过载保护+异构服务器的负载均衡,怎么设计?
负载均衡是指,将请求/数据分摊到多个操作单元上执行,关键在于均衡。
然而,后端的服务器有可能硬件条件不同:
如果对标低配的服务器“均匀”分摊负载,高配的服务器利用率会不足
如果对标高配的服务器“均匀”分摊负载,低配的服务器会扛不住
能否根据异构服务器的处理能力来动态、自适应进行负载均衡,以及过载保护呢?
负载均衡通常是怎么做的?
service层的负载均衡,一般是通过service连接池来实现的,调用方连接池会建立与下游服务多个连接,每次请求“随机”获取连接,来保证访问的均衡性。

负载均衡、故障转移、超时处理等细节也都是通过调用方连接池来实现的。
调用方连接池能否,根据service的处理能力,动态+自适应的进行负载调度呢?
方案一:可以通过“静态权重”标识service的处理能力。
最容易想到的方法,可以为每个下游service设置一个“权重”,代表service的处理能力,来调整访问到每个service的概率,如上图所示:

(1) 假设ip1,ip2,ip3的处理能力相同,可以设置weight1=1,weight2=1,weight3=1,这样三个service连接被获取到的概率分别就是1/3,1/3,1/3,能够保证均衡访问;
(2) 假设ip1的处理能力是ip2,ip3的处理能力的2倍,可以设置weight1=2,weight2=1,weight3=1,这样三个service连接被获取到的概率分别就是2/4,1/4,1/4,能够保证处理能力强的service分到等比的流量,不至于资源浪费;
Nginx就具备类似的能力。
方案优点:简单粗暴,能够快速的实现异构服务器的负载均衡。
方案缺点:权重是固定的,无法自适应动态调整,而很多时候,服务器的处理能力是很难用一个固定的数值量化。
方案二:通过“动态权重”标识service的处理能力。
如何来标识一个service的处理能力呢?
服务能不能处理得过来,该由调用方说了算:
调用服务,快速处理,处理能力跟得上
调用服务,处理超时,处理能力很有可能跟不上了
如何来设计动态权重?
可以这么玩:
(1) 用一个动态权重,来标识每个service的处理能力,默认初始处理能力相同,即分配给每个service的概率相等;
(2) 每当service成功处理一个请求,认为service处理能力足够,权重动态+1;
(3) 每当service超时处理一个请求,认为service处理能力可能要跟不上了,权重动态-10;
画外音:
权重下降,会比权重上升更快。
为了方便权重的处理,可以把权重的范围限定为[0, 100],把权重的初始值设为60分。
举例说明:
假设service-ip1,service-ip2,service-ip3的动态权重初始值:
weight1=60
weight2=60
weight3=60
刚开始时,请求分配给这3台service的概率分别是60/180,60/180,60/180,即负载是均衡的。
随着时间的推移:
处理能力强的service成功处理的请求越来越多
处理能力弱的service偶尔有超时
随着动态权重的增减,权重会发生变化:
weight1=100
weight2=60
weight3=40
那么此时,请求分配给这3台service的概率分别是100/200,60/200,40/200,即处理能力强的service会被分配到更多的流量。
那什么是过载保护?
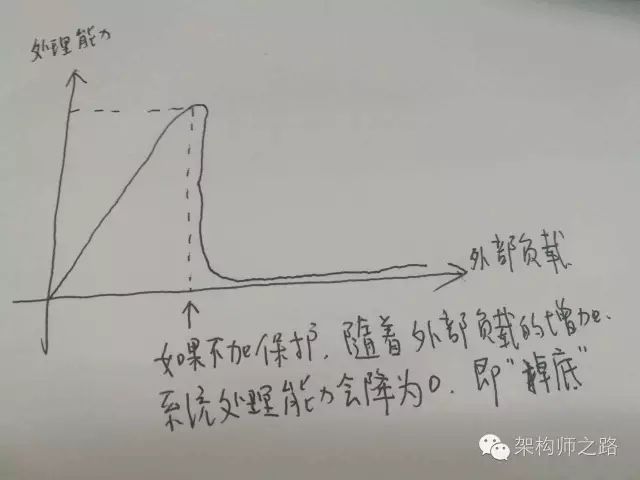
如上图所示,如果没有过载保护:
随着外部负载的不断升高,系统实际处理负载会增加
外部负载升高到一个临界值,系统会被压垮,实际处理能力会降为0
画外音:这就是所谓的“掉底”。
过载保护,是指当外部负载超过系统处理能力时,系统会进行自我保护,依然能对外提供有损的稳定服务。

如上图所示,如果进行了过载保护:
随着外部负载的不断升高,系统实际处理负载会增加
外部负载即使超过一个临界值,系统不会被压垮,而能保持一定的处理能力
画外音:外部负载无限大,系统也不会“掉底”。
那如何进行过载保护?
方案一:可以通过“静态权重”标识service的处理能力。
这是最简易的方式,服务端设定一个负载阈值,超过这个阈值的请求压过来,全部抛弃。
画外音:这个方式不是特别优雅。
方案二:借助“动态权重”来实施过载保护。
如同异构服务器负载均衡,仍然通过:
成功处理加分(+1)
处理超时扣分(-10)
这种动态权重,来标识后端的处理能力。
画外音:仍然是在连接池层面实现的。
当一个服务端屡次处理超时,权重不断降低时,连接池只要实施一些策略,就能够对“疑似过载”的服务器进行降压,而不用服务器“抛弃请求”这么粗暴的实施过载保护。
应该实施什么样的策略,来对“疑似过载”的服务器进行降压保护呢?
可以这么玩:
(1) 如果某一个服务器,连续3个请求都超时,即连续-10分三次,就可以认为,服务器处理不过来了,得给这个服务器喘一小口气,于是设定策略:接下来的若干时间内,例如1秒,负载不再分配给这个服务器;
画外音:休息1秒后,再分给它。
(2) 如果某一个service的动态权重,降为了0(休息了3次还超时),就可以认为,服务器完全处理不过来了,得给这个服务器喘一大口气,于是设定策略:接下来的若干时间内,例如1分钟,请求不再分配给这个服务器;
画外音:根据经验,此时服务器一般在fullGC,差不多1分钟能回过神来。
这样的话,不但能借助“动态权重”来实施动态自适应的异构服务器负载均衡,还能在客户端层面更优雅的实施过载保护,在某个下游服务器快要响应不过来的时候,给其喘息的机会。
过载保护要注意什么问题?
要防止过载保护引起服务器的雪崩,如果“整体负载”已经超过了“服务器集群”的处理能力,怎么转移请求也是处理不过来的。这时,还是得通过抛弃请求来实施自我保护。
总结
负载均衡、故障转移、超时处理通常是连接池层面来实施的
异构服务器负载均衡,最简单的方式是静态权重法,缺点是无法自适应动态调整
动态权重法,可以动态的根据服务器的处理能力来分配负载,需要有连接池层面的微小改动
过载保护,是在负载过高时,服务器为了保护自己,保证一定处理能力的一种自救方式
动态权重法,还可以用做服务器的过载保护

架构师之路-分享可落地的技术文章
相关推荐:
《GFS架构启示》
据说,配图值得转。