信息检索顶会SIGIR2020最佳论文公布,公平性排序学习获得最佳,清华摘得多个奖项
编辑:魔王、杜伟、小舟
第 43 届国际计算机协会信息检索大会(ACM SIGIR)于本月 25 日举行。昨日,大会公布了最佳论文等奖项。来自清华大学的研究人员获得最佳论文荣誉提名奖、最佳短论文奖奖项。


论文作者:Marco Morik(柏林工业大学)、Ashudeep Singh(康奈尔大学)、Jessica Hong(康奈尔大学)、Thorsten Joachims(康奈尔大学)
论文链接:https://dl.acm.org/doi/pdf/10.1145/3397271.3401100

论文作者:Fan Zhang、Jiaxin Mao、Yiqun Liu、Xiaohui Xie、Weizhi Ma、Min Zhang、Shaoping Ma(均来自清华大学)
论文链接:https://dl.acm.org/doi/pdf/10.1145/3397271.3401162
底层用户模型能否准确预测用户行为;
评估指标能否很好地度量用户满意度。

论文作者:Shi Yu(清华大学)、Jiahua Liu(清华大学)、Jingqin Yang(清华大学)、Chenyan Xiong(MSR AI)、Paul Bennett(MSR AI)、Jianfeng Gao(MSR AI)、Zhiyuan Liu(清华大学)
论文链接:https://dl.acm.org/doi/pdf/10.1145/3397271.3401323

论文作者:Jianxin Chang(清华大学)、Chen Gao(清华大学)、Xiangnan He(中国科学技术大学)、Depeng Jin(清华大学)、Yong Li(清华大学)
论文链接:https://dl.acm.org/doi/pdf/10.1145/3397271.3401198

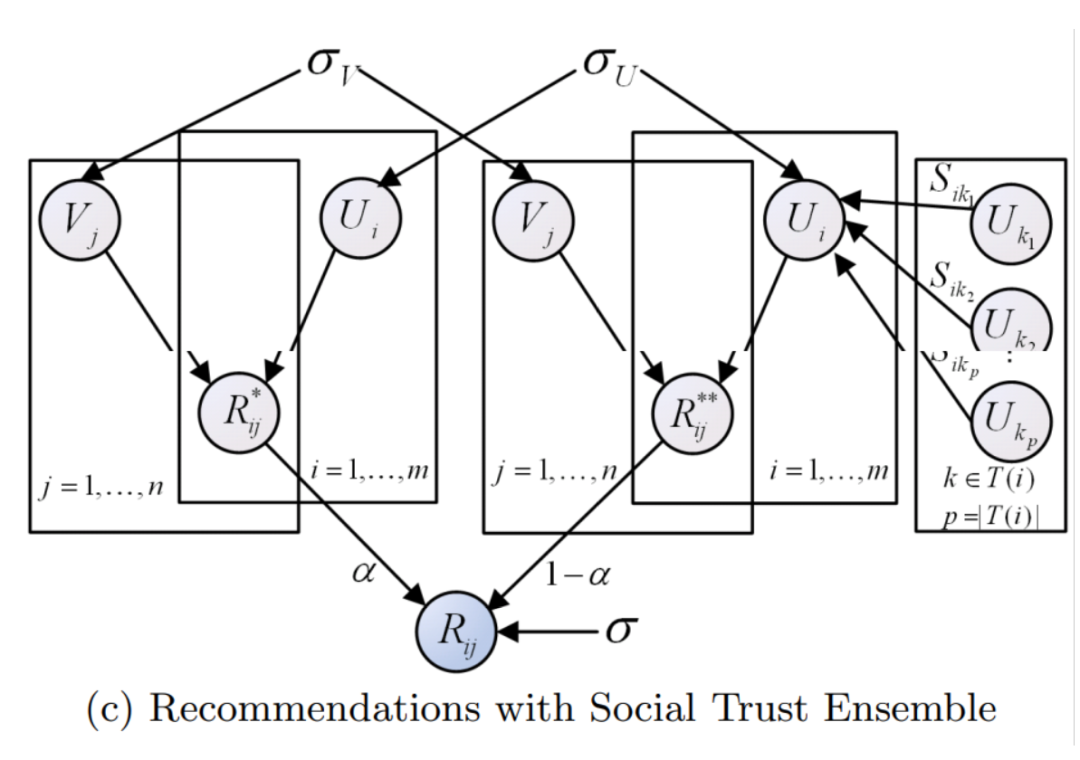
论文作者:Hao Ma、Irwin King、Michael R. Lyu(均来自香港中文大学)
论文链接:https://www.cc.gatech.edu/~zha/CSE8801/CF/p203-ma.pdf

论文作者:Georges Dupret、Benjamin Piwowarski(均来自雅虎研究院拉美分部)
论文链接:https://dl.acm.org/doi/abs/10.1145/1390334.1390392

论文作者:Guihong Cao(蒙特利尔大学)、Jian-Yun Nie(蒙特利尔大学)、Jianfeng Gao(美国雷德蒙德微软研究院)、Stephen Robertson(英国剑桥微软研究院)
论文链接:http://www-labs.iro.umontreal.ca/~nie/IFT6255/Cao-sigir-08.pdf





