【导读】国际万维网大会(The Web Conference,简称WWW会议)是由国际万维网会议委员会发起主办的国际顶级学术会议,创办于1994年,每年举办一届,是CCF-A类会议。WWW 2020将于2020年4月20日至4月24日在中国台湾台北举行。本届会议共收到了1129篇长文投稿,录用217篇长文,录用率为19.2%。近期,推荐相关也比较热门,专知小编提前整理了WWW 2020 推荐系统比较有意思的的论文,供参考——序列推荐、可解释Serendipity 推荐、推荐效率、 bandit推荐、Off-policy学习。 WWW2020RS_Part1
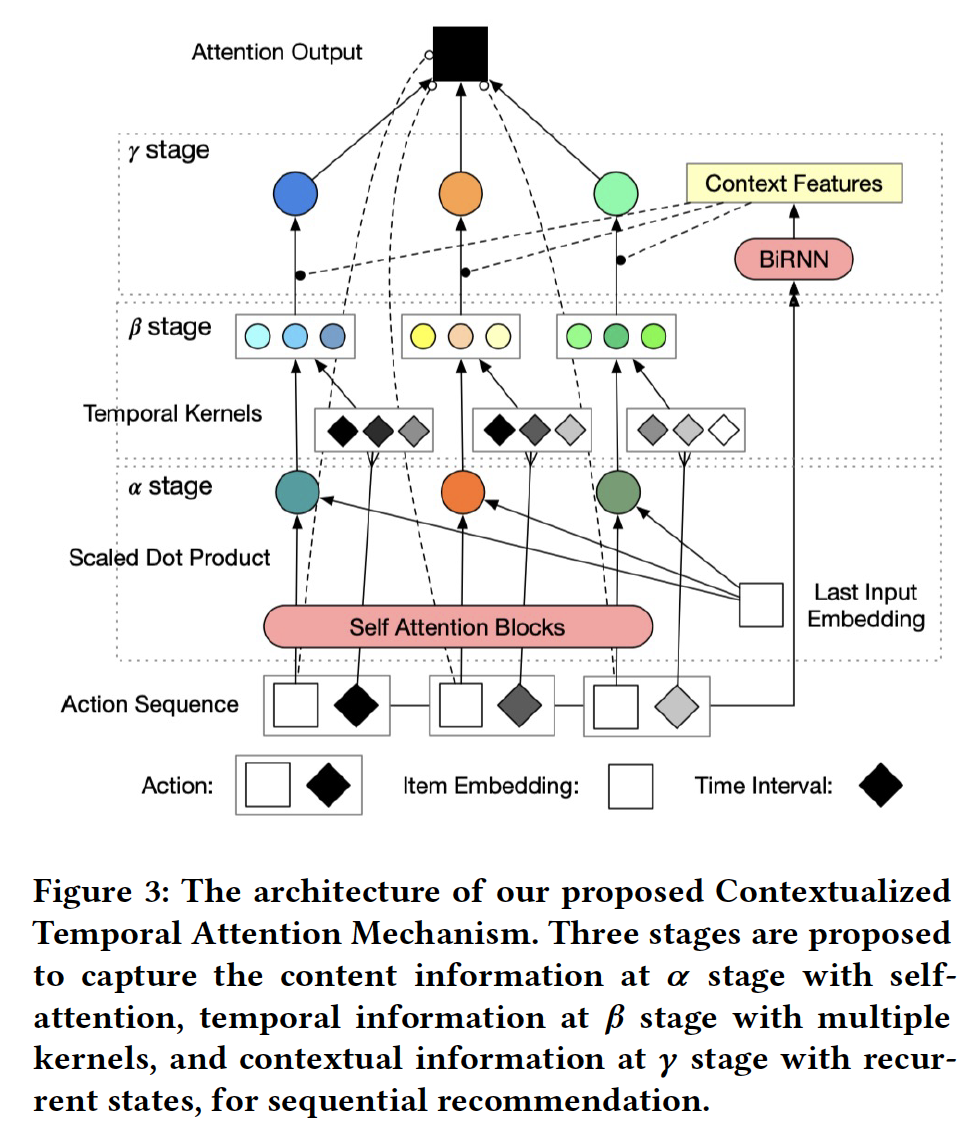
- A Contextualized Temporal Attention Mechanism for Sequential Recommendation
作者:Jibang Wu, Renqin Cai, Hongning Wang
摘要:根据用户的历史连续行为预测用户的偏好对于现代推荐系统来说是具有挑战性的,也是至关重要的。现有的序列推荐算法在建模历史事件对当前预测的影响时,大多侧重于序列行为之间的过渡结构,而很大程度上忽略了时间和上下文信息。在这篇文章中,我们认为过去的事件对用户当前行为的影响应该随着时间的推移和不同的背景而变化。因此,我们提出了一种情境时间注意力机制(Contextualized Temporal Attention),该机制可以学习权衡历史行为在行为以及行为发生的时间和方式上的影响。更具体地说,为了动态地校准来自自注意力机制的相对输入的依赖关系,我们提出了多个参数化的核函数以学习各种时间动态,然后使用上下文信息来确定每个输入要跟随哪一个kernel( reweighing kernels )。在对两个大型公开推荐数据集进行的实证评估中,我们的模型始终优于一系列最先进的序列推荐方法。
