本周值得关注的论文主要有:
贾佳亚等推出的利用点云数据进行 3D 目标检测新论文、美国 20 年人工智能技术路线图、目标检测算法回顾,以及一些在变分自编码器、神经架构搜索、目标函数、注意力机制可解释性方面的研究。
2. A 20-Year Community Roadmap for Artificial Intelligence Research in the US
3. Recent Advances in Deep Learning for Object Detection
4. Attention is not not Explanation
5. One Model To Rule Them All
6. AutoGAN: Neural Architecture Search for Generative Adversarial Networks
7. On the Variance of the Adaptive Learning Rate and Beyond
摘要:
在本文中,研究者提出了一种统一、高效率和有效的框架,用于基于点云的 3D 目标检测。
他们提出的两段式方法利用体素表征(Voxel Representation)和原始点云数据来充分发挥各自的优势。
第一阶段网络以体素表征作为输入,仅包含轻量级卷积运算,并生成了少量的高质量初始预测。
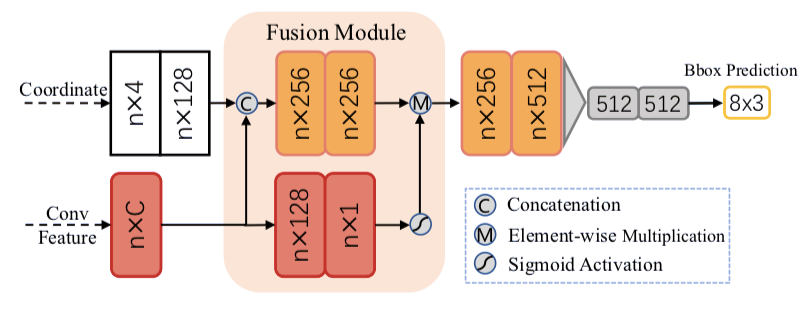
初始预测中每个点的坐标和索引卷积特征实现了与注意力机制的有效融合,并保存了准确的定位和语境信息。
第二阶段网络对内点(interior point)展开融合,以进一步细化预测结果。
本文提出的方法就 3D 和鸟眼观(Bird's Eye View,BEV)检测在 KITTI 数据集上进行了评估,实现了 15FPS 检测率的 SOTA 结果。
![]()
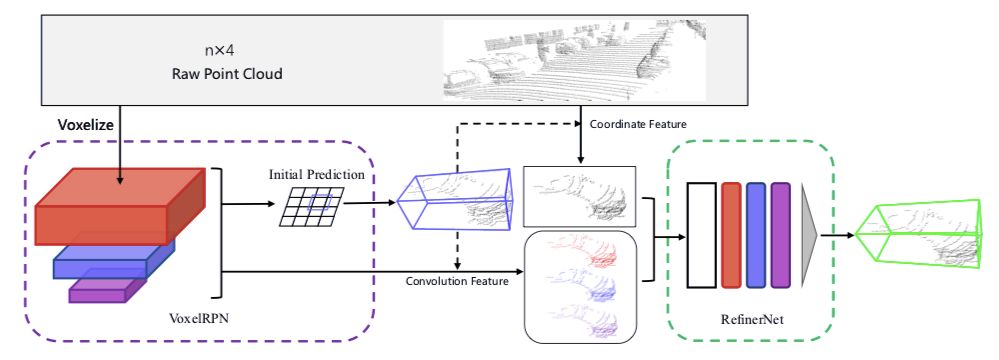
图 1. 两阶段框架概述。
在第一阶段,对点云进行体素化,并将其送入 VoxelRPN,以生成少量的初始预测结构。
然后通过融合体素的内点坐标和上下文特征,生成每个预测的边界框特征。
边界框特征被送入 RefinerNet 以进一步微调。
![]()
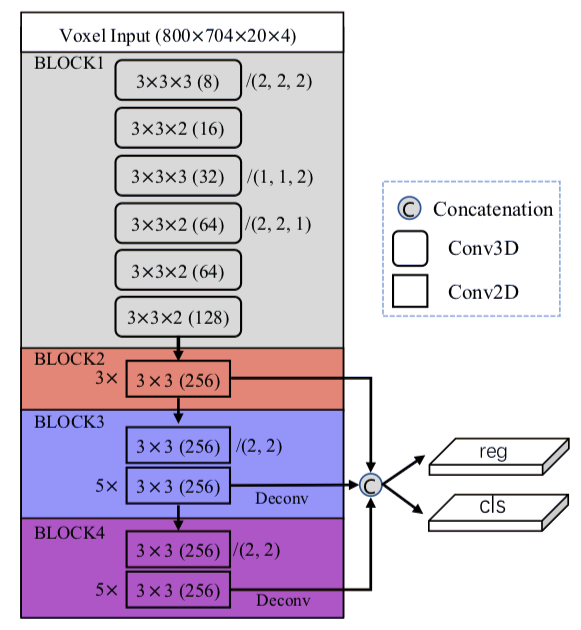
图 2.VoxelRPN 网络结构。
本图中 C 层的级联方式为:
(kernel size)(channels) / (stride)。
stride 默认为 1,除非以其它方式指定。
![]()
推荐:
本文是由港中文和腾讯优图实验室
贾佳亚等人完成的最新论文,实现了点云数据的二阶段 3D 检测
。
论文2:A 20-Year Community Roadmap for Artificial Intelligence Research in the US
摘要:
现在,人工智能可以翻译多种语言、识别图像和视频中的目标、简化制造流程以及控制汽车。
人工智能系统的部署既为业界创造了万亿美元的财富(这一数字预计未来三年将翻三番),也提醒人们需要关注它们的公平性、可解释性和安全性。
未来的人工智能系统理应能够有效地判断出它们(以及人们)所运行的场景,高效并合乎道德地处理复杂任务和承担相应责任,参与有意义的沟通,并通过实践提升自我意识。
