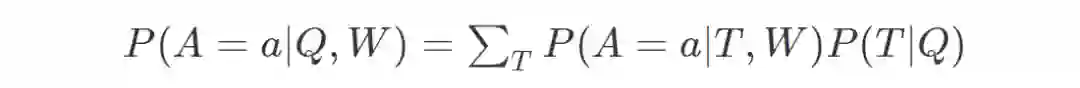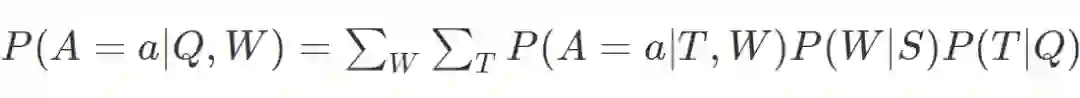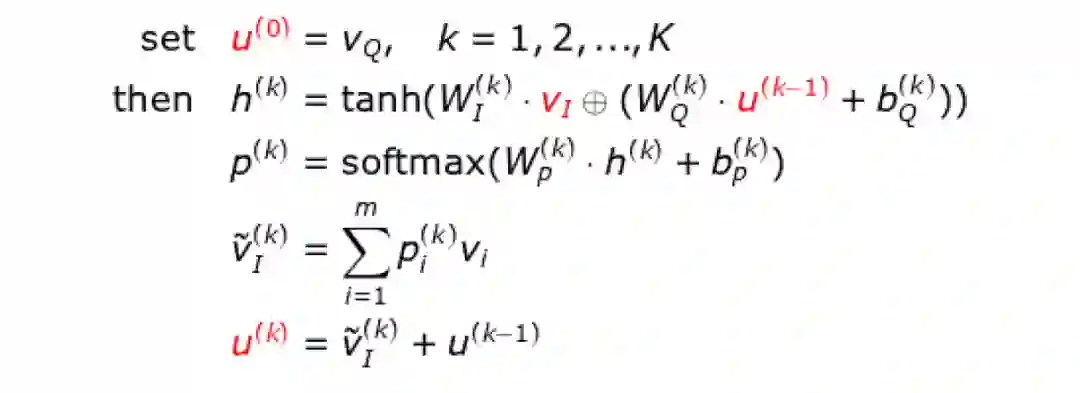![]()
本文从视觉问答(VQA)任务出发,讲述了 2015 年任务的定义开始,接踵出现的各种多模态技术。
从无注意力机制的深度学习模型,发展到天然适合注意力机制的多模态场景的模型,再到基于 Transformer 模型的即将到来的多模态领域大一统模型。其中,穿插了一些有趣的技术梳理,比如非深度学习技术和工程型优化的技术等。
笔者利用课余时间收集整理,耗时一年撰写本文章,经历了三个版本迭代,旨在为同学们入门多模态预训练大模型领域提供一些力所能及的帮助。经过对多模态领域模型与方法演化进程的梳理,笔者认为这一领域的研究前景较为乐观,如果未来真的会有“大一统模型”,那么它将出现在多模态领域。
粤港澳大湾区数字经济研究院(IDEA研究院)实习研究博士生
清华大学2021级客座学生、早稻田大学博士生(指导老师:杨余久、酒井哲也)
张家兴博士现任 IDEA 研究院认知计算与自然语言研究中心(简称“IDEA CCNL”)讲席科学家兼负责人,携 IDEA CCNL 科研团队建设了“封神榜”大模型体系,并致力于推动以预训练大模型为代表的新一代认知计算与自然语言技术的进一步发展及其产业落地。他于 2006 年北京大学博士毕业,曾任微软亚洲研究院研究员、蚂蚁金服资深算法专家、360 数科首席科学家。张家兴博士是大数据框架、深度学习框架、深度学习算法的早期开创者和实践者,引领深度学习在工业界场景中落地,在金融领域产生广泛影响力。他在自然语言处理、深度学习、分布式系统、物理等领域的顶级学术会议和期刊(NIPS, OSDI, CVPR, SIGMOD, NSDI, AAAI, WWW...)上发表二十余篇学术论文,提交七十余项专利。
https://github.com/wanng-ide/VQA_to_multimodal_survey
欢迎来到多模态的世界!本文主要是对 VQA 任务以及延伸至多模态领域做一个综述,而非专业论文,旨在整理所见所闻以帮助同学快速了解该领域的发展和脉络。
1. Visual Question Answering using Deep Learning: A Survey and Performance Analysis
https://arxiv.org/abs/1909.01860
2. Visual Question Answering: A Survey of Methods and Datasets
https://arxiv.org/abs/1607.05910
3. Survey of Visual Question Answering: Datasets and Techniques
https://arxiv.org/abs/1705.03865
4. 视觉问答-1_综述.md
https://github.com/shengnian/Algorithm_Interview_Notes-Chinese/blob/master/B-自然语言处理/D-视觉问答-1_综述.md
5. Visual Question Answering: Datasets, Algorithms, and Future Challenges
https://arxiv.org/abs/1610.01465
● 更多其他有趣的论文
-
-
-
-
重新规划了文章结构把VQA相关数据集转移到了下游任务章节中
-
十万年前的非洲大草原上,当一个智人压低声音对他的同伴说:“小心,远处有只狮子。”一个多模态认知任务随即产生了。眼中看到的各种图像块,耳中听到的“小心”、“远处”、“狮子”这些音节,在智人的大脑皮层中,构建出了一个意义,指导着他的行动。不能完成这个任务的智人,被狮子吃掉了,没能跨越进化的槛并淹没在了历史洪流之中。因而,今天地球上的人类,都是多模态认知的大师,这些大师通过五感接收信息,依赖着大脑中一百多亿个神经元认知周围的意义。那么机器呢?机器要如何通过多模态认知这个世界?
认知是一种计算。生物大脑中,神经元突触之间传递的电脉冲信号,神经元与胶质细胞之间的互动,是一种连续空间中的计算。而数字计算机里二进制状态通过逻辑门的变换,是一种离散空间中的计算。尽管存在于离散空间的通用图灵机并不能完成世间所有的计算,但我们仍旧相信实现了通用图灵机的数字计算机,可以进一步实现认知的计算。
计算存在于一种结构。人的大脑从最基础的图像块和音节开始,从下到上逐步计算,构建了图像和语言各自的意义,最后又在大脑皮层中进行了多模态的整合。生命在亿万年的进化中,找到了进行多模态认知计算的结构。那么机器的多模态认知计算结构该是怎样?
近 10 年深度学习的发展,让我们探索出越来越好的计算结构。在一个图像中,像素和图像块在二维平面用他们的相对位置表达着意义,因此对图像的理解也可以对应着一个二维计算结构。受到生物视觉神经系统的启发,逐层处理图像块的卷积神经网络(CNN)被提出。在新世纪第二个十年,卷积神经网络在强大算力的支撑下,推动了计算机视觉技术的应用落地,并且创造了一个 AI 产业。
不同于图像的二维结构,句子是由一个个词语构成的一维结构,专门处理序列的循环神经网络(RNN)通常被用来处理语言,但是这种古老的计算结构显然已不再胜任语言这种有信息层级的任务。从 2018 年开始,一种新计算结构 Transformer 迅速地取代了循环神经网络。Transformer 作为新世纪第一个被提出的基础计算结构,超越了它的前辈卷积神经网络和循环神经网络,用注意力结构代替了曾经的卷积和循环结构,并且从语言扩展到图像,成为了认知智能统一的底层计算结构。
统一的计算结构带来了更多的好处,多模态的融合也终于可以在一个计算结构中进行。认知计算结构的变迁,是新的技术范式取代旧的范式,新的计算结构 Transformer 带来的全面优势,吸引了几乎全部研究和应用的注意力,而旧的计算结构(CNN, RNN)只能去寻找它们适合的其他应用领域。
认知能力依赖于多任务学习。生物在亿万年的进化中,解决了无数个任务,不能解决关键任务的生物个体,就像那个被狮子吃掉的智人,其后代无法存活于这个世界。我们想让机器具备多模态认知能力,也必须为机器构造包含图像和语言的各种学习任务,恢复句子中掩蔽的词(MLM)、恢复图像中被掩蔽的图像块(MAE)、匹配图像和文本(ITM)。
新的计算结构也使得我们在构造学习任务上有了更多的选择。在机器学习的过程中,当深度神经网络逐渐越来越好地完成了这些学习任务,也就意味着它逐步具备了多模态认知的能力。但随着神经网络结构越来越大,构造并完成这些学习任务所需要的数据和算力也越来越大。
终于,认知智能与生物面临了同样的挑战:学习和进化的成本。一万个智人被狮子吃掉,才会诞生一个学会俯下身的聪明智人。那一万个被吃掉的智人,就是生物进化的成本。
让机器具备多模态认知的能力,同样需要巨大的算力成本。我们当下的技术水平,是否已经准备好去迎接这一变革了呢?或许某一天,脑科学的进步,新算力形式的出现,甚至能源技术和太空技术的重大突破,都有可能让机器追上生物40亿年的进化,超越人类对图像和语言的多模态认知能力。
若干年后的非洲大草原,背着猎枪的智人向他的机器人伙伴压低声音说“小心,远处有只狮子”。机器人俯下身子,却突然开始思考:“为什么狮子会沦落成人类的猎物?”然后,机器人轻轻地站了起来,向狮子挥了挥手......
