深度学习基础之LSTM

-欢迎加入AI技术专家社群>>
摘要: 序列预测问题曾经被认为是数据科学行业最难解决的问题之一,而LSTM则是解决这类问题的必备法宝。本文作者详细的介绍了LSTM的相关理论知识,并在最后为深度学习爱好者提供了一个小例子切实的体验LSTM。
序列预测问题曾经被认为是数据科学行业最难解决的问题之一。涉及序列问题的包括:预测销售、发现股票市场走势、了解电影情节、了解你的演讲方式、语言翻译、在iPhone键盘上预测下一个单词等等。
随着近年来数据科学的发展,人们发现所有的这些序列预测问题都可以被长短期记忆网络(LSTM)解决。
LSTM在许多方面比传统的前馈神经网络和RNN都有优势,本文的目的是解释LSTM,并使你能够将其用于解决现实生活中的问题。
注意:要阅读本文,你必须具备神经网络的基本知识以及Keras是如何工作的。你可以参考这些文章来理解这些概念:
从零开始理解神经网络
深度学习基础 - 循环神经网络简介
教程:使用Keras优化神经网络(带图像识别案例研究)
目录:
回顾神经网络(RNN)
RNN的限制
RNN改进:长期短期记忆(LSTM)
LSTM的体系结构
Forget Gate
Input Gate
Out Gate
使用LSTM生成文本。
1.回顾神经网络(RNN)
一个简单的机器学习模型或一个人工神经网络可以学习基于许多特征来预测股票价格。虽然股票的价格取决于很多因素,但它也很大取决于前几天的股票价格。实际上对于交易者来说,前几天(或趋势)的这些价值是预测的一个主要决定因素,当然一些公司的重大事项影响是最大的。
在传统的前馈神经网络中,所有的测试都被视为是独立的,没有前几天考虑股票价格。这种时间依赖性是通过递归神经网络实现的。典型的RNN:
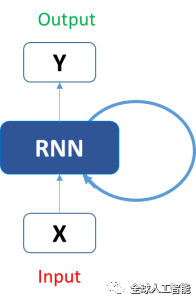
这样看起来可能会有一些困惑,但一旦展开,看起来简单得多:
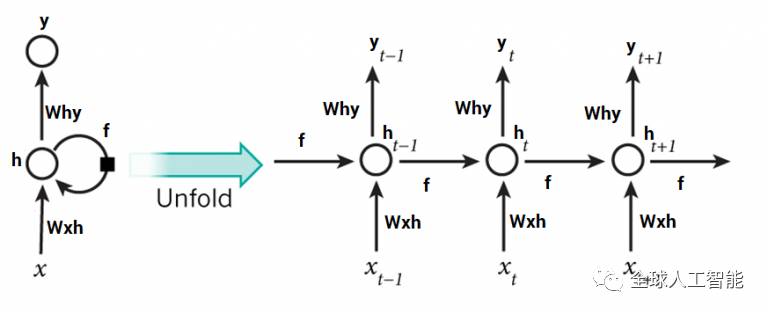
RNN可以很大程度的解决我们序列处理的目的,但并不是完全的。比如,我们希望我们的电脑可以写莎士比亚的十四行诗。RNN在短期时间内表现的非常棒,但要建立一个故事并记住它,如果要模型能够理解和记忆序列背后的背景,就像人脑一样,这对RNN来说是不可能的。
2. RNN的限制
当我们处理短期的依赖性时,递归神经网络(RNN)表现得很好。像这样的问题:

这时RNNs变得相当有效,因为这个问题与上下文无关。RNN不需要记住之前所说的话或者说它的含义,它只需要知道在大多数情况下天空是蓝色的。因此,预测将是:

然而,普通的RNNs并不能了解上下文在预测下一个输出。之前很久以前出现的词,现在做出预测的时候并不能发挥作用。比如这个例子:

在这里,我们人可以理解,由于在西班牙工作了20年,他很可能掌握了西班牙语。但是,为了得到这个预测,RNN需要记住这个上下文。但是遗憾的是,这是RNN失败的地方!
这里面的原因就是梯度消失。为了理解这一点,你需要掌握前馈神经网络学习的一些知识。对于传统的前馈神经网络,在特定层上应用的权重更新是学习率的倍数,来自前一层的误差项以及该层的输入。因此,特定图层的误差项可能是以前所有图层误差的积累。当处理像S形激活函数时,随着我们移向起始层,它的微分值(出现在误差函数中)会倍增倍数。其结果是:随着朝向起始层移动,梯度几乎消失,难以训练这些层。RNN只记得一小段时间的事情,也就是说,如果我们在一段时间之后需要这些信息,它可能是可重复的,但是一旦大量的单词被输入,这些信息就会在某处丢失。
3.对RNN的改进:LSTM(长短期记忆)网络
当我们安排日程时,我们优先考虑约会?如果我们需要为重要的事情腾出空间,我们知道哪个会议可以取消,以满足其他会议的时间。
但RNN不这样做。为了增添一个新的信息,它通过一个函数转换现有的信息。但整个信息总体上都是修改的,即没有考虑“重要”信息和“不那么重要”的信息。
LSTM通过乘法和加法对信息进行小的修改,信息流经称为单元状态的机制。这样,LSTM可以选择性地记住或忘记事物。特定单元状态下的信息有三种不同的依赖关系。
我们用一个特定股票的股价预测解释它,今天的股价将取决于:
股票在前几天走势可能是下跌趋势或上升趋势。
前一天股票的价格,因为很多交易者在购买之前比较股票的前一天价格。
今天可能影响股票价格的因素。这可能是一个新的公司政策,正在被广泛的批评或者公司的利润下降或者是公司高层领导层的意外变化。
这些依赖关系可以概括为任何问题:
之前的单元状态(即在前一时间步骤之后存在于存储器中的信息)。
前一个隐藏状态(即与前一个单元格的输出相同)。
当前时间步骤的输入(即当时正在馈送的新信息)。
4. LSTM的架构
我们可以通过模拟新闻频道的团队的运作情况,将LSTM的功能可视化。一个新闻故事是围绕许多人的事实、证据和陈述而建立的。比方说,我们假设谋杀是通过“毒害”受害人来完成的,但是刚刚出现的尸检报告说死亡原因是“对头部的影响”。作为这个新闻小组,你会做什么?你马上忘记以前的死亡原因和所有围绕这个事实编织的故事。如果一个全新的嫌疑人被引入到图片,一个曾经与受害者勾结,可能成为凶手的人。你一定会将这个信息添到你的新闻源。
现在我们来详细介绍一下LSTM网络的体系结构:
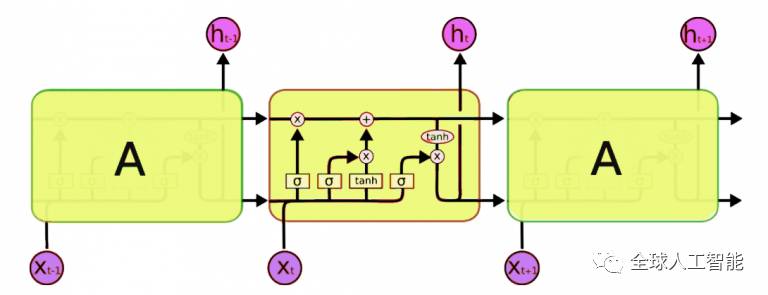
这与我们之前看到的简化版本是完全不同的,典型的LSTM网络由称为单元的不同存储块组成(我们在图像中看到的矩形)。内存块负责记住事物,对这个内存的操纵是通过三个主要的机制来完成的,称为门。
4.1: Forget Gate
我们假设一个LSTM被输入下面的句子:

遇到“ person”之后的第一个句点,Forget Gate就意识到下一个句子中可能有语境的变化。因此,句子的主旨就被遗忘,空间被腾空。而当我们开始谈论“ Dan” 这空间就被分配给了“ Dan”,这个忘记的过程是Forget Gate完成的。
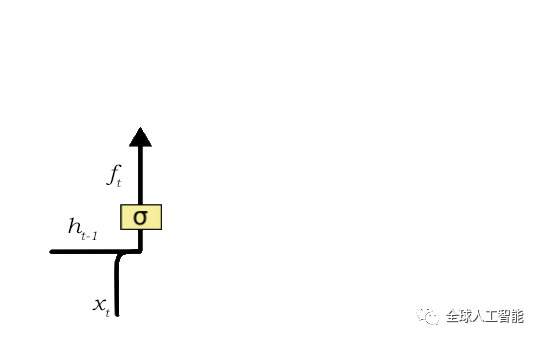
Forget Gate负责从细胞单元中去除信息。这些信息是LSTM不再需要的或不太重要的信息,可以通过滤波器的乘法来消除,这是优化LSTM网络性能所必需的。
这个门接受两个输入:h_t-1和x_t。
h_t-1是前一个单元的隐藏状态或前一个单元的输出,x_t是该特定时间步的输入。给定的输入乘以权重矩阵并添加偏差,之后,sigmoid函数被应用于这个值。sigmoid函数输出一个向量,值范围从0到1,对应于单元状态中的每个数字。基本上,sigmoid函数负责决定要保留哪些值和丢弃哪些值。如果在单元状态中为特定值输出“0”,则意味着Forget Gate要完全忘记该信息。类似地,“1”意味着Forget Gate要记住整个信息。
4.2 Input Gate
让我们再举一个LSTM分析一个句子的例子:

现在这里重要的信息是“Bob”会游泳,他服役了四年的海军。这可以添加到单元状态,但是,他通过电话告诉我这一事实是一个不太重要的事情,可以忽略。添加一些新信息的过程可以通过输入门完成。
这是它的结构:
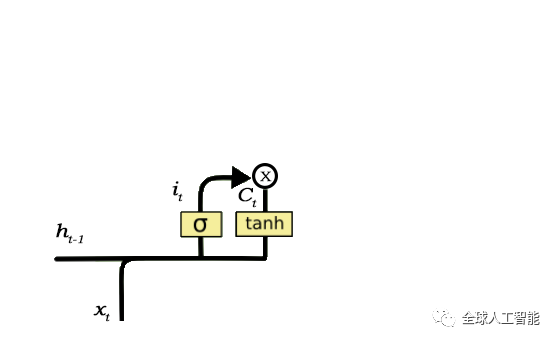
输入门负责将信息添加到单元状态,这个信息的添加基本上是从上图看出的三步过程。
通过sigmoid函数来调节需要添加到单元状态的值。这与Forget Gate基本上非常相似,并且充当来自h_t-1和x_t的所有信息的过滤器。
创建一个矢量,该矢量包含所有可以添加的值(可以从h_t-1和x_t中感知)到单元状态。这是使用tanh函数完成的,该函数输出从-1到+1的值。
将过滤器(sigmoid gate)的值乘以创建的向量(tanh函数),然后通过加法操作将这些有用的信息添加到单元状态。
4.3 Out Gate
并非所有沿着单元状态运行的信息都适合在特定时间输出。我们用一个例子来证实:

在这句话中,我们知道,“Brave”的当前输入是用来形容名词的形容词。因此,无论如何,有一个很强的作为名词的倾向。因此,Bob可能是一个合适的输出。
从当前单元状态中选择有用信息并将其显示为输出的工作是通过输出门完成的。这是它的结构:
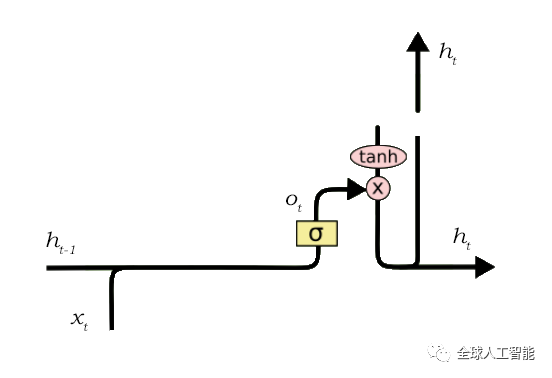
输出门的功能可以再次分解为三个步骤:
在将tanh函数应用到单元状态后创建一个向量,从而将值缩放到范围-1到+1。
使用h_t-1和x_t的值创建一个过滤器,以便它可以调节需要从上面创建的向量中输出的值。这个过滤器再次使用一个sigmoid函数。
将此调节过滤器的值乘以在步骤1中创建的向量,并将其作为输出发送出去,并发送到下一个单元格的隐藏状态。
另外,滤波器需要建立在输入和隐藏状态值上,并应用于单元状态向量。
5.使用LSTM生成文本
我们已经了解了关于LSTM足够的理论概念。现在我们建立一个模型:可以预测Macbeth原始文本后的n个字符。大多数经典文本可以在这里找到,txt文件的更新版本可以在这里找到。
我们将使用Keras,它可以在TensorFlow或Theano之上工作。因此,在深入研究这些代码之前,请确保你已经安装了Keras 。
5.1:导入依赖关系
# Importing dependencies numpy and keras
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.utils import np_utils5.2:加载文本文件并创建字符到整数映射
# load text
filename = "/macbeth.txt"
text = (open(filename).read()).lower()
# mapping characters with integers
unique_chars = sorted(list(set(text)))
char_to_int = {}
int_to_char = {}
for i, c in enumerate (unique_chars):
char_to_int.update({c: i})
int_to_char.update({i: c})文本文件已打开,所有字符都转换为小写字母。为了便于下面的步骤,我们将映射每个字符到相应的数字。这样做是为了使LSTM的计算部分更容易。
5.3:准备数据集
# preparing input and output dataset
X = []
Y = []
for i in range(0, len(text) - 50, 1):
sequence = text[i:i + 50]
label =text[i + 50]
X.append([char_to_int[char] for char in sequence])
Y.append(char_to_int[label])数据准备的格式是,如果我们想让LSTM预测'HELLO'中的'O', 我们会输入['H','E','L','L']作为输入,[' O']作为预期产出。同样,我们在这里修改我们想要的序列的长度(在这个例子中设置为50),然后保存X中前49个字符的编码和期望的输出,即Y中的第50个字符。
5.4:重新塑造X
# reshaping, normalizing and one hot encoding
X_modified = numpy.reshape(X, (len(X), 50, 1))
X_modified = X_modified / float(len(unique_chars))
Y_modified = np_utils.to_categorical(Y)LSTM网络输入的形式是[样本,时间步骤,特征],其中样本是我们拥有的数据点的数量,时间步长是单个数据点中存在的与时间相关的步数,特征指的是我们对于Y中相应的真值的变量数目。然后我们将X_modified中的值在0到1之间进行缩放,并且在Y_modified中对我们的真值进行热编码。
5.5:定义LSTM模型
# defining the LSTM model
model = Sequential()
model.add(LSTM(300, input_shape=(X_modified.shape[1], X_modified.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(300))
model.add(Dropout(0.2))
model.add(Dense(Y_modified.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')使用一个线性堆栈的顺序模型。第一层是具有300个存储器单元的LSTM层,并且它返回序列。这样做是为了确保下一个LSTM层接收序列,而不仅仅是随机分散的数据。在每个LSTM层之后应用一个丢失层,以避免模型过度拟合。最后,我们将最后一层看作一个完全连接的图层,其中' softmax'激活和神经元等于唯一字符数,因为我们需要输出一个热编码结果。
5.6:拟合模型和生成字符
# fitting the model
model.fit(X_modified, Y_modified, epochs=1, batch_size=30)
# picking a random seed
start_index = numpy.random.randint(0, len(X)-1)
new_string = X[start_index]
# generating charactersfor i in range(50):
x = numpy.reshape(new_string, (1, len(new_string), 1))
x = x / float(len(unique_chars))
#predicting
pred_index = numpy.argmax(model.predict(x, verbose=0))
char_out = int_to_char[pred_index]
seq_in = [int_to_char[value] for value in new_string]
print(char_out)
new_string.append(pred_index)
new_string = new_string[1:len(new_string)]该模型需要100训练次数,批量大小为30。然后,我们修复随机种子并开始生成字符。来自模型的预测给出预测字符的字符编码,然后将其解码回字符值并附加到该模式。
这是网络输出的样子:

6.结语
LSTM是序列和时间序列相关问题的一个非常有前途的解决方案。唯一的缺点就是训练难度大,但这只是一个硬件限制。
原文:https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/?spm=5176.100239.blogcont292728.19.A9fcyT

↓↓↓ 点击阅读原文,进入【全球人工智能学院】



