在CPU上加速卷积神经网络
在AWS AI,我们发现虽然GPU在深度学习里扮演着重要角色,实际操作中有很多卷积神经网络推理其实都由CPU上完成,无论是在云上还是在终端。经过一番评测,我们认识到没有一款深度学习框架可以在各种主流CPU(包括Intel, AMD和ARM)都高效地进行卷积神经网络推理,主要原因是大家的做法都过于依赖第三方库,再加上框架本身不可避免地带来了一些overhead。为了做一个面向不同CPU,依赖度尽量少的高效模型推理方案,我们把目光投向了深度学习编译器。
当时(现在也是)功能最全社区活跃度最高的开源深度学习编译器是TVM,它可以接受不同框架(Keras/MXNet/TensorFlow/...)的模型并编译到多种设备(CPU/GPU/FPGA/...)上。由于TVM的编译做了不同粒度的优化,在端到端(end-to-end)性能上有时甚至能得到几十倍的加速。TVM发起于华盛顿大学(当时的)在读博士生陈天奇,AWS AI从一开始就在活跃地参与这个开源项目,一直都是TVM社区最大一股的工业界力量。
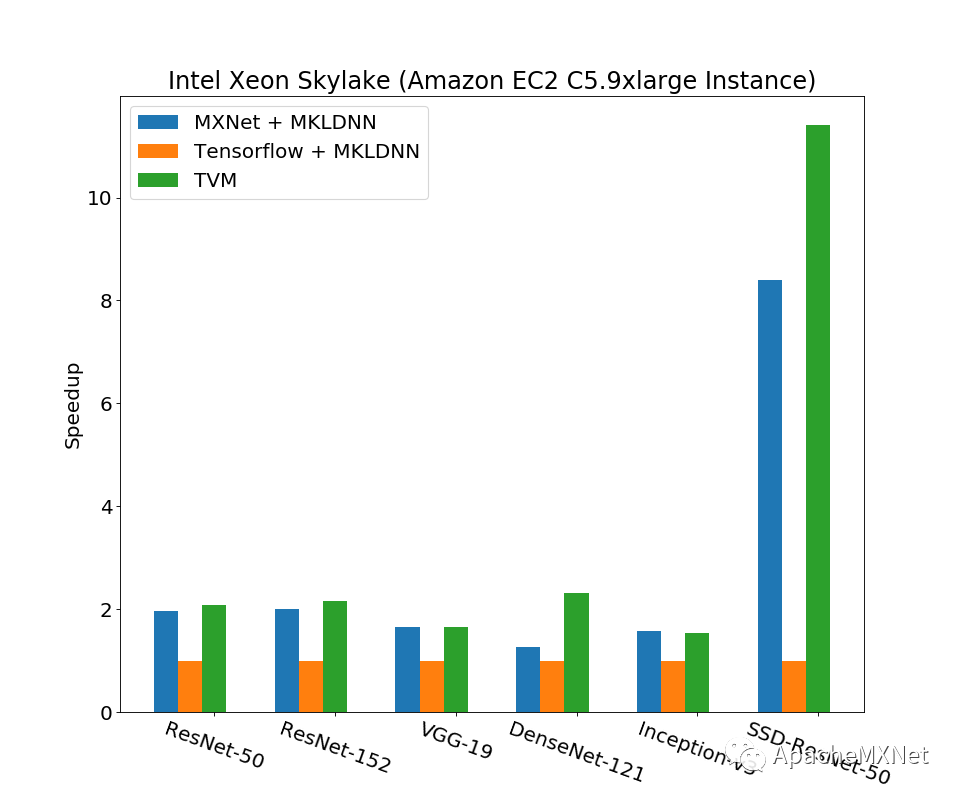
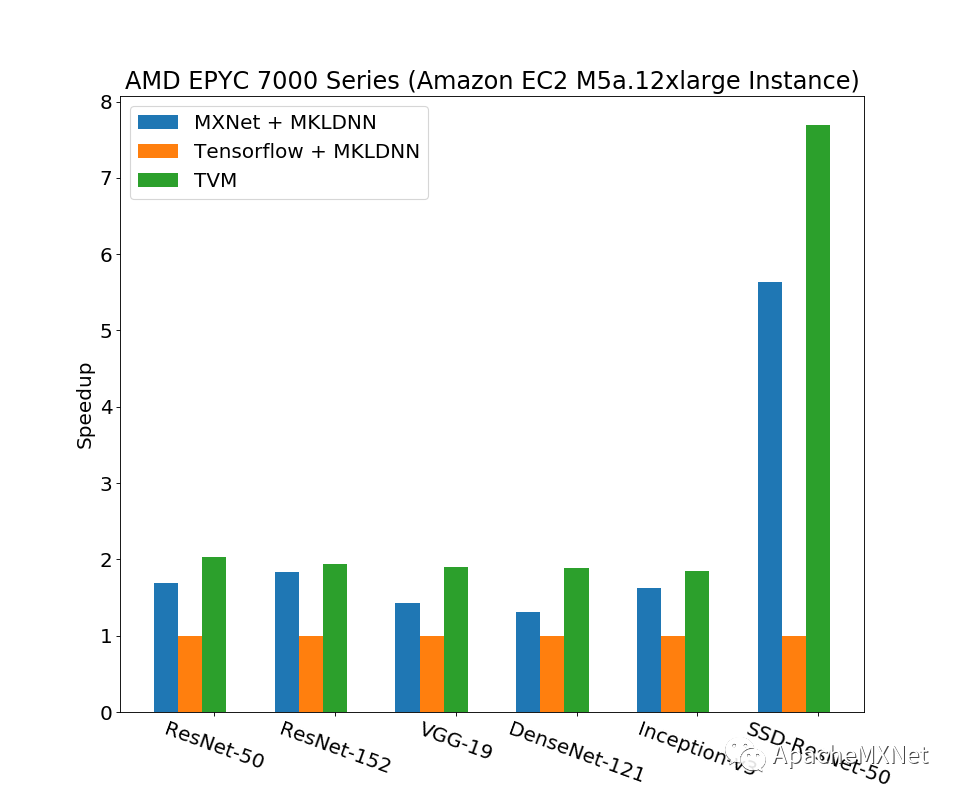
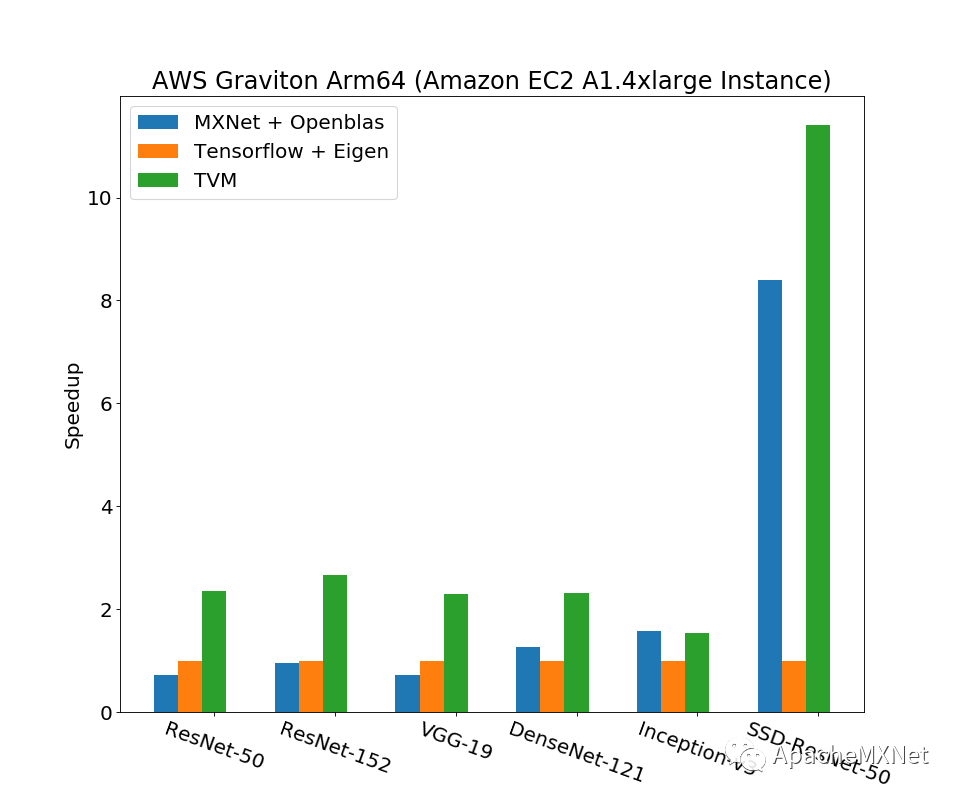
最早TVM的工作比较注重端到端功能的实现,以及在这之上的GPU调优。对于CPU的性能,从基本的卷积算子优化,到更复杂的计算图与算子之间的联合优化,以及运行时的多线程并行都没有仔细做。我们对上面几点经过一顿操作后如愿以偿地得到了上面说的“一个面向不同CPU,依赖度尽量少的高效模型推理方案”。