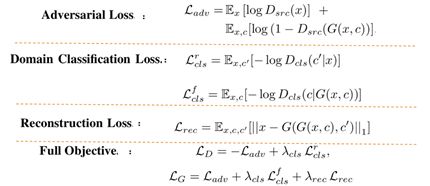
实验利用了两组高清人脸数据集,分别是CelebA和RaFD。其中,CeleA包含7个domain,包含以下标签:hair color (black, blond, brown), gender (male/female), and age (young/old);RaFD包含8组人脸表情,例如happy,angry and sad。定性结果分别如下图8、9所示:

图8 CeleA数据集中对脸部翻译结果

图9 RaFD数据集中对脸部翻译结果
2.4 Modular Generative AdversarialNerworks
在上一篇文章中,StarGAN已经很好的解决了多domain转换的问题,并且可以提高数据的利用率。然而该篇文章认为,StarGAN将任意复杂的变换都只用一个生成器来完成,这无疑增加了生成器训练的难度,使得模型变得更加复杂,甚至更加难以训练。因此,文中采用的方法是将多domain的图像生成任务拆解成多步简单的生成模块叠加。例如我们希望将一张生气的男性脸变成微笑的女性脸,我们可以将这个转换过程拆解为:先从生气的男性脸变成生气的女性脸,再继续从生气的女性脸变成微笑的女性脸。整个训练、测试过程如下图10所示。
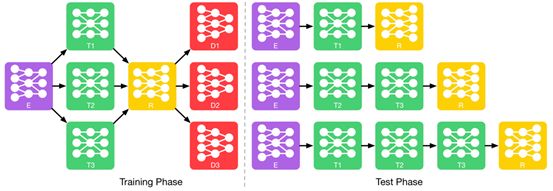
图10 训练、测试过程图
其中,E表示Encoder(Generator)、T表示Transformer(算法核心)、R表示Reconstructor、D表示Discriminator。训练过程中,各个transformer模块独立并行的训练,测试时需要用到哪个特性的transformer模块,就将哪些tranformer模块串联起来,最终生成所需要的图标图像。
实验结果如下图所示:

图11 实验结果图
3.Take-Home Message
随着近年来GAN研究的日趋火热,GAN在各方面的应用也如井喷式爆发。当然这离不开GAN算法自身的优越性,但GAN在训练上还需要大量的trick,且存在训练不稳定的弊端。如何能够扬长避短,使得GAN在图像翻译任务上得到更好的效果,以及如何对图像生成任务建立一个可靠的量化指标,仍是将来需要探讨的问题。
4.Reference
[1] Isola P, Zhu J Y, Zhou T, et al.Image-to-image translation with conditional adversarial networks[J]. arXivpreprint, 2017.
[2] Zhu J Y, Park T, Isola P, et al. Unpairedimage-to-image translation using cycle-consistent adversarial networks[J]. arXivpreprint, 2017.
[3] Choi Y, Choi M, Kim M, et al. Stargan:Unified generative adversarial networks for multi-domain image-to-imagetranslation[J]. arXiv preprint, 2018.
[4] Zhao B, Chang B, Jie Z, et al. ModularGenerative Adversarial Networks[J]. arXiv preprint arXiv:1804.03343, 2018.
SFFAI招募
现代科学技术高度社会化,在科学理论与技术方法上更加趋向综合与统一,为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!

历史文章推荐:



