错误的语法会对BERT模型准确性产生影响吗?

近几年,预训练语言模型如 BERT 和 GPT-3,在 自然语言处理(NLP)领域的应用愈发广泛。通过海量文字的训练,语言模型收获了大量关于世界的各类知识,并在多个 NLP 基准上展现了其强大的性能。然而,这些预训练模型往往是不透明的,人们并不知道其优秀表现背后的原因,这限制了模型通过假设驱动的方法来做进一步优化。因此,一个新的科学探索方向出现了:这些模型中到底包含了哪些语言学知识?
在供人们研究的各类语言学知识中,有一个话题可谓是为其他的所有提供了坚实的基础,那就是英语中主谓统一的语法原则。该原则要求句子中谓语动词的在单复数形式上要符合主语的数量,举个例子,
“The dogs run.”
这一句是符合语法规则的,因为“dogs”和“run”都是复数形式。但
“The dogs runs.”
是不符合语法的,因为“runs”是单数形式动词。
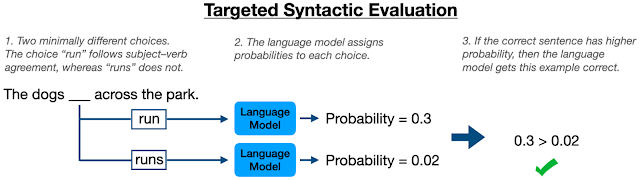
至于评估语言模型的知识掌握程度,可以使用 针对性句法评估(TSE)框架。该框架会通过模型对最少数量成对句子是否符合语法的判定来评估模型的表现。因此,TSE 也可以用于评估模型在英语主谓一致规则的知识掌握,通过输入两个句子,一个中的动词是单数形式,另一个的则是复数形式动词,让模型判断哪个句子符合语法规则。
在上述背景下,作者于 EMNLP 2021 上发表论文,《频率对转换器句法规则学习的影响》,研究了 BERT 模型在预训练时接受的词汇次数,是否会影响其在判断英语主谓一致原则时的表现。为测试具体条件,作者通过一系列仔细调控过的数据集,从头开始训练 BERT 模型。
研究结果发现,BERT 在面对未组对出现在预训练集中的主谓词汇组表现良好,这意味着模型确实学会了如何应用动词的主谓一致形式。然而,如果模型接触错误语法形式的次数远高于正确语法形式,则模型会更倾向于预测错误的动词形式,这代表了 BERT 并未将主谓一致当作是必须遵守的原则。这些结果都将帮助研究者更好地了解预训练语言模型的优势和局限性。
在 先前的研究 之中,也有使用 TSE 评估 BERT 模型在英语主谓一致原则方面的能力。该研究中使用的设置是填空任务,以“the dog _ across the park”为例,BERT 模型会分别给出单数形式动词“runs”和复数形式动词“run”二者的概率。如果模型成功学会主谓一致原则,那么它应经常在语法正确的动词形式上给出较高的概率。
在前期的研究中,BERT 模型的评估使用的是自然语句(取自 维基百科)加上一次性短句(nonce,number only used once 的缩写)的组合,后者指的是在语法上完全合理但句意毫无意义的句子,最著名的例子就是 Noam Chomsky 提出的,“colorless green ideas sleep furiously(无色的绿色想法疯狂睡觉)”。
这类一次性短句在测试模型的句法能力时非常有用,因为它们让模型无法继续依赖表层的语料库统计数据;如果说“dogs runs”比“dogs runs”要常见,但“dogs publish”和“dogs publishes”可是都非常罕见,这让模型不可能靠记住 A 比 B 常见来进行语法判断了。