这个工作被我们发表于计算机系统顶会之一USENIX ATC ’19,论文Optimizing CNN Model Inference on CPUs具体阐述了优化方案和结果。下图节选了一些结果,展示了我们方案对经典卷积神经网络模型推理相比深度学习框架的性能提升(数字是以Tensorflow为基准的加速比,越大越好),测试平台涵盖Intel, AMD和ARM的主流CPU,数据类型都是fp32。注意下图里的Tensorflow和MXNet在x86 CPU上都调用了Intel MKL-DNN,在ARM CPU上也调用了OpenBlas和Eigen这样的高性能库,而我们的方案完全没有借助任何第三方加速库,所以运行时的依赖和占用内存量也都做到了最小。这一系列优化已经被广泛应用在亚马逊从云到端的各种服务和产品中,比如亚马逊智能音箱Echo的wakeword model就是用我们的方案优化的。换句话说,在遍布全球的Echo上,当你说Alexa唤醒它们时,本质上都是我们优化过的模型输出了一个正例。我们的整套解决方案完全开源,已经集成在TVM里面,欢迎大家参照TVM网站上的Auto-tuning a convolutional network for x86 CPU教程试用。
如果你好奇从技术上说为什么TVM跑得这么快,请继续往下读,我们尝试从下面几个方面来极简略地一窥究竟。
基本算子优化
以Convolution为例(卷积神经网络绝大多数的运算都消耗在这里),TVM里可以简洁地定义如下
C = tvm.compute(
(batch, out_channel, out_height, out_width),
lambda nn, ff, yy, xx: tvm.sum(
Input[nn, rc, yy * stride_h + ry * dilation_h,
xx * stride_w + rx * dilation_w] *Filter[ff, rc, ry, rx].astype(out_dtype),
axis=[rc, ry, rx]), tag="conv2d")
TVM编译系统会把它转化为一系列的循环乘加。根据Roofline模型,计算性能要么受制于获取数据的带宽(可通过tile增加数据的locality),要么受制于硬件本身的并行计算能力(可通过vectorize等方法充分利用芯片的性能)。TVM提供了另一套称作schedule的接口,让我们可以用一两行Python代码实现复杂的优化操作。
s = tvm.create_schedule(C.op)
什么是tile?
由于内存成本的限制,处理器通常采用多级cache,越靠近处理器的cache速度越快,容量越小。如果数据小到足够放入cache,并且能尽可能长时间的被使用,那么就能节省从DRAM里拉取数据的开销。TVM scheduling提供了对tile, reorder, cache_write等原语来把数据切成小块以便放到cache里。
CC = s.cache_write(C, ‘global’)
ow_chunk, ow_block = s[C].split(ow, factor=16)
s[C].reorder(oc_chunk, oh, ow_chunk, ow_block, oc_block)
什么是vectorize?