——张家兴
粤港澳大湾区数字经济研究院(福田)
认知计算与自然语言研究中心 讲席科学家
![]()
VQA 介于图像理解(CV)和自然语言处理(NLP)的交集。VQA 任务的目的是开发出一种系统来回答有关输入图像的特定问题。答案可以采用以下任何形式:单词,短语,二元答案,多项选择答案或文本填空。
在 CV 领域,CNN 是当前非常重要的基础模型。进而产生了 VGGNet,Inception,ResNet 等模型。类似的,NLP 领域,RNN 是之前主要的模型架构,因为 LSTM 的引入使得 RNN 有了重大突破。如 Vanilla VQA 模型使用了 VGGNet 和 LSTM 相结合的方法。后来在 NLP 领域的注意力机制(Attention Mechanism)也开始在 CV 领域开始得到应用。就有了 Stacked Attention Network 等。
2018 年 BERT 横空出世,在 NLP 领域掀起了革命。所以近两年,BERT 也开始进入到 VQA 任务中,BERT 一开始是用于替换 RNN 来处理文本。但是在 2019,2020 年开始,一些模型(如,VL-BERT)开始把简单有效的 Transformer 模型作为主干并进行拓展,视觉和语言嵌入特征可以同时作为输入。然后进行预训练以兼容下游的所有视觉-语言联合任务。
![]()
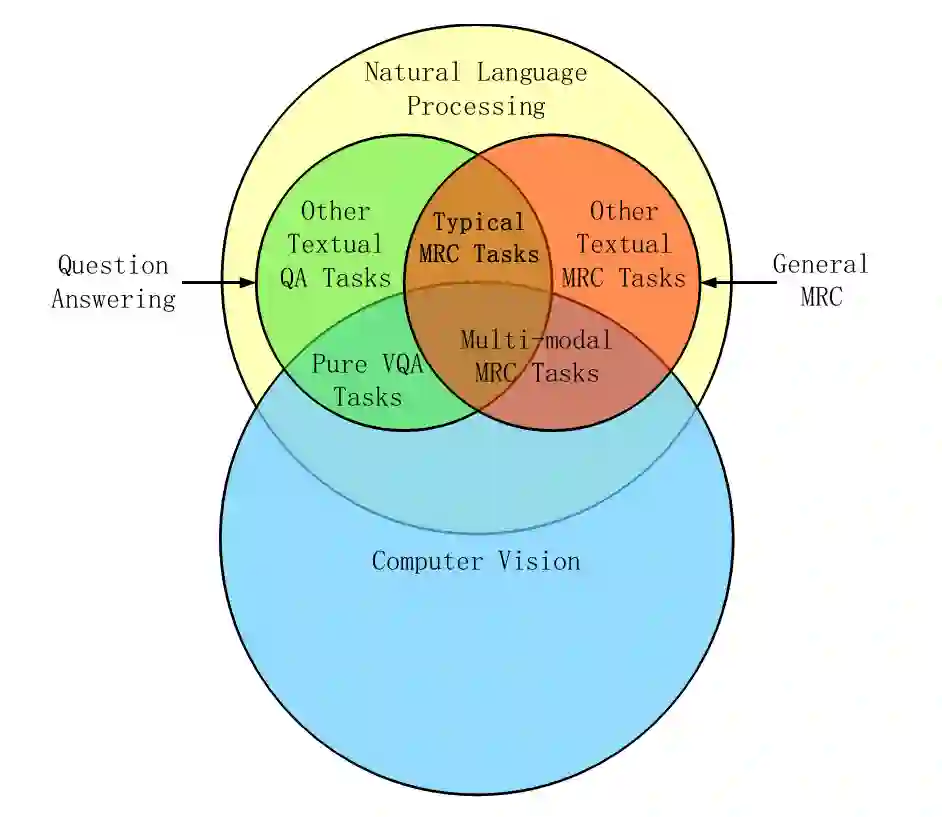
其中,machine reading comprehension(MRC)和 question answering(QA)的关系其实是相对独立的。在本图中,Pure VQA 任务一般是
没有引入额外的 context
,只是单纯的有 {图,问句,回答}。而 Multimodal MRC 任务,实际上就只是引入了额外的 context 作为 VQA 任务的知识,并且
更加注重于自然语言的理解
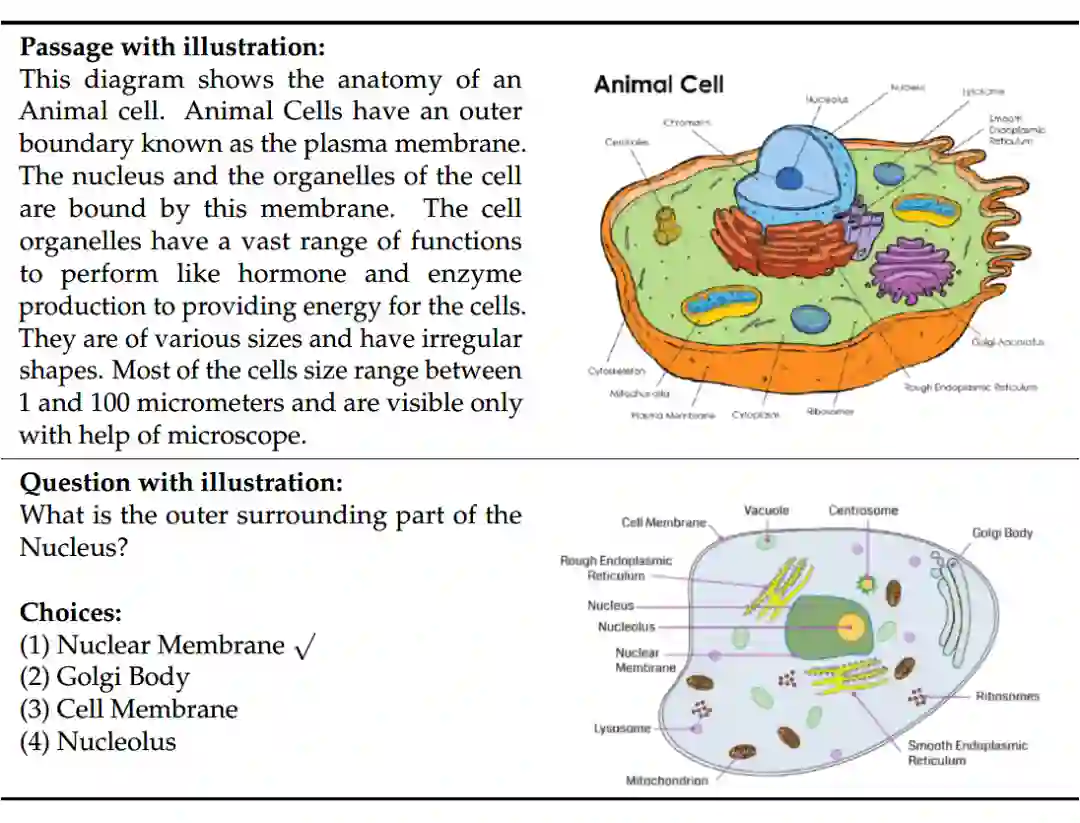
。下图可以给出一个来自 TQA 数据集的例子。(该数据集主要来自课本)
![]()
既然讲到了 MRC 不妨提一下,MRC 的主要任务类型一共有四种,分别为完形填空(Cloze Style)、多项选择(Multiple Choice)、片段抽取(Span Prediction)和自由作答(Free-form Answer)。大多数现有的 MRC 任务都是文本问题解答任务,因此将这种机器阅读理解任务视为典型的机器阅读理解任务(Typical MRC)。
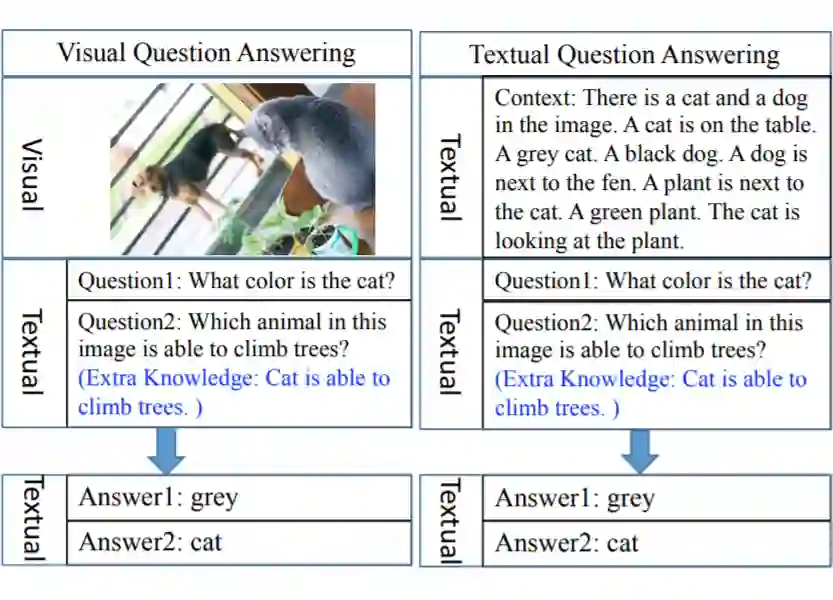
关于 VQA 和 Textual Question Answering(TQA)的不同,主要是数据集信息形式的不同。
![]()
● VQA 的总体目标是从图像中提取与问题相关的语义信息,从细微物体的检测到抽象场景的推理。
● 大多数 CV 任务都需要从图像中提取信息,但与 VQA 相比都存在某些局限性。
● 但是实际上,由于 VQA 中问题会提供一定的场景,在这个场景下,答案的粒度是一定的。并且是
有明确的
答案,所以相对来说 VQA 的评价要相对简单一些。
对象识别、动作识别和场景分类都可以被定义
为图像分类任务
,现在最好的方法是使用 CNN 进行训练,将图像分类为特定的语义类别。
-
对象识别
一般只需要对图像中的主要对象进行分类,而不用理解其在整个场景中的空间位置或作用。
-
目标检测
通过对图像中每个对象实例放置一个边界框来定位特定的语义概念。
-
语义分割
通过将每个
像素
分类为一个特定的语义类,使定位的任务更进一步。
-
实例分割(Instance segmentation)
用于区分同一语义类的不同实例。
![]()
其中主要的问题在于
标签歧义(label ambiguity)
-
比如上述图中
“黄叉”
的位置取
"bag"、"black"、"person"
之一都没有问题。
-
-
此外,目前的主流方法(CNN+标签)不足以理解物体在整个场景下的作用(role)
-
比如,将“黄叉”位置标记为"bag"不足以了解该包与人的关系;或者标记为"person"也不能知道这个人的状态(跑、坐、...)
除了 VQA 外,图像描述(image captioning)是另一个比较主流的、需要结合 CV 和 NLP 的任务。图像描述任务的目标是对给定图像生成相关的自然语言描述。
结合 NLP 中的一些方法(RNN 等),生成描述有不同的解决方案。
-
一些自动评价方法:BLEU、ROUGE、METEOR、CIDEr
-
这些方法中,除了 CIDEr,最初都是为了评价机器翻译的结果而提出的。
-
这些方法每一个都存在一些局限性,它们常常将由机器生成的标题排在人工标题之前,但从人的角度看,这些结果并不够好,或者说不是目标描述。
评价的一个难点在于,给定图像可以存在许多有效的标题,这些标题可以比较宽泛,也可能很具体。
如果不加限制,图像描述系统总是倾向于生成
得分更高
的表述。
-
比如 "A person is walking down a street" 或 "Several cars are parked on the side of the road" 这些普适的描述总是会得到较高的排名(Rank)。
-
事实上,一个简单图像描述系统,只要使用 KNN 等方法找到与给定图像比较相似的图像,并把它们的描述返回就能在部分评估指标下得到不错的分数。
![]()
现在都是基于深度学习了,但是这里依然写上,主要是为了时候可以用这些方法来改进深度学习模型或者是有什么别的未发现的点。
2.1.1 回答类型预测Answer Type Prediction(ATP)
Answer-Type Prediction for Visual Question Answering
https://readpaper.com/paper/2442626797
https://www.chriskanan.com/wp-content/uploads/Kafle2016.pdf
(Kafle and Kanan,2016)提出了 VQA 的贝叶斯框架,其中他们预测问题的答案类型并使用它来生成答案。可能的答案类型因其考虑的数据集而异。例如,对于 COCO-QA,他们考虑四种答案类型:对象,颜色,计数和位置。
-
他们的模型根据图像 x 和问题 q 计算出答案 a 和答案类型 t 的概率。
-
-
他们使用 ResNet 来处理图像,并跳级思考向量(skip-thought vectors)来处理文本。
-
然后,利用贝叶斯算法对目标的空间关系进行建模,计算出每个答案的概率。
-
是较早的 VQA 解决方案,但其有效性不如简单的基线模型;部分原因在于其依赖语义分割的结果。
2.1.2 多元世界问答 Multi-World QA
A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input
https://readpaper.com/paper/2951619830
https://arxiv.org/abs/1410.0210
(Malinowski and Fritz,2014)这篇论文将基于问题和图像的答案概率建模为
![]()
这里 T 为隐藏变量,它对应于从问题语义分析器(semantic parser)得到的语义树(semantic
tree)。W 是世界,代表图像。它可以是原始图像或从分割块获得的附加特征。使用确定性评价(deterministic evaluation)函数来评估 P(A|T,W)。使用简单的对数线性模型得到 P(T|Q)。这个模型被称为 SWQA。
作者进一步将其扩展到多元世界的场景,用来模拟分割和分类标签的不确定性。不同的标签代表不同的 W,所以概率模型为
![]()
这里,S 是带有类标签分布的一组分割图像集。因此,从分布中抽样分割图像时将得到其对应的一个可能的 W。由于上述方程很复杂,作者仅从 S 中抽样固定数量的 W。
2.2 无注意机制的深度学习模型 Non-attention Deep Learning Models
VQA 的深度学习模型通常使用卷积神经网络(CNN)来嵌入图像与循环神经网络(RNN)的词嵌入(word embedding)来嵌入问题。这些嵌入以各种方式组合和处理以获得答案。
Simple Baseline for Visual Question Answering
https://readpaper.com/paper/2190656909
https://arxiv.org/abs/1512.02167
Github:
https://github.com/metalbubble/VQAbaseline
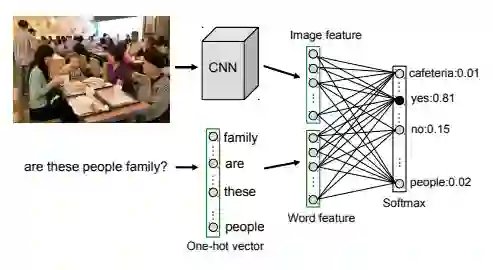
(Zhou,2015)提出了一种叫做 iBOWING 的基线模型。他们使用预训练的 GoogLeNet 图像分类模型的层输出来提取图像特征。问题中每个词的词嵌入都被视为文本特征,因此文本特征是简单的词袋(bag-of-word)。连接图像和文本的特征,同时对答案分类使用 softmax 回归。结果表明,该模型在 VQA 数据集上表现的性能与几种 RNN 方法相当。
![]()
作者的灵感来源于早期的一篇文章,BOWIMG baseline(Bag-of-words + image feature)在 COCO 数据集上的效果要比 LSTM 要好一些,但是在更大一些的 COCO VQA 数据集上,BOWIMG baseline 却表现比 LSTM 更糟。基于此,作者提出了 iBOWIMG 模型。
-
Learning rate and weight clip(学习率和权值截取):作者发现设置不同的学习率和权值截取对于词嵌入和 softmax 都有性能的提升。在词嵌入层的学习率要高于 softmax 的学习率。
-
Model parameters to tune(模型参数微调):需要调整的有 3 个参数,训练的 epoch,权值截取和学习率,低频 QA 的阈值。
Learning to Answer Questions From Image Using Convolutional Neural Network
https://readpaper.com/paper/1606748815
https://arxiv.org/abs/1506.00333
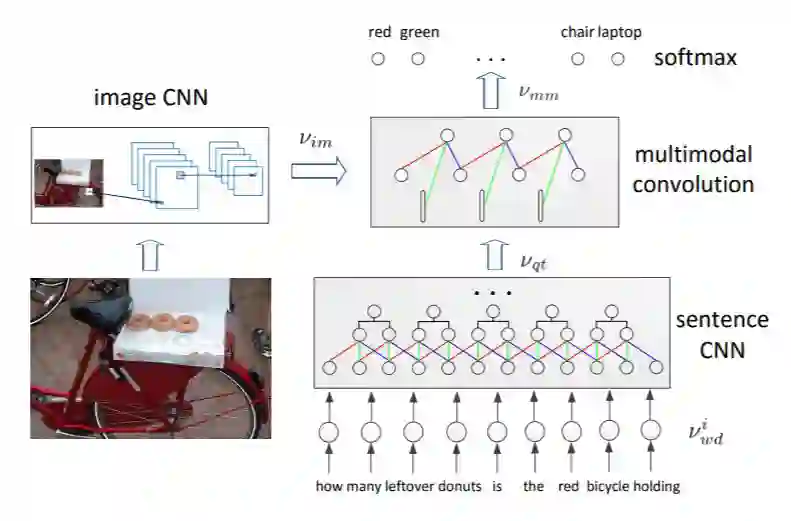
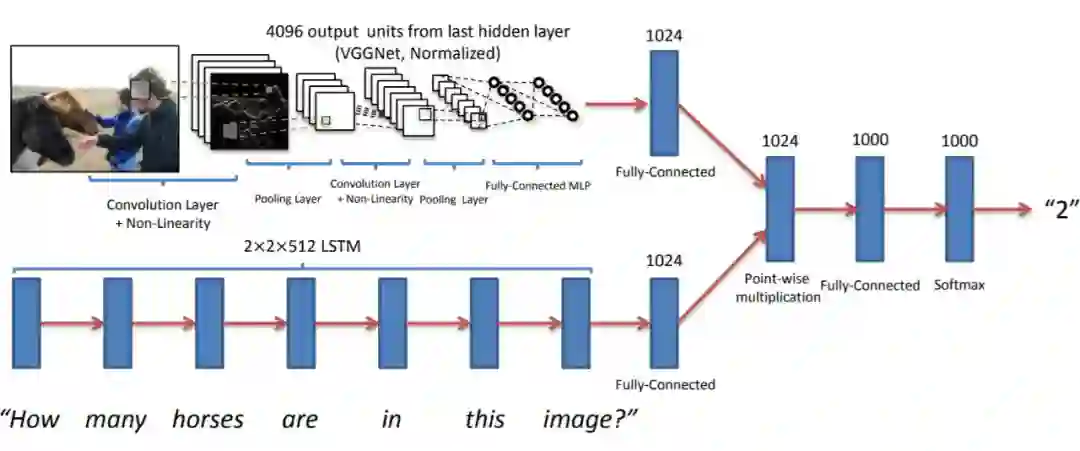
(Ma,2015)提出了一种仅用 CNN 的模型,称为 Full-CNN。模型使用三种不同的 CNN。
![]()
图像 CNN 使用与 VGG 网络相同的架构,并从该网络的第二层获取长度为 4096 的向量。这通过另一个完全连接的层,以获得大小为 400 的图像表征向量。
句子 CNN 涉及 3 层卷积和最大池化(max pooling)。卷积感受野(receptive field)的大小设置为 3。换句话说,核函数(kernel)会计算该词及其相邻的邻居。
联合 CNN 称为多元模态 CNN(multi-modal CNN),在问题表征上的卷积感受野大小为 2。每个卷积运算都在完整的图像上进行。将多元模态 CNN 的最终表征结果传入 softmax 层以预测答案。
2.2.3 神经元询问 Ask Your Neurons(AYN)
Ask Your Neurons: A Deep Learning Approach to Visual Question Answering
https://readpaper.com/paper/2963981422
https://arxiv.org/abs/1605.02697
Github:
https://github.com/mateuszmalinowski/visual_turing_test-tutorial
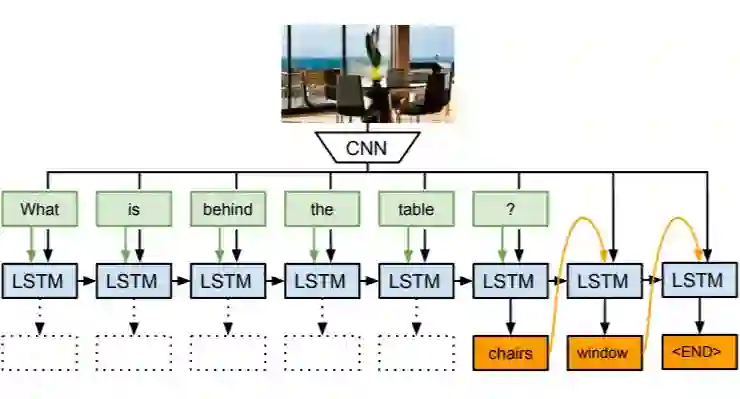
(Malinowski, 2016)以 CNN 和 LSTM 为基础,以一种新的使用方式,设计了一个预测结果长度可变的模型。该模型将视觉问答任务视为结合图像信息作为辅助的 sequence to sequence 任务。
首先由一个预训练好的深度 CNN 模型抽取出要回答的图片特征,然后将图片特征和转化为词向量的问题词一起送入 LSTM 网络,在每次送入一个问题词的同时将图片特征送入网络,直到所有的问题特征信息抽取完毕。接下来用同一个 LSTM 网络产生答案,直至产生结束符 ($) 为止。该模型的训练过程是结合图像特征的 LSTM 网络的训练以及词向量的生成器的训练。
![]()
解码答案可以用两种不同的方式,一种是对不同答案的分类,另一种是答案的生成。分类由完全连接层生成输出并传入覆盖所有可能答案的 softmax 函数。另一方面,生成由解码器 LSTM 执行。在每个时间点的 LSTM 将前面生成的词以及问题和图像编码作为输入。下一个词使用覆盖词汇表的 softmax 函数来预测。需要注意的一点是,该模型在编码器和解码器 LSTM 之间共享一些权重。
Exploring Models and Data for Image Question Answering
https://arxiv.org/abs/1505.02074
https://readpaper.com/paper/1575833922
Github 1:
https://github.com/abhshkdz/neural-vqa
Github 2:
https://github.com/renmengye/imageqa-public
Github 3:
https://github.com/VedantYadav/VQA
论文(Ren et al., 2015)有以下几点贡献:
-
提出一个 end-to-end QA 模型,这个模型利用 visual semantic embedding 连接 CNN, RNN。
-
提出一个自动问题生成算法,这个算法可以将描述图像的句子转化为问题
-
![]()
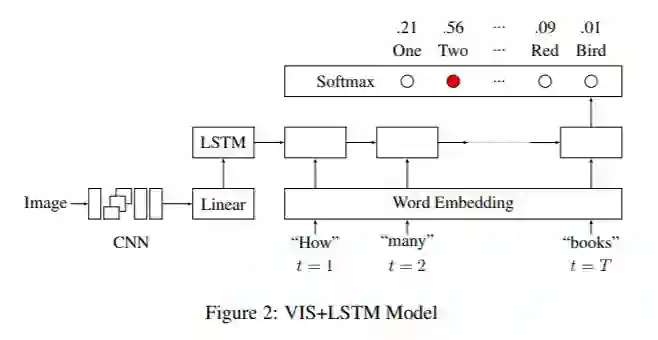
该模型与 AYN 模型非常相似。该模型使用 VGG Net 的最后一层隐藏层作为visual embeddings,并且在训练期间保持 CNN 不变。与之前的模型相反,在编码问题之前,它们将图像编码作为第一个“词”传入 LSTM 网络。该 LSTM 的输出先通过完全连接层,然后通过 softmax 层。
作者还提出了一种使用双向 LSTM 的 2Vis+BLSTM 模型。向后的 LSTM 也将图像编码作为第一个输入。两个 LSTM 的输出相连接,然后通过一个 dense 和 softmax 层。
一共四个模型:
2.2.5 Vanilla VQA(deeper LSTM Q + norm I)
说老实话,这个模型的名字只有在"Visual Question Answering using Deep Learning: A Survey and Performance Analysis"
这里看到过。实际上应该是在论文"VQA: Visual Question Answering"
中所描述的 "deeper LSTM Q + norm I"。
Visual Question Answering using Deep Learning: A Survey and Performance Analysis
https://arxiv.org/abs/1909.01860
VQA: Visual Question Answering
https://arxiv.org/pdf/1505.00468.pdf
Github:
https://github.com/GT-Vision-Lab/VQA_LSTM_CNN
![]()
-
词袋问题(BoW Q)问题和答案的第一个单词有很强的相关性。选择前 30 个创建一个词袋。
-
LSTM Q 具有一个隐藏层的 lstm 对 1024 维的问题进行嵌入。对对每一个问题字进行编码,采用全连通层 + tanh 将其进行 300 维嵌入,然后供给 LSTM。
-
deeper LSTM Q:使用具有两层隐藏 LSTM 将问题进行 2048 维嵌入,然后利用全连通层 + tanh 非线性函数将 2048-dim 嵌入变换为 1024 维。
多层感知机:将图像和问题结合。首先通过全连通层 + tanh 非线性将图像嵌入变换为 1024-dim 来匹配问题的 LSTM 嵌入。转换后的图像和 LSTM 嵌入(在公共空间中)然后通过元素的乘法进行融合。
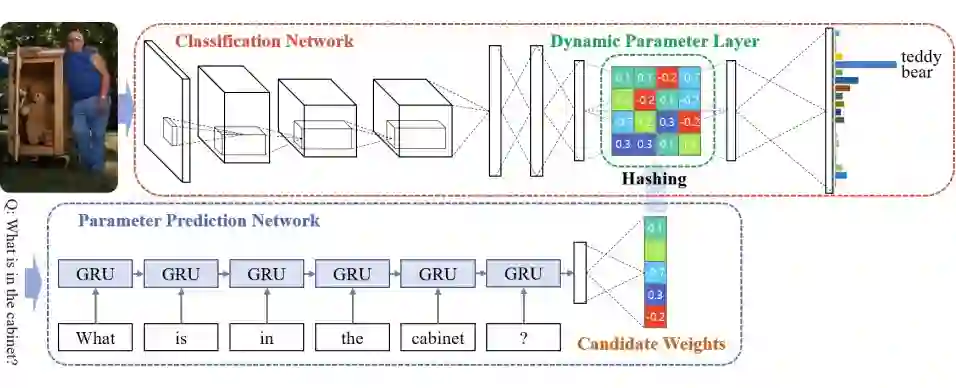
2.2.6 动态参数预测 Dynamic Parameter Prediction(DPPnet)
-
CNN(VGG-16 -> 3 fully-connect + DPN)
RNN(GRU)
Image Question Answering using Convolutional Neural Networ with Dynamic Parameter Prediction
https://readpaper.com/paper/2964138017
https://arxiv.org/abs/1511.05756
项目主页:
http://cvlab.postech.ac.kr/research/dppnet/
Github:
https://github.com/HyeonwooNoh/DPPnet
-
采用 CNNc+DPN 处理 ImageQA 任务,DPN 的参数根据给定问题动态生成
-
-
通过在一个大的文本集上 fine-tune GRU,提升网路的泛化性能
-
首次同时在 DAQUAR, COCO-QA, VQA 上进行实验
![]()
作者认为,设定一组固定参数并不足以满足 VQA 任务。他们采用 VGG-16 网络架构,删除最终softmax 层,并添加三个全连接层,并最后使用覆盖所有可能答案的 softmax 函数。这些完全连接层的第 2 层没有固定的一组参数。
相反,参数来自 GRU 网络。该 GRU 网络用于对问题进行编码,并且 GRU 网络的输出通过完全连接层给出候选参数的权重小向量。然后使用逆哈希函数(inverse hashing function)将该向量映射到第 2 个全连接层所需的参数权重大向量中。这种哈希(hashing)技术被用于避免预测全部的参数权重而带来的计算成本高昂,并避免由此导致的过拟合。或者可以将动态参数层视为将图像表征和问题表征相乘得到的联合表征,而不是传统的以线性方式组合。
2.3 基于Attention的模型Attention Based Models
对于 VQA 任务,注意机制模型聚焦在图像、问题或两者的重要部分,从而有效地给出答案。
例如,如果问题是“球是什么颜色的?”那么需要更加集中球所包含的图像区域。同样,在问题中,需要集中“颜色”和“球”这两个词,因为它们比其他的词更具信息性。
VQA 中,使用基于空间的 Attention 机制来创建特定区域的 CNN 特征,而不像基线模型中那样直接使用全局特征。
Attention 背后的基本思想是,图像中的某些视觉区域和问题中的某些单词对于回答给定的问题比其他区域或单词更能提供更多的信息。
相关论文:Edge Boxes: Locating Object Proposals from Edges
https://pdollar.github.io/files/papers/ZitnickDollarECCV14edgeBoxes.pdf
主要的想法:学习语言和视觉区域的非线性映射将特征纳入 共同的潜在空间以确定相关性。
Where to look: Focus regions for visual question answering
https://readpaper.com/paper/2179022885
https://arxiv.org/abs/1511.07394
![]()
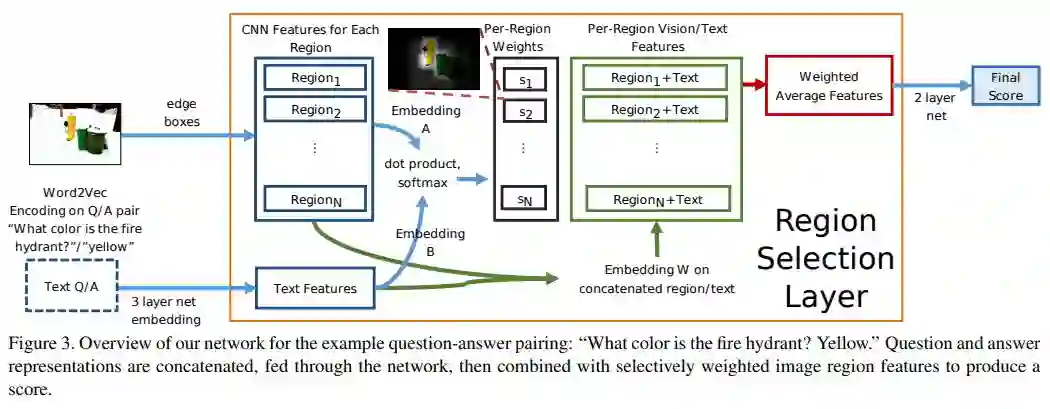
概括:where to look(Shih, 2016)的地位有点相当于 VQA 方向 attention 的始祖 第一次提出了基于 QA 的图像 region attention 因为文章为 2015 的比较早 因此使用方法还存在不少瑕疵:具体做法为该网络只适用于 mc 类型的 VQA 输入 QA 对,并置提取特征。图像过边缘检测得 100 分区,过 cnn 得特征、将每个 region 的向量与 QA 特征向量作内积得 attention 系数权值。最后与文本特征并置加权求和得 weighted average features。然后过两个层得 score,训练时的 loss (hinge loss)。
通过 edge boxes(边缘检测)预训练网络得到 top99 region,然后全图算第 100 个 region(注意:其中联合重叠阈值设定决定了区域的大小) 本 task region 稍微小点好。作者猜测增加 region number 可能能够提升性能。用的 VGG,取的最后一个隐藏层 4096d 和前一个 softmax 层 1000d 并置共 5096d 因为 1000 那个包含物体类别信息。
Step2: Language representation:
首先将每个 word 通过 Google News dataset 进行预训练的 w2v 得到单词 representation(相同词有相近的向量特征是 open-ended 前提)之后通过 4 个 Bin 得到四种 question sentence representation(而不是 LSTM)。
Bin1:问题前两个词特征的平均
Bin2:主语名词特征
Bin3:其他所有名词特征的平均
Bin4:去掉限定词和冠词之后的剩余词特征的平均
-
Bin1+Bin2+Bin3+Bin4+answer representation=1500维 这就是整个的representation
Step3:Image 特征和 QA 特征都 FC 降维到 900 然后点积后 softmax 成 region probability
Step4:最后的向量 z 过一个两层的 fc 后输出一个 score 然后利用 Hingeloss 返回梯度
1. 为什么这里 bow 比 lstm 好?
2. bin 的方式为什么是前两个词?
2.3.2 循环空间注意 Recurrent Spatial Attention(R-SA)
CNN
RNN(LSTM)
Spatial Attention
Visual7W: Grounded Question Answering in Images
https://readpaper.com/paper/2962749469
https://arxiv.org/abs/1511.03416
在文中,(Zhu, 2016)对这个模型的命名为 Recurrent QA Models with Spatial Attention。
![]()
(Zhu, 2016)在两个方面比上一个模型(WTL)超前一步。首先,它使用 LSTM 对问题进行编码,其次,在扫描问题的每个词之后,它重复地计算图像的注意值。
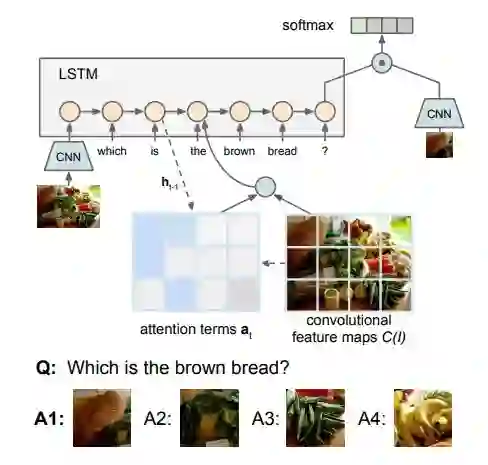
2.3.3 堆叠注意网络 Stacked Attention Networks(SAN)
Stacked Attention Networks for Image Question Answering
https://readpaper.com/paper/2963954913
https://arxiv.org/abs/1511.02274
主要想法:在 VQA 任务中,按照人为的思路,先定位到自行车,再定位到自行车的篮子,最后看篮子上是什么。这是个推理的过程。所以用分层注意力机制来模拟这个过程。
![]()
概括:(Yang, 2016)采用 attention 机制来实现这种分层关注的推理过程。在问题特征提取和图像特征提取的思路并没有很特殊,采用 LSTM,CNN 网络来提取特征。然后用问题特征去 attention 图像,用 attention 的结果结合问题向量再次去 attention 图像,最后产生预测。
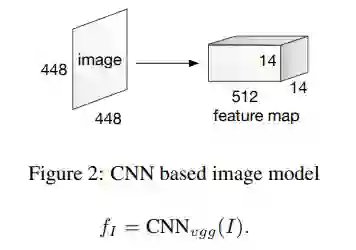
模型提取 VGG19 最后一个 Pooling 层的 feature map 作为区域特征,其大小为14*14*512。相当于把原始 4448*448 的图像均匀划分为 14*14 个网格(grid),每个网格使用一个 512 维的向量表示其特征。(14*14 是区域的数量,512 是每个区域向量的维度,每个 feature map 对应图像中 32*32 大小的区域。)
![]()
对于复杂的问题,单一的 Attention 层并不足以定位正确的答案预测区域。本文使用多个 Attention 层
迭代下列过程。
![]()
![]()
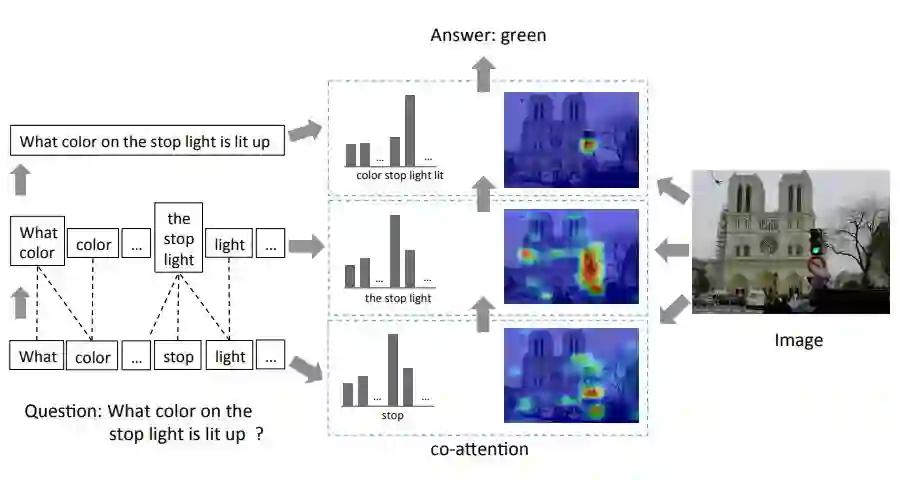
2.3.4 层次协同注意 Hierarchical Co-Attention model
Hierarchical Question-Image Co-Attention for Visual Question Answering
https://readpaper.com/paper/2463565445
https://arxiv.org/abs/1606.00061
![]()
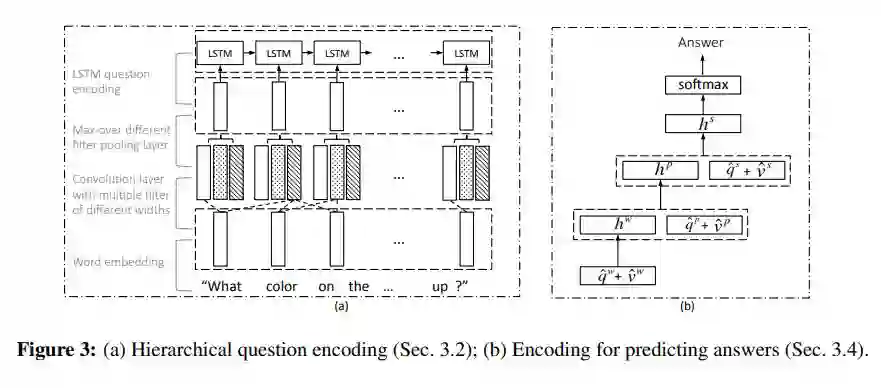
(Lu, 2016)进一步细化了问题,基于词、短语、句子三个层级分别构建 Attention 权重。
-
word-level feature:问题映射到一个向量空间,换成词向量
-
phrase-level feature:利用 1-D CNN 作用于 Qw,在每个单词位置计算单词向量和卷积核的内积,卷积核有三个 size,unigram,bigram and trigram。
-
question-level feature:将得到的 max-pooling 结果送入到 LSTM 中提取特征。全部过程如下图。
![]()
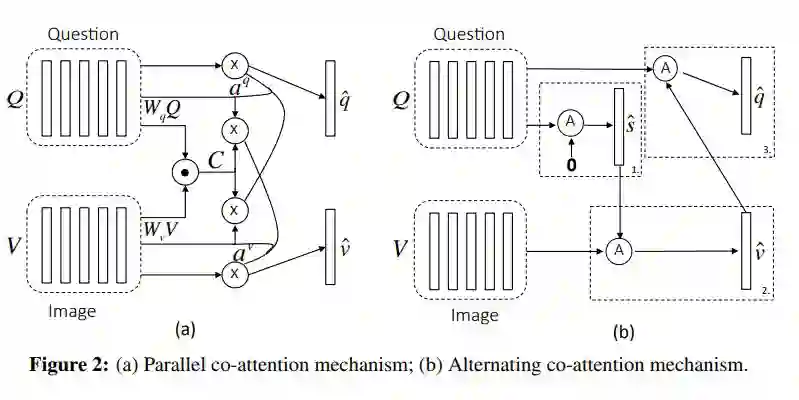
两种 Attenion 机制:parallel co-attention 和 alternative co-attention:
-
parallel co-attention 同时关注问题和图像
-
alternative co-attention 同时在关注问题或图像间交替进行
-
最终的答案通过由低到高依次融合三个层级的特征来预测
![]()
Dual Attention Networks for Multimodal Reasoning and Matching
https://readpaper.com/paper/2546696630
https://arxiv.org/abs/1611.00471
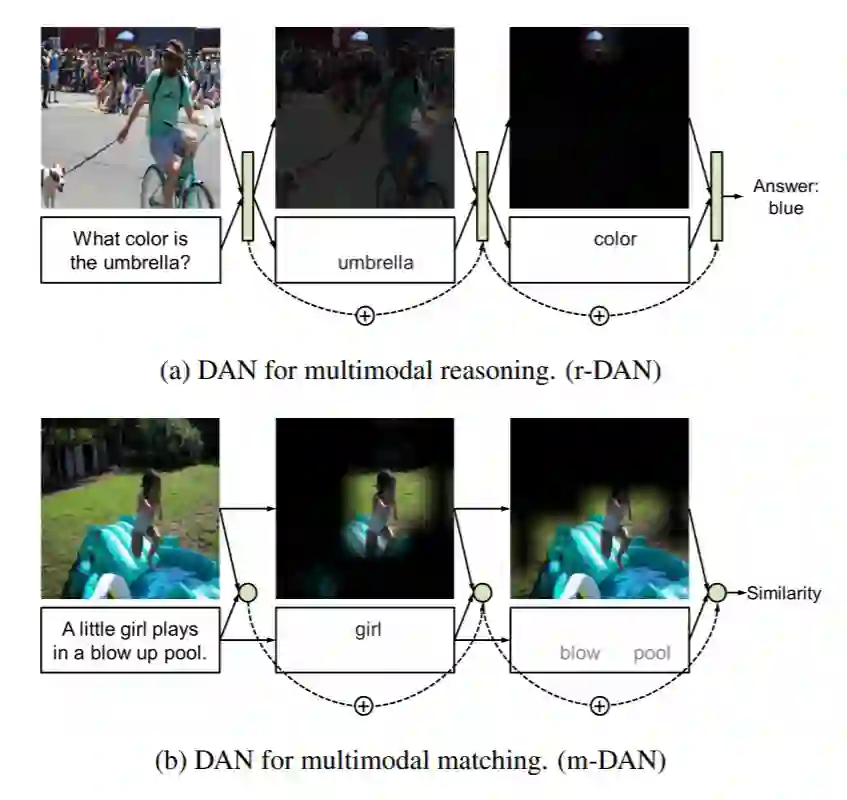
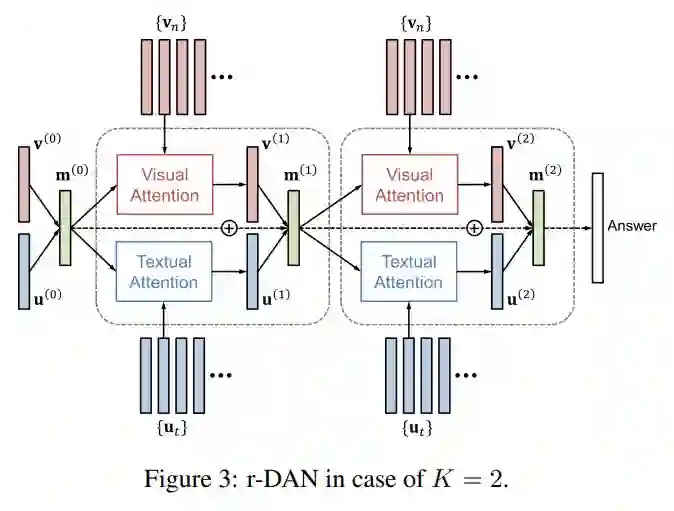
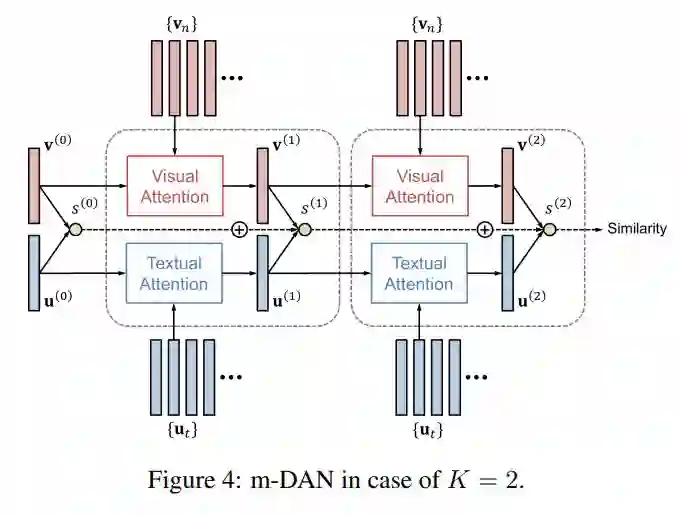
主要思想:(Hyeonseob Nam, 2017)引入两种类型的 DANs(r-DAN用于多模式推理,m-DAN 用于多模式匹配)进行多模态推理,匹配以及分类。推理模型允许可视化并在协作推理期间用文本注意机制互相关联。
![]()
Image representation 图像特征:
从 19 层 VGGNet 或 152 层 ResNet 中提取的。我们首先将图像重新缩放到 448×448 并将它们输入到 CNN 中。为了获得不同区域的特征向量,我们采用 VGGNet(pool5)的最后一个池化层或 ResNet 最后一个池化层(res5c)的下面一层。
Text representation 文本特征:
使用双向 LSTM 来生成文本特征:提取出 T 个文本特征
Visual Attention:分别将初始化的图像特征向量(在 r-DAN 中为前一层的 memory vector 即前一层图像特征与文本特征的点乘)和图像的特征用两层前馈神经网络(FNN)相连,然后再用 tanh 激活并做点乘,然后用 softmax 做归一化得到权重向量(N 维向量),利用权重向量将 N 个 2048 维的向量做加权平均,然后再乘以一个权重矩阵,最后再用 tanh 进行激活,得到图像 attention 向量。
Textual Attention:将初始化的文本特征向量 query(在 r-DAN 中为前一层的 memory vector 即前一层图像特征与文本特征的点乘)和文本的特征 key 用两层前馈神经网络(FNN)相连,然后再用 tanh 激活并做点乘,然后用 softmax 做归一化得到权重向量(N 维向量),利用权重向量将 N 个 512 维的向量做加权平均,得到文本 attention 向量。
解决了两种不同的问题,都用到了前面的 Attention 机制,但是不同的问题,提出了 r-DAN(用于 VQA)和 m-DAN(用于 Image-Text Matching)两种模型。
● r-DAN for Visual Question Answering
VQA 本质上为分类问题,将图像 attention 特征和文本 attention 特征融合得到 memory vector,做分类任务。
![]()
● m-DAN for Image-Text Matching
图文匹配问题与 VQA 最大的不同就是,他要解决的是一个 Rank 问题,所以需要比对两种特征之间的距离,因此就不能共享一个相同的 Memory Vector。
![]()
Loss Function: Triplet Loss(文章中没有提到 hard 的思想,负样本应该是在 minibatch 里面随机选的)
2.3.6 Tips and Tricks for Visual Question Answering
Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
https://readpaper.com/paper/2745132836
https://arxiv.org/abs/1708.02711
Github:
https://github.com/markdtw/vqa-winner-cvprw-2017
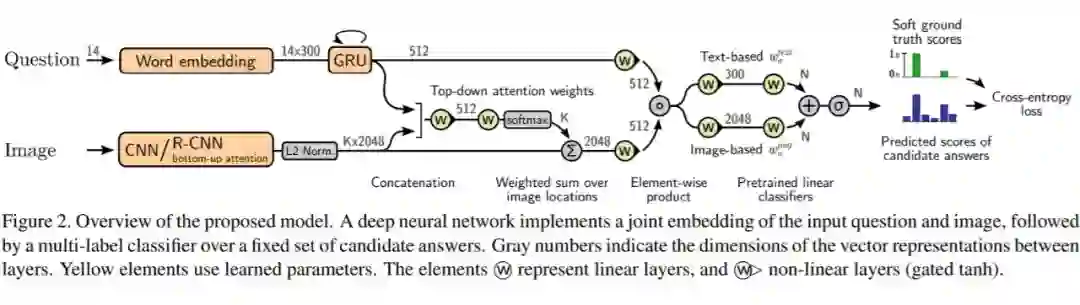
本文章作者(D Teney, 2017)获得了 2017 VQA Challenge 的第一名,花费了 3000 小时的 GPU 运算。为了获得第一名,文中使用了很多技巧来提升性能,但核心出发点都要依赖 joint embedding 和 multi-label classifier 方法来解决 VQA 问题的建模,换句话说就是利用视觉特征和语义特征进行有效融合,然后依赖特征在候选答案上做 multi-label 预测(区别于 softmax 多类预测,形象比喻就是 softmax 最后得到的是 N 类的预测向量,而 multi-label 可以认为是得到预测矩阵,每一行表示对应问题答案的预测向量,当然这只是比喻,并不严谨)。简单说,multi-label 的通常实现方式有两种,一种是 SigmoidCrossEntropyLoss,另一种是使用多个 SoftmaxWithLoss。
![]()
-
使用 sigmoid outputs 来从每个问题中的允许多个答案,替代 single-label softmax;
-
使用 soft scores as ground truth targets 用回归代替分类;
-
使用 image features from bottom-up attention 来针对感兴趣区域提特征,替代之前 grid-like 的方法;
-
使用 gated tanh activations 作为激活函数;
-
使用 pretrained representations of candidate answers 初始化输出 layer 的权重;
-
使用 large mini-batches and smart shffling of training data 来训练。
Question embedding:
采用 GRU 进行编码问题
词向量采用 GloVe 词向量(300 维);词向量中没有的初始化为 0;文本长度用 14 截断;GRU 内部状态为 512。
Image features:
图像特征,有两种方式
-
直接用 cnn:使用预训练的 ImageNet,比如说,200-layer ResNet,得到 772048
-
bottom-up attention:使用 Faster R-CNN framework 提取图像中的 topk 目标。k 可以调节,最大取 100。
Image attention:
图像的 attention,当然了还可以考虑多次 attention、stack 等
Multimodal fusion:
多模态特征融合 joint embedding,采用对应位置相乘的方式,即 Hadamard product。
Output classifier:
把候选答案结合作为输出词典,通过正确答案在训练集上出现 8 次的,放入输出词典中(N=3129)。由于标注的模糊性,训练集有 7% 的问题没有正确答案。实验也发现,对于这是模糊的问题,multi-label 几乎没有预测输出。
Petraining the classifier:
预训练分类器(分类网络初始化)
由于分类网络最后一层是个全连接层,所以最后每个答案的分数就是图片特征和问题特征与网络权重的点积。
作者使用了来自两个来源的候选答案的先验信息来训练:
两种先验信息 W0(text)与 W0(img)互补结合,它们可以用于任何候选答案,包括多义词和生僻词
相关论文2:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
https://readpaper.com/paper/2951590222
https://arxiv.org/abs/1707.07998
Pythia v0.1: the Winning Entry to the VQA Challenge 2018
https://readpaper.com/paper/2884093133
https://arxiv.org/abs/1807.09956
Github 1:
https://github.com/gabegrand/pythia-1
Github 2:
https://github.com/meetshah1995/pythia-1
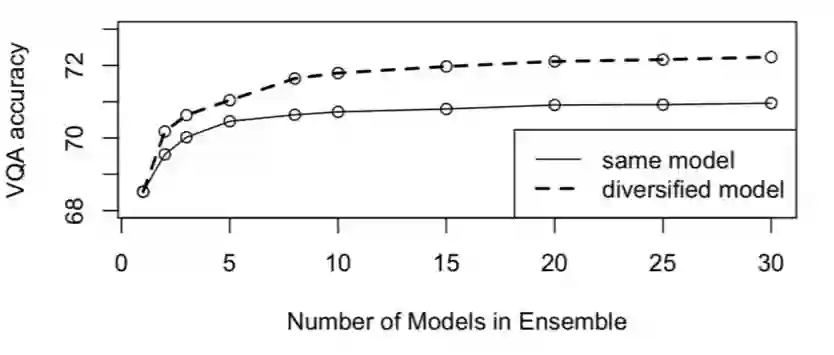
Pythia 以 VQA 2017 Challenge 的冠军模型 Up-Down 为基本方法,辅助以了诸多工程细节上的调整,这使得 Pythia 较往年增加了约 2% 的性能提升(70.34% → 72.25%)。
![]()
-
还记得 Up-Down 里面那个长相奇怪的门控激活函数吗?Pythia 使用了 RELU + Weight Normalization 来取代它,这样可以降低计算量,但是效果上有无提升文中没有给出实验。
-
在进行 top-down 的 attention 权重计算时,将特征整合的方式由原本 concat 转换为 element-wise multiplication,这也是可以降低计算量的表现。
-
在第二个 LSTM 做文本和图像的联合预测时,hidden size 为 5000 最佳。
这里主要是学习率的调整。作者发现在 Up-Down 模型中适当减小 batch 可以带来一些提升,这意味着在同样的 batch 下提升学习率可能带来性能的提升。为了防止学习率过大不收敛,他们采用了广泛使用的 warm-up 策略,并使用了适当的 lr step。