网址:
https://arxiv.org/pdf/2002.00741.pdf
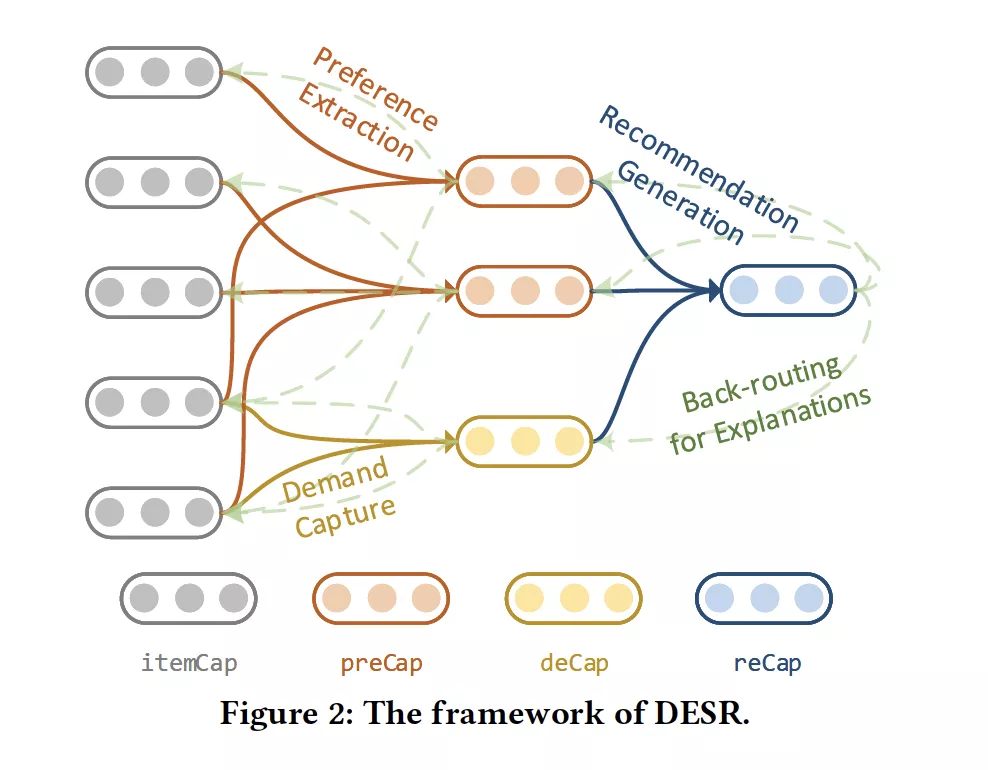
- Directional and Explainable Serendipity Recommendation
作者:Xueqi Li, Wenjun Jiang, Weiguang Chen, Jie Wu, Guojun Wang, Kenli Li
摘要:近几年来,Serendipity推荐越来越受到人们的关注,它致力于提供既能迎合用户需求,又能开阔他们眼界的建议。然而,现有的方法通常使用标量而不是向量来度量用户与项目的相关性,忽略了用户的偏好方向,这增加了不相关推荐的风险。此外,合理的解释增加了用户的信任度和接受度,但目前没有为Serendipity推荐提供解释的工作。为了解决这些局限性,我们提出了一种有向的、可解释的Serendipity推荐方法,称为DESR。具体而言,首先采用基于高斯混合模型(GMM)的无监督方法提取用户的长期偏好,然后利用胶囊(capsule )网络捕捉用户的短期需求。然后,我们提出了将长期偏好与短期需求相结合的意外(serendipity)向量,并利用它生成有向的Serendipity推荐。最后,利用反向路径选择方案进行了解释。在真实数据集上的大量实验表明,与现有的基于意外(serendipity)发现的方法相比,DESR能够有效地提高意外性和可解释性,促进多样性。
网址 https://cis.temple.edu/~jiewu/research/publications/Publication_files/jiang_www_2020.pdf