现代处理器的SIMD指令用于一次处理多个数据。比如下面这个for循环就可以用一条指令完成。
for (int i = 0; i < 16; ++i) {
c[i] = c[i] + a[i] * b[i];
}
TVM里使用SIMD指令只需要一行代码:
s[C].vectorize(oc_block)
计算优化的方法还有很多,感兴趣的同学可以参考MIT的Performance Engineering of Software Systems公开课。
通过巧妙地组织TVM提供的这些scheduling primitive,在Intel Skylake CPU上我们实现了面向AVX-512这一特定指令集的特殊优化。举例来说,我们用tile将小块数据放入最内层循环,用tile+unroll+cache_read/cache_write生成连续的乘加操作,从而充分使用到AVX-512指令集提供的寄存器zmm,等等。总言之,我们的方案在不借助汇编的情况下,也能够有效利用芯片的底层特性,从而做到最大化性能。具体的细节可以参考上文提到的ATC’19 paper。
让机器自己优化算子(Operator-Level Optimization)
人的经验和精力毕竟是有限的,深度学习算子那么多,即便只是一个convolution,在神经网络中的大小形状也有千千万(不同形状的输入其性能差别非常大,可以对比一下MKL里矩阵乘法在正方形和长方形输入上的表现)。那么,能不能让机器针对特定workload,穷举tile的大小,循环的顺序,vectorize的宽度,等等?进一步说,如果计算资源有限,能不能借助机器学习的方法,缩小这个搜索空间?
这就是AutoTVM尝试去做的事情。我们在实际应用中,确实得到了比人工调优更好的性能,在一些尺寸的输入上,甚至可以超过MKL-DNN,ACL,cuDNN这类官方加速器。并且我们观察到,AutoTVM会针对不同的卷积层产生不一样的算法,这一点是人工静态代码很难做到的。
计算图的优化(Graph/Function-Level Optimization)
深度学习系统现在普遍采用了图结构来描述网络(TVM中的Relay IR更进一步用Programming Language的方式来描述Deep Learning Network,大大增强了框架的表达能力,本文并不展开讨论这一点)。TVM会针对inference做大量图结构的优化,比如把多个算子fuse在一起,减少数据移动和内存分配的开销;在编译期预先完成模型参数的计算;把BatchNorm折叠进Convolution,等等。
交叉优化算子和计算图
除此之外,在ATC’19 paper中,我们还提出算子和计算图的联合优化。我们的方案让operator-level和graph-level配合,使得算子的优化可以反映到计算图上;反过来,计算图的tuning又能指导算子层面做出更好的调优策略。
举例来说,为了优化convolution的性能,我们通常会对输入数据的layout (NCHW四维,分别对应batch size, input channel, height, width)做处理,比如tile input channel这一维去做vectorize(一个常见办法是把NCHW转换成NCHW16c,这个16就是vectorize的大小),在计算结束后再把layout转回去(NCHW16c → NCHW)。这个layout的转换操作是有性能成本的,每个convolution都这么转来转去肯定造成一些浪费。一个自然的想法是,如果网络中的convolution都采用NCHW16c这个layout,是不是只需要在整个网络的输入输出各转换一次就可以了?进一步说,这里的参数16也是可调的,网络中有些conv可能用16比较好,有些用32比较好,还有些形状奇怪的可能要用7,14……这样一来,我们就需要在layout transform产生的性能损失,和使用不同layout产生的性能提升之间做trade-off。具体算法可以参考我们paper中的相关描述。
通过算子和计算图的自动优化,TVM可以生成非常高效的计算代码。我们最终希望,给定一个网络结构和目标硬件,使用TVM可以自动生成最优的计算逻辑。就像如今程序员只需要专注于业务逻辑,而把性能调优交给高级语言编译器来完成;深度学习科学家也只需要专注于模型结构本身,把部署到生产环境(可以是CPU/GPU服务器,Edge device,浏览器,FPGA等等)这个任务交给深度学习编译器。
CPU上的运行时多线程
上面说的各种优化思想其实可以用到各种不同的设备上,专门对于CPU来说,我们还优化了TVM运行时的多线程并行操作。你可能会问为什么不直接用OpenMP, 简单的答案是我们实测的OpenMP扩展性和稳定性并不理想(具体参见paper)。另外OpenMP这套接口的在不同平台上的实现各不相同,这也带来了性能上的不确定性。再者,TVM里遇到的多线程并行都是embarassingly parallel的,我们并不需要像OpenMP那样处理各种复杂的并行同步。基于以上种种,我们决定在TVM用pthread和C++11以后提供的std::atomic实现一套简单实用的CPU运行时多线程。具体一点说,我们用细粒度的原子操作来实现单生产者单消费者的lockfree queue以便调度作业的主线程和各个工作线程高效通信;我们还把不同的工作线程绑在不用的CPU物理核上,最大程度地消除资源竞争;最后我们在全局变量上加了相应的cache line padding以消除线程间的false sharing。