Faster R-CNN 增强:68.05% → 68.49%
将 Faster R-CNN 的 backbone 由 ResNet-101 换为 ResNext-101-FPN,并且不再使用 ROI Pooling 后的 7×7×2048 + mean pooling 表征 object-level 特征,而采用 fc7 出来的 2048 维向量以减少计算量。
采用了图像水平翻转的增强方法,这样的方式在纯视觉任务中广泛出现。在这里还需要做变换的是,将问题和答案中的“左”和“右”对调。
Bottom-up 增强:69.24% → 70.01%
光是使用 Faster R-CNN 在 head network 上的 fc7 特征不足以表示图像整体的特征。于是作者们融合了 ResNet-152 提取的整图特征,并且增加了在每一张图提取 object-level feature 的个数。它们分别带来了可见的提升。
![]()
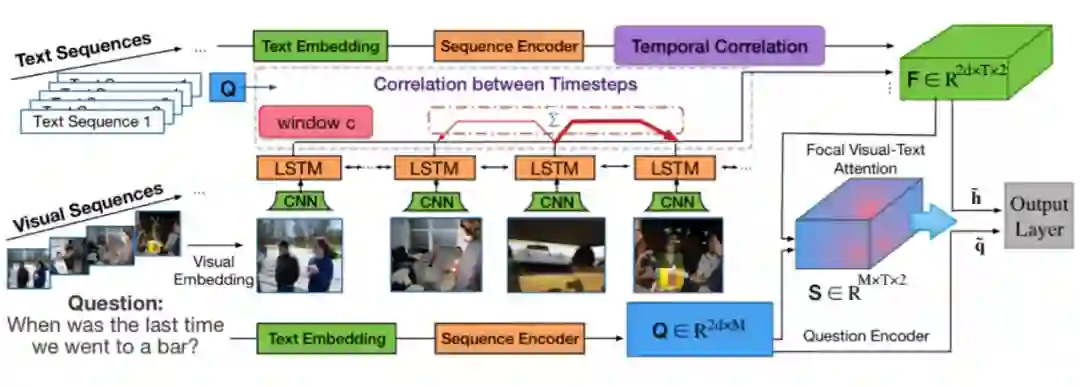
2.3.8 Focal Visual-Text Attention(FVTA)
这项工作(J Liang, 2018)在两个方面不同于现有的基于视频的问答:
(1)基于视频的问答是基于单个视频回答问题,而这个工作可以处理一般的可视文本序列,其中一个用户可能有多个视频或相册。
(2)大多数现有的基于视频的质量保证方法将一个带有文本的视频序列映射到一个上下文特征向量中,而这篇文章通过在每个时间步建模查询和序列数据之间的相关性来探索一个更细粒度的模型。
这项工作可以被视为一个新的关注模型,为多个可变长度的顺序输入,不仅考虑到视觉文本信息,还考虑到时间的依赖性。
Focal Visual-Text Attention for Visual Question Answering
https://readpaper.com/paper/2798786641
https://arxiv.org/abs/1806.01873
Github:
https://github.com/JunweiLiang/FVTA_MemexQA
![]()
Visual-Text Embedding
每个图像或视频帧都用预先训练的卷积神经网络编码。单词级和字符级嵌入都被用来表示文本和问题中的单词。
Sequence Encoder
使用独立的 LSTM 网络分别对视觉和文本序列进行编码,以捕获每个序列中的时间相关性。LSTM 单元的输入是由前一层产生的图像/文本嵌入。
Focal Visual-Text Attention FVTA
是实现所提出的注意机制的一个新层。它表示一个网络层,该层对问题和多维上下文之间的相关性进行建模,并将汇总后的输入输出到最终的输出层。
Output Layer
在使用 FVTA 注意力总结输入之后,使用前馈层来获得候选答案。
不同于前面的模型,下面的模型使用了更多的思想,而不仅仅是在计算图像或问题的注意值方面作改变。
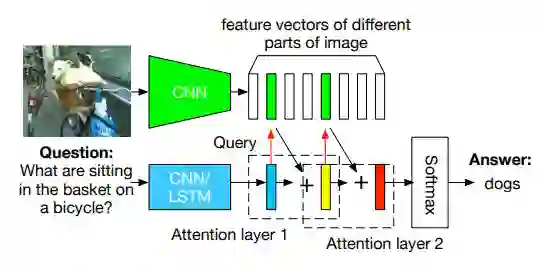
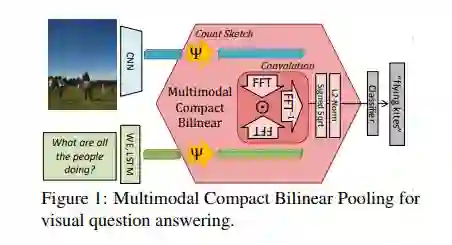
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
https://readpaper.com/paper/2412400526
https://arxiv.org/abs/1606.01847
Github 1:
https://github.com/gdlg/pytorch_compact_bilinear_pooling
Github 2:
https://github.com/akirafukui/vqa-mcb
Github 3:
https://github.com/jnhwkim/cbp
Bilinear pooling 在 2015 年于 "Bilinear CNN Models for Fine-grained Visual Recognition"
被提出来用于 fine-grained 分类后,又引发了一波关注。bilinear pooling 主要用于特征融合,对于从同一个样本提取出来的特征 x 和特征 y,通过 bilinear pooling 得到两个特征融合后的向量,进而用来分类。
(A Fukui, 2016)在 CBP 的基础上提出了 MCBP。
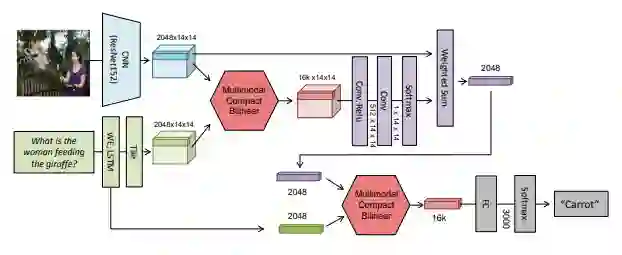
注意到 CBP 是针对 HBP 进行改进的,对 CBP 的 TS 算法稍加改动,使其适用于融合不同模态的特征,即可得到 MCBP,如下图所示。
![]()
文本计算 Attention 的做法类似,区别在于使用 MCB 操作代替双线性 Attention。在得到 MCBP 模块后,作者提出用于 VQA 的网络结构如下:
![]()
这里用到了两次 MCB 模块,第一个 MCB 融合图像特征和文本特征计算图像每个空间位置的 attention weight。第二个 MCB 融合图像特征和文本特征得到答案。
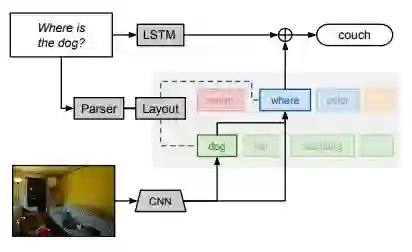
2.4.2 神经模块网络 Neural Module Network(NMN)
https://readpaper.com/paper/2964118342
https://arxiv.org/abs/1511.02799
(J Andreas, 2015)提出的 NMN 的一大特点就是其结构是它并不是像传统的神经网络模型一样是一个整体,它是由多个模块化网络组合而成。根据 VQA 数据集中每个 questions 定制一个网络模型。也就是说 NMN 模型的网络是根据 question 的语言结构
动态生成
的。
![]()
有五种模块:Attention, Re-attention, Combination, Classification 和 Measurement。
![]()
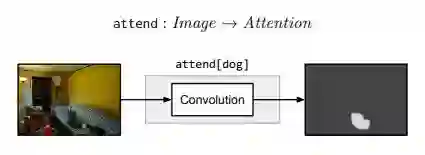
attend 模块将输入图像的每一个位置与与权重(根据 C 的不同而不同)提供一个热力图或一个非标准的注意力图。比如,attend[dog] 模块输出的矩阵,包含狗的区域值较大,而其他区域值较小。
![]()
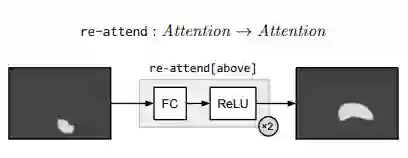
Re-attention 模块本质上由多元感知器及 Relu 实现,执行一个全连接使得将注意力映射到其他地方。re-attend [above] 就是讲 attention 和最佳的软激活区域向上移。
![]()
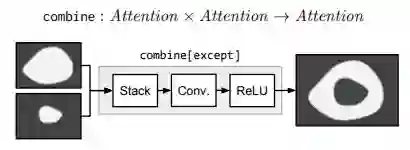