充分发挥人工智能技术的潜能需要对人工智能研究企业进行根本性的变革,并通过大量持续的投资加以促进。
这些是美国计算社区联盟(Computing Community Consortium)和人工智能发展协会(Association for the Advancement of Artificial Intelligence)给出的主要建议,从而为未来二十年的人工智能研究和发展制定路线图。
![]()
报告目录。论文介绍了人工智能发展的目标和场景、首要研究问题、数据和硬件问题等。
推荐:
不仅要脚踏实地,也要着眼未来。
20 年后的 AI 怎么发展?
数据、算法、算力、应用落地问题如何解决?
美国计算社区联盟和人工智能发展协会给出了美国未来的技术路线,适合研究科技趋势和未来发展的读者参考。
论文3:Recent Advances in Deep Learning for Object Detection
摘要:
目标检测是计算机视觉中的一个基本视觉识别问题,并在过去几十年中得到了广泛的研究。
视觉目标检测是为了在给定图像中找到具有精确定位的特定目标类目标,并为每个目标实例分配相应的类标签。
基于深度学习的图像分类取得了巨大的成功,因此近年来利用深度学习的目标检测技术得到了积极的研究。
本文综述了近年来基于深度学习的视觉目标检测技术的研究进展。
通过查阅大量近期相关文献,研究者系统地分析了现有的目标检测框架,并分为三个主要部分:
检测组件;
学习策略;
应用与基准。
研究者详细讨论了影响检测表现的各种因素,如检测器架构、特征学习、提案生成、采样策略等。
最后,他们讨论了未来的发展方向,以促进和激励未来利用深度学习的视觉目标检测研究。
![]()
推荐:
目标检测是计算机视觉领域的主要分支领域。
本文回顾了这一领域的研究和发展,向读者全面介绍了相关的解决方案。
论文4:Attention is not not Explanation
作者:Sarah Wiegreffe、Yuval Pinter
论文链接:https://arxiv.org/pdf/1908.04626.pdf
实现地址:https://github.com/successar/AttentionExplanation
摘要:
注意力机制在 NLP 系统中起着重要作用,尤其对于循环神经网络 (RNN) 模型。
那么注意力模块提供的中间表征能否解释模型预测的推理过程,进而帮助人们了解模型的决策过程呢?
一篇题目为《Attention is not Explanation》的论文表示注意力机制并不能提高模型的可解释性。
来自佐治亚理工学院的 Sarah Wiegreffe 和 Yuval Pinter 挑战了这篇论文中的诸多假设,认为该论断依赖「解释」(explanation)的定义,且判断该论断是否正确需要考虑模型的所有元素,使用严谨的实验设计。
因此他们提出四种替代性测试方法来决定注意力何时可用作「解释」、是否能作为「解释」,这四种方法分别是:
简单的统一权重基线、基于多次随机种子运行的方差校准、使用预训练模型固定权重的诊断框架、端到端对抗注意力训练协议。
每一种方法都可以对 RNN 模型中的注意力机制做出有意义的诠释。
研究人员证明,即使存在可靠的对抗分布,它们在简单的诊断框架上也无法取得很好的性能,这表明《Attention is not Explanation》这项研究并没有驳倒「注意力机制可用于解释模型」的说法。
推荐:
所以注意力机制是否可解释?
即使是专业研究者也拿不准了,本文从研究注意力可解释性的方法上入手,提出了新的方法。
不管读者朋友信不信注意力机制是否可解释,论文提出的针对某种架构的研究分析方法论,值得参考学习。
论文5:One Model To Rule Them All
摘要:
论文的研究者提出了一种变分自编码器架构,可以无缝地插入在无监督、半监督和监督学习领域。
研究显示,无标注的数据点不仅可以启发无监督任务,也可以提升分类性能。
反过来,每个标签不仅可以提升分类任务性能,但也可以用于无监督任务上。
论文提出的架构非常简单:
将一个分类层和最高的编码层连起来,然后和解码器的重采样隐层结合。
常规的下界损失用一个在分类层上的监督损失目标补充,并且只用于标注过的数据点。
这样一种简单的架构可以在现有的任何 VAE 架构上进行扩展。
在语境分类任务上,研究人员发现这种方法比直接的监督学习设置性能更好。
推荐:
论文提出了通用于无监督和监督学习的变分自编码器架构,适合在图像处理任务中加入带标注或无标注数据,以提升模型的性能表现。
这种模型性能增强的方法,值得读者参考。
论文6:AutoGAN: Neural Architecture Search for Generative Adversarial Networks
作者:Xinyu Gong 、Shiyu Chang 、Yifan Jiang、Zhangyang Wang
论文链接:https://arxiv.org/pdf/1908.03835v1
实现地址:https://github.com/TAMU-VITA/AutoGAN
摘要:
神经架构搜索(NAS)已经在图像分类和分割任务中显示出一定的成功。
在本文中,研究人员提出了第一种利用神经架构搜索生成生成对抗网络的方法,名为 AutoGAN。
研究人员在论文中将搜索空间定义为生成器架构变体,并使用了一个 RNN 控制器指导搜索过程,并且用参数共享和动态重设的方法加速进程。
奖励则使用了 Inception score,并使用了多级别的搜索策略。
实验验证了 AutoGAN 在无条件图像生成上的表现。
具体而言,研究人员用这一算法发现了一种新的架构,相比于现有的 SOTA GAN 模型具有很大的优势,例如在 CIFAR-10 上取得了新的 FID 分数——12.42,以及 STL-10 上 取得了 31.01 的分数。
![]()
图 1:
RNN 控制器的架构。
在每一个时间步,控制器会输出一个隐层向量,解码为一个运算步骤,以及其对应的 softmax 分类器。
推荐:
继图像分类、预训练模型之后,神经架构搜索又用在 GAN 上了!
这是一个新的架构突破。
论文揭示了 NAS 在深度学习领域的广阔潜力——人们不再需要费心手动设计模型架构,定义搜索空间和策略,一切由模型完成。
论文7:On the Variance of the Adaptive Learning Rate and Beyond
作者:Liyuan Liu、Haoming Jiang、Pengcheng He、Weizhu Chen、Xiaodong Liu、Jianfeng Gao、Jiawei Han
论文地址:https://arxiv.org/abs/1908.03265v1
实现地址:https://github.com/LiyuanLucasLiu/RAdam
摘要:
启发式的学习率预热方式在稳定训练、加速收敛和提升适应性随机目标算法(RMSprop 和 Adam 等)的泛化能力方面取得了一定的成果。
论文中发现了适应性学习率的一个问题——在早期阶段有很大的方差,说明预热起到了方差缩减的作用。
论文进一步地提出了 RAdam,一种 Adam 的变体。
这一算法引入了整流适应性学习率的机制。
在图像分类、语言建模和神经机器翻译方面的实验说明,这一方法是有效且鲁棒的。
推荐:
优化算法也是深度学习的一个研究方向。
新的 Adam 变体方法进一步加快了模型收敛的速度和鲁棒性,有取代 Adam 的可能,fastai 目前已集成。
读者朋友可以了解下这一领域的进展。
![]()