【干货】5个最新图像合成GAN架构解读:核心理念、关键成就、商业化路径

来源:新智元
【导读】本文总结了5个最近推出的用于图像合成的GAN架构,对论文从核心理念、关键成就、社区价值、未来商业化及可能的落地应用方向对论文进行解读。
本文总结了5个最近推出的用于图像合成的GAN架构,对论文从核心理念、关键成就、社区价值、未来商业化及可能的落地应用方向对论文进行解读,对创业者、开发者、工程师、学者均有非常高的价值。
多域图像到图像翻译的统一生成网络。作者YUNJEY CHOI,MINJE CHOI,MUNYOUNG KIM,JUNG-WOO HA,SUNGHUN KIM,JAEGUL CHOO。论文地址:
https://arxiv.org/abs/1711.09020
论文摘要
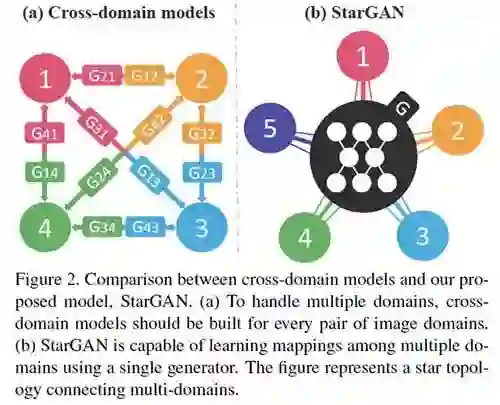
最近的研究表明,两个领域的图像到图像转换取得了显著的成功。然而,现有方法在处理两个以上的域时,可扩展性和鲁棒性的比较有限,因为需要为每对图像域独立地构建不同的模型。
StarGAN的出现就是为了解决这一问题。研究人员提出了一种新颖且可扩展的方法,可以实现仅靠单个模型就能对多个域执行图像到图像的转换。
StarGAN这种统一模型架构,允许在单个网络内同时训练具有不同域的多个数据集。与现有模型相比,StarGAN有着更高的图像转化质量,以及将输入图像灵活地转换为任何所需目标域的新颖功能。
我们凭经验证明了我们的方法在面部属性转移,和面部表情综合任务方面的有效性。
核心理念
StarGAN是一种可扩展的图像到图像转换模型,可以使用单个网络从多个域中学习:
生成器不是学习固定的转换(例如,年轻到年老),而是接收图像和域信息作为输入,以在相应的域中生成图像
提供域信息作为标签(例如,二进制或one-hot矢量)
StarGAN还可以从包含不同类型标签的多个数据集中学习:
例如,作者展示了如何使用具有头发颜色,性别和年龄等属性的CelebA数据集,以及具有与面部表情相对应的标签的RaFD数据集来训练模型
将mask向量添加到域标签后,生成器会学着忽略未知标签,并专注于明确给定的标签
关键成就
定性和定量评估表明,StarGAN在面部属性转移和面部表情综合方面优于基准模型:
在更复杂的多属性传输任务中,优势尤为明显,这反映了StarGAN处理具有多个属性更改的图像转换的能力
由于多任务学习的隐含数据增强效果,StarGAN还可以生成更具视觉吸引力的图像
社区评价
该研究论文在计算机视觉的重要会议CVPR 2018 oral上被接受。
未来的研究领域
探索进一步改善生成图像的视觉质量的方法。
可能的商业应用
图像到图像转换可以降低用于广告和电子商务用途的媒体创意的成本。
源码
https://github.com/yunjey/stargan
用细致的文字生成图像,作者TAO XU, PENGCHUAN ZHANG, QIUYUAN HUANG, HAN ZHANG, ZHE GAN, XIAOLEI HUANG, XIAODONG HE。论文地址:
https://arxiv.org/abs/1711.10485
论文摘要
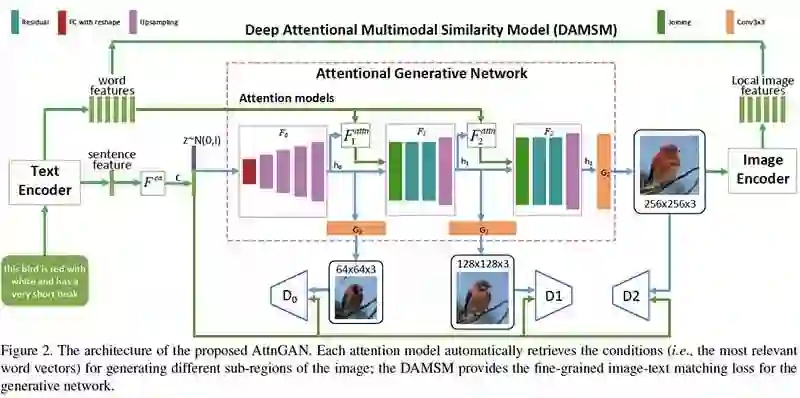
在论文中,我们提出了一种Attentional生成对抗网络(AttnGAN)。它允许注意力驱动的多阶段细化,以实现细粒度粒度的文本到图像的生成。
通过新颖的注意力生成网络,AttnGAN可以通过关注自然语言描述中的相关单词,来合成图像的不同子区域的细粒度细节。此外,提出了一种深度attentional多模态相似度模型,来计算用于训练生成器的细粒度图像文本匹配损失。
AttnGAN明显优于当前最先进的技术水平,在CUB数据集上提升了14.14%的最佳报告得分,在更具挑战性的COCO数据集上得到170.25%的提升。同时还通过可视化AttnGAN的注意力层来执行详细分析。它首次表明分层注意力GAN能够自动选择单词级别的条件,以生成图像的不同部分。
核心理念
可以通过多阶(例如,单词级和句子级)调节来实现细粒度的高质量图像生成。因此,研究人员提出了一种体系结构,其中生成网络通过这些子区域最相关的单词来绘制图像。
Attentional Generative Adversarial Network有两个新颖的组件:Attentional generative network和深度Attentional多模态相似度模型(DAMSM)。
Attentional generative network包括以下2个方面
利用全局句子向量在第一阶段生成低分辨率图像
将区域图像矢量与对应的词语上下文矢量组合以在周围子区域中生成新的图像特征
而深度Attentional多模态相似度模型(DAMSM),用于计算生成的图像和文本描述之间的相似性,为训练生成器提供额外的细粒度图文匹配损失。
关键成就
CUB数据集上提升了14.14%的最佳报告得分
COCO数据集提升了170.25%
证明分层条件GAN能够自动关注相关单词以形成图像生成的正确条件
社区评价
该论文在计算机视觉的重要会议2018年CVPR上发表。
未来的研究领域
探索使模型更好地捕获全局相干结构的方法;增加生成图像的照片真实感。
可能的商业应用
根据文本描述自动生成图像,可以提高计算机辅助设计和艺术品的生产效率。
源码
GitHub上提供了AttnGAN的PyTorch实现。
作者TING-CHUN WANG, MING-YU LIU, JUN-YAN ZHU, ANDREW TAO, JAN KAUTZ, BRYAN CATANZARO。论文地址:
https://arxiv.org/abs/1711.11585
论文摘要
Conditional GAN已有很多应用案例,但通常仅限于低分辨率图像,且远未达到以假乱真的地步。NVIDIA引入了一个新的方法,可以从语义标签贴图中合成高分辨率(2048×1024)、照片级的逼真图像。
他们的方法基于新的强大对抗性学习目标,以及新的多尺度生成器和鉴别器架构。这种新方法在语义分割和照片真实性的准确性方面,总体上优于以前的方法。此外,研究人员还扩展其框架以支持交互式语义操作,合并了对象实例分割信息,似的它可以实现对象操作,例如更改对象类别、添加/删除对象或更改对象的颜色和纹理。
人类裁判经过肉眼比对后表示,此方法明显优于现有方法。

核心理念
称为pix2pixHD(基于pix2pix方法)的新框架合成高分辨率图像,有几处改进:
coarse-to-fine(由粗糙到细粒度)生成器:训练全局生成器以1024×512的分辨率合成图像,然后训练局部增强器以提高分辨率
多尺度鉴别器:使用3个不同图像尺度的鉴别器
改进的对抗性损失:基于鉴别器结合特征匹配损失
该框架还允许交互式对象编辑,这要归功于添加额外的低维特征通道作为生成器网络的输入。
关键成就
引入的pix2pixHD方法在以下方面的表现优于最先进的方法:
语义分割的逐像素精度,得分为83.78(来自pix2pix基准的5.44,仅比原始图像的精度低0.51个点)
人工评估员可以在任意数据集和任意时间设置(无限时间和有限时间)上进行的成对比较
社区评价
在计算机视觉的重要会议CVPR 2018上 Oral上,深度学习研究员Denny Britz对此评价:“这些GAN结果令人印象深刻。 如果你现在正在用Photoshop修图来谋生,那么可能是时候另谋出路了。“
可能的商业应用
该方法为更高级别的图像编辑提供了新工具,例如添加/删除对象或更改现有对象的外观。可以用在修图工具中,或者创建新的修图工具。
源码
https://github.com/NVIDIA/pix2pixHD
作者ANDREW BROCK,JEFF DONAHUE和KAREN SIMONYAN,论文地址:
https://arxiv.org/abs/1809.11096
论文摘要
DeepMind团队发现,尽管最近在生成图像建模方面取得了进展,但是从像ImageNet这样的复杂数据集中成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。
经过对GAN进行了最大规模的训练尝试,并研究了这种规模特有的不稳定性后,发现将正交正则化应用于生成器可以使得它适合于简单的“截断技巧”,允许通过截断潜在空间来精确控制样本保真度和变化之间的权衡。
这样的改动导致模型在类条件图像合成中达到了新的技术高度,当在ImageNet上以128×128分辨率进行训练时,模型(BigGAN)的Inception Score(IS)达到了166.3;Frechet Inception Distance(FID)为9.6。而之前的最佳IS为52.52,FID为18.65。
