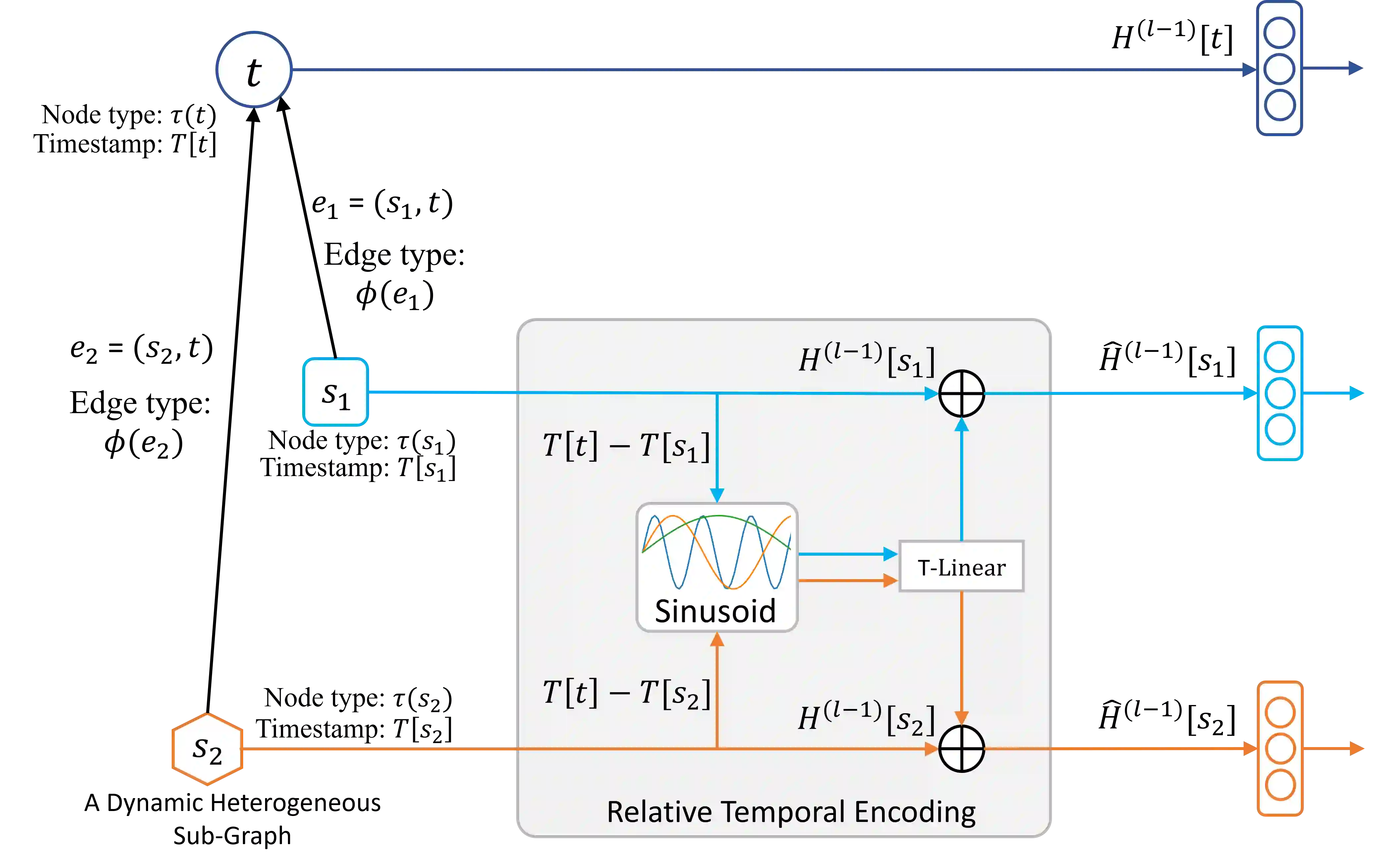
Recent years have witnessed the emerging success of graph neural networks (GNNs) for modeling structured data. However, most GNNs are designed for homogeneous graphs, in which all nodes and edges belong to the same types, making them infeasible to represent heterogeneous structures. In this paper, we present the Heterogeneous Graph Transformer (HGT) architecture for modeling Web-scale heterogeneous graphs. To model heterogeneity, we design node- and edge-type dependent parameters to characterize the heterogeneous attention over each edge, empowering HGT to maintain dedicated representations for different types of nodes and edges. To handle dynamic heterogeneous graphs, we introduce the relative temporal encoding technique into HGT, which is able to capture the dynamic structural dependency with arbitrary durations. To handle Web-scale graph data, we design the heterogeneous mini-batch graph sampling algorithm---HGSampling---for efficient and scalable training. Extensive experiments on the Open Academic Graph of 179 million nodes and 2 billion edges show that the proposed HGT model consistently outperforms all the state-of-the-art GNN baselines by 9%--21% on various downstream tasks.
翻译:近些年来,图形神经网络(GNNS)为结构化数据建模而取得了新的成功。然而,大多数GNNS是为同型图形设计的,其中所有节点和边缘都属于同一类型,因此无法代表各种结构。在本文中,我们介绍了用于建模网络尺度多元图的异质图形变异器(HGT)结构。为了模型异质性,我们设计了偏差和边缘型依赖参数,以辨别每个边缘的不同关注点,授权HGT为不同类型节点和边缘保持专门代表机构。为了处理动态异形图,我们将相对的时间编码技术引入HGTT, 该技术能够以任意的长度捕捉动态结构依赖性。为了处理网络规模图数据,我们设计了用于建模网络规模的混合微型批量图像算法-HGSampling-用于高效和可扩展的培训。关于1,9百万节点和20亿边缘的开放学术图的大规模实验显示,拟议的HGTT模型在21 %的下游基线上始终超越所有状态任务。