BERT 模型在一次性短句的测试中达到了 80% 的准确率,远远超过 50% 的随机概率基准线,作者以此证明了模型已学会如何应用主谓一致原则。在论文之中,作者以前期工作为基准,进一步在特定的数据集中对 BERT 模型进行预训练,以便更进一步地探寻结果背后,预训练数据中的一些模式是如何影响模型性能的。
作者首先对比的是,模型在面对预训练时见过原封不动的主语动词(SV)对,和训练时未在同一句式中成对出现过的主语动词对时的表现情况:
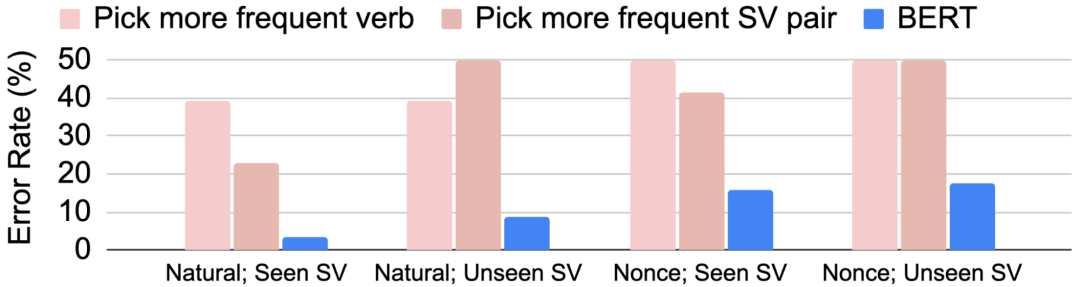
BERT 在面对自然和一次性句式与是否在训练时见过相同句式的错误率对比。BERT 在未曾见过的 SV 对上表现情况远胜简单的启发式方法,如选择更常见的动词或 SV 词对
对于未见过的 SV 词对,BERT 虽在自然和一次性句式上的错误率略有增加,但相比直接选择在预训练数据集中更常见的动词形式或与主语名词更常搭配出现的形式,这类简单的启发式方法要好。
这一现象可以证明,BERT 不仅仅是反映其在预训练中所见过的东西,也不再局限于依据直观词汇出现频率做出判断,模型会将学习到的词对扩展到其他词汇这一点,表明该模型已经可以应用部分主谓一致原则了。
下一步测试的是词汇出现在数据集中的频率是否会影响 BERT 判断主谓一致的表现。
在实验中,作者选择的是一组 60 个动词的数据集,并创建了好几个版本的预训练数据,确保每个版本中这 60 个动词都以特定的频率出现,并且单数与复数形式出现次数相同。通过这些不同版本的数据集训练后,BERT 模型在主谓一致任务中的评估结果如下:
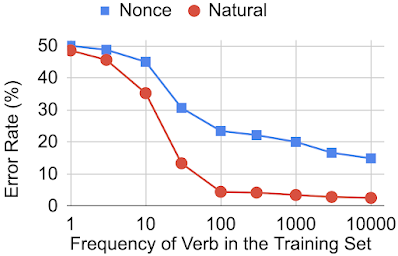
训练集中动词出现频率不同时,BERT 在主谓一致原则任务中的表现
结果表明,虽然 BERT 可以成功学会主谓一致原则,但却需要在训练中见到该动词约一百次后才可正确判断其单复数形式。
最后,作者选择探寻动词单复数的相对频率是如何影响 BERT 的预测。举例来说,如果动词 combat 在预训练数据中出现的频率远胜复数 combats 及其他形式,那么 BERT 是否会选择出现频率更高的形式,即使其在语法上并不正确?
为评估这一点,作者再次使用了包含 60 个动词的数据集,但这一次所创建的版本中,动词的形式之间出现的频率变为了 1:1 到 100:1 间不等。下图展示了 BERT 在这些频率不平衡的预训练数据集中的表现:
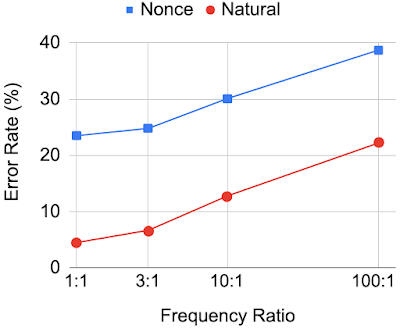
随着训练数据中动词形式出现频率不再平衡,BERT 判断动词语法正确的表现下降
结果显示,如果在预训练时动词两种形式出现频率相同,那么 BERT 的预测准确率非常不错;一旦动词频率不再平衡,BERT 的错误率会随频率比例增加而上升。
这意味着 BERT 虽然已学会应用主谓一致规则,但并不将其视作是必须遵守的原则,它更倾向于选择训练集中高频率出现的动词,即使这些动词形式并不符合主谓一致的语法规则。
除此之外,通过研究词汇出现在训练数据集中的频率与模型预测能力间的关系,展示了 BERT 在处理竞争优先级时的方式:BERT 知道主谓应保持一致,并且语法正确的动词出现频率应更高,但却不理解主谓一致是必须遵循的原则,而动词出现频率仅仅只是数据集的偏好而已。希望这项关于训练数据集对语言模型表现的影响研究能够为诸位提供帮助。
原文链接:
https://ai.googleblog.com/2021/12/evaluating-syntactic-abilities-of.html

你也「在看」吗?👇