该论文表明,如果GAN以非常大的规模进行训练,例如用两倍到四倍的参数和八倍于之前的批量大小,就可以生成看起来非常逼真的图像。这些大规模的GAN(即BigGAN)是类条件图像合成中最先进的新技术。

核心理念
随着批量大小和参数数量的增加,GAN的性能在提升
将正交正则化应用于生成器使得模型响应于特定技术(“截断技巧”),通过这种方式提供对样本保真度和变化之间的权衡的控制
关键成就
证明GAN可以通过增加数据量来获得更好的收益
构建模型,允许对样本种类和保真度之间的权衡进行明确的、细粒度的控制
发现大规模GAN的不稳定性并根据经验进行表征
在ImageNet上以128×128分辨率训练的BigGAN实现
Inception Score(IS)为166.3,之前的最佳IS为52.52
FrechetInception Distance(FID)为9.6,之前的最佳FID为18.65
社区评价
该文件正在被评审是否录取为下一届ICLR 2019。
在BigGAN发生器登上TF Hub后,来自世界各地的AI研究人员用BigGAN来生成狗,手表,比基尼图像,蒙娜丽莎,海滨等等,玩的不亦乐乎
未来的研究领域
迁移到更大的数据集以缓解GAN稳定性问题
探索减少GAN产生的奇怪样本数量的可能性
可能的商业应用
替代广告和电商成本较高的手动媒体创建。
源码
https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/biggan_generation_with_tf_hub.ipynb
https://github.com/AaronLeong/BigGAN-pytorch
作者TERO KARRAS,SAMULI LAINE,TIMO AILA,论文地址:
https://arxiv.org/abs/1812.04948
论文摘要
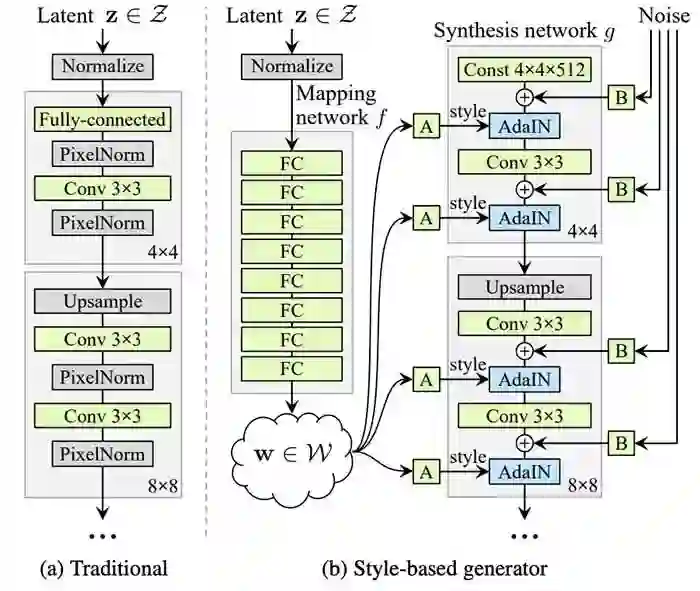
NVIDIA团队推出了一种新的生成器架构StyleGAN,借鉴了风格转移文献。在这项研究中,他们解决了对传统GAN架构生成的图像进行非常有限的控制的问题。
StyleGAN中的生成器自动学习分离图像的不同方面,而无需任何人为监督,从而可以多种不同方式组合这些方面。例如,我们可以从一个人那里获取性别,年龄,头发长度,眼镜和姿势,而从另一个人那里获取所有其他方面。由此产生的图像在质量和真实性方面优于先前的技术水平。
核心理念
StyleGAN基于渐进式GAN设置,其中假定网络的每个层控制图像的不同视觉特征,层越低,其影响的特征越粗糙:
对应于粗糙空间分辨率(4×4 - 8×8)的层使得能够控制姿势、一般发型、面部形状等
中间层(16×16 - 32×32)影响较小规模的面部特征,如发型、睁眼/闭眼等
细粒度分辨率(64×64 - 1024×1024)的层主要带来颜色方案和微结构
受风格转移文献的推动,NVIDIA团队引入了一种生成器架构,可以通过新颖的方式控制图像合成过程
省略输入层并从学习的常量开始
在每个卷积层调整图像“样式”,允许直接控制不同尺度的图像特征的强度
在每个卷积之后添加高斯噪声以生成随机细节
关键成就
在CelebA-HQ数据集上得到5.06的Frèchet inception distance(FID)得分,在Flickr-Faces-HQ数据集上获得4,40得分
呈现人脸Flickr-Faces-HQ的新数据集,其具有比现有高分辨率数据集更高的图像质量和更宽的变化
社区评价
Uber的软件工程师Philip Wang创建了一个网站
thispersondoesnotexist.com可以在其中找到使用StyleGAN生成的面孔。这个网站形成了病毒式传播
未来的研究领域
探索在训练过程中直接塑造中间潜在空间的方法
可能的商业应用
由于StyleGAN方法的灵活性和高质量的图像,它可以替代广告和电子商务中昂贵的手工媒体创作。
源码
https://github.com/NVlabs/stylegan
参考链接:
https://www.topbots.com/ai-research-generative-adversarial-network-images/
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得