combine 模块将两个 attention 结合成一个 attention。比如,combine 只激活两个输入中都激活的区域,而 except 则是激活第一个输入,将第二个输入失活。
![]()
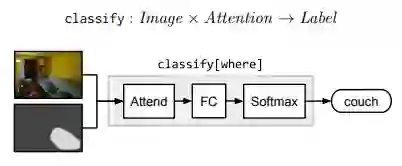
Classification 模块 classify 将 attention 和 image 映射到 labels 的概率分布。它首先计算由注意力加权的平均图像特征,然后通过一个完全连通层传递这个平均特征向量。
![]()
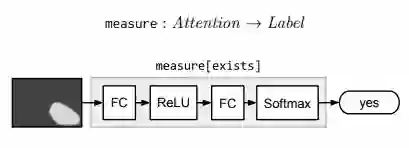
Measure 模块 Measure[c] 以一个 attention 作为输入,映射到 label 的概率分布。由于传递的 attention 是非标准的,所以 measure 模块适合用于评价检测目标是否存在。
已经建立了模块集合,就需要将它们根据不同问题组装成不同的网络布局。从自然语言问题到神经网络实例化有两个步骤。
Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
https://readpaper.com/paper/2963398599
https://arxiv.org/abs/1511.06973
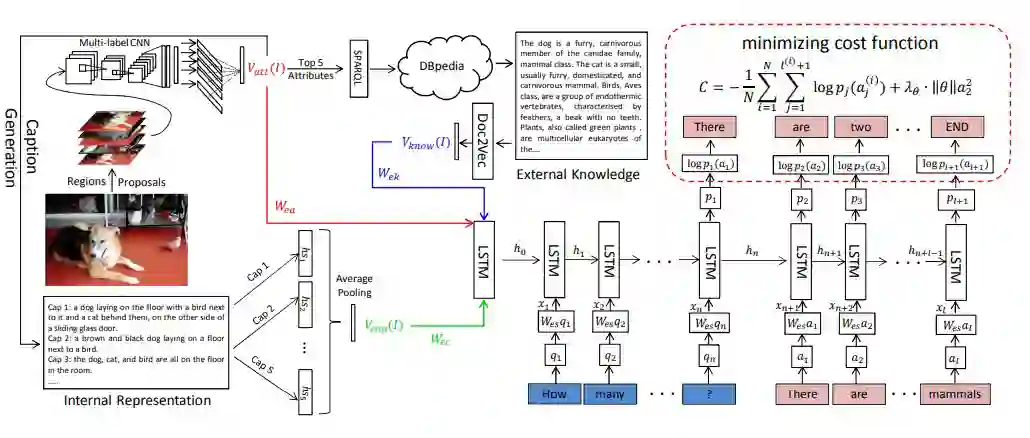
(Wu, 2016)提出了 Ask Me Anything(AMA)模型,该模型试图借助外部知识库中的信息来帮助指导视觉问答。将自动生成的图像描述与一个外部的 Knowledge bases 相融合,对问题进行预测。图像描述生成主要来自于 image captions 集,并且从 Knowledge bases 提取基于文本的外部知识。
![]()
缺点在于仅仅从数据集中提取离散的文本描述,忽略了结构化的表达,也就是说,没有办法进行关系推理,没有说明为什么是这个外部知识,从数据库中找到仅仅是相关的描述。
Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding
https://readpaper.com/paper/2963738360
https://arxiv.org/abs/1810.02338
https://github.com/kexinyi/ns-vqa
主要思想:(K Yi, 2018)提出的神经符号视觉问答(NS-VQA)系统首先会根据图像恢复一个结构化的场景表征,并会根据问题恢复一个程序轨迹。然后它会在这个场景表征上执行该程序以得到答案。
![]()
NS-VQA 模型有三个组件:场景解析器(去渲染器/de-renderer)、问题解析器(程序生成器)和程序执行器。给定一个图像-问题对,场景解析器会去除图像的渲染效果,得到结构化的场景表征(I),问题解析器会基于问题生成层次化的程序(II),程序执行器会在结构化的表征上运行程序从而得到答案(III)。
2.4.5 差分网络 Differential Networks
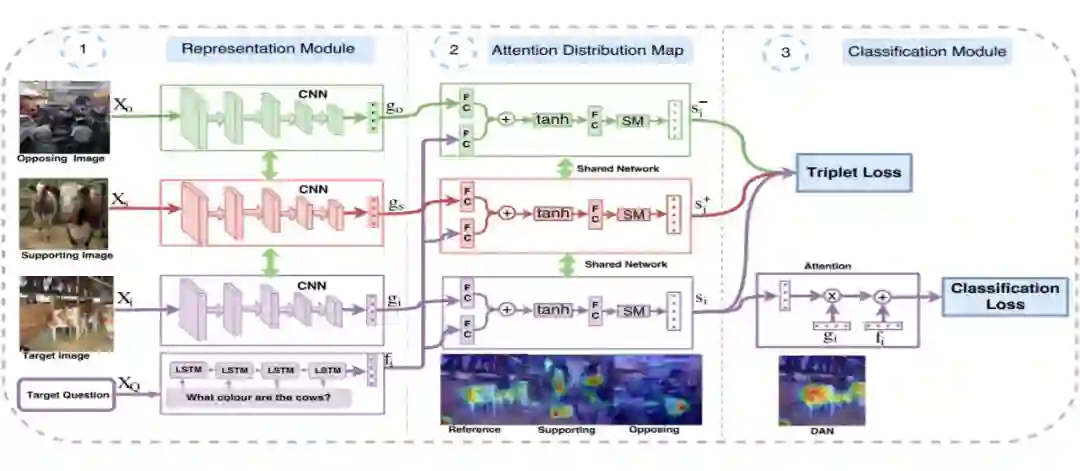
(B Patro, 2018)提出通过一或多个支持和反对范例来取得一个微分注意力区域(differential attention region),与基于图像的注意力方法比起来,本文计算出的微分注意力更接近人类注意力,因此可以提高回答问题的准确率。
Differential Attention for Visual Question Answering
https://readpaper.com/paper/2963466731
https://arxiv.org/abs/1804.00298
-
根据输入图像和问题取得引用注意力嵌入(reference attention embedding);
-
根据该引用注意力嵌入,在数据库中找出样本,取近样本作为支持范例、远样本作为反对范例;
-
-
通过微分注意力网络(differential attention network, DAN)或微分上下文网络(differential context network)分别可以改进注意力或取得微分上下文特征,这两种方法可以提升注意力与人工注意力的相关性;
首先为微分注意力网络(differential attention network, DAN),重点为通过正反例注意力更新目标注意力,使之与人类的注意力更相似。
![]()
然后就是微分上下文注意力(DCN),其主要应用映射的概念,缩小正例与目标注意力之间的距离,删除反例上下文与目标注意力之间的特征,从而达到更新注意力的目的。
![]()
创新点是引入了支持示例和相对示例进而找到与答案相关的区域,进行回答问题。
![]()
![]()
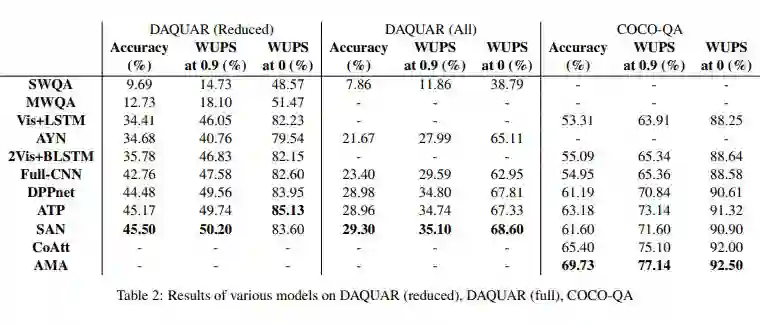
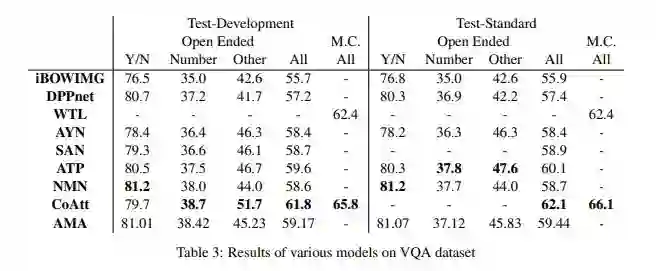
有趣的是,我们看到 ATP 模型的表现优于非注意模型,这证明简单地引入卷积和/或循环神经网络是不够的:原则上识别相关的图像部分是重要的。ATP 甚至可以与一些注意模型(如 WTL 和 SAN)相媲美甚至表现更好。
CoAtt 的表现有显著的提升,该模型首先注意问题然后注意图像。这对于长问题可能是有帮助的,由于这些问题更难用 LSTM/GRU 编码表示为单个向量,因此首先对每个词进行编码,然后使用图像来注意重要的词,这样有助于提高模型的准确率。NMN 模型使用了为每个(图像/问题)对自动组合子模型的新颖想法,它的表现效果类似于在 VQA 数据集上的 CoAtt 模型,但是在需要更高级推理的合成数据集上优于所有模型,表明该模型在实际中可能是一种有价值的方法。然而,需要更多的测试来判断该模型的性能。
在 COCO-QA 数据集上表现最好的模型是 AMA 模型,它包含外部知识库(DBpedia)的信息。这样做的一个可能的原因是知识库帮助解决涉及常识的问题,而这些知识可能不在数据集中。
该模型在 VQA 数据集上的表现不是很好,这可能是因为这个数据集没有太多的问题需要常识。自然地这种模型会为未来的工作带来两大方向。第一个方向是认识到外部知识的必要性:某种 CoAtt 和 AMA 的混合模型加上是否访问知识库的决策器可能会兼有两种模型的优点。该决策器可能是面向应用的,以实现端到端的训练。第二个方向是探索使用其它知识库,如 Freebase、NELL 或 OpenIE 的信息提取。
![]()
PaperWeekly独家周边盲盒
限量 200 份,免费包邮送
周边盲盒将随机掉落
众多读者要求返场的爆款贴纸
炼丹师必备超大鼠标垫
让你锦鲤护体的卡套组合
扫码回复「盲盒」
立即免费参与领取
👇👇👇
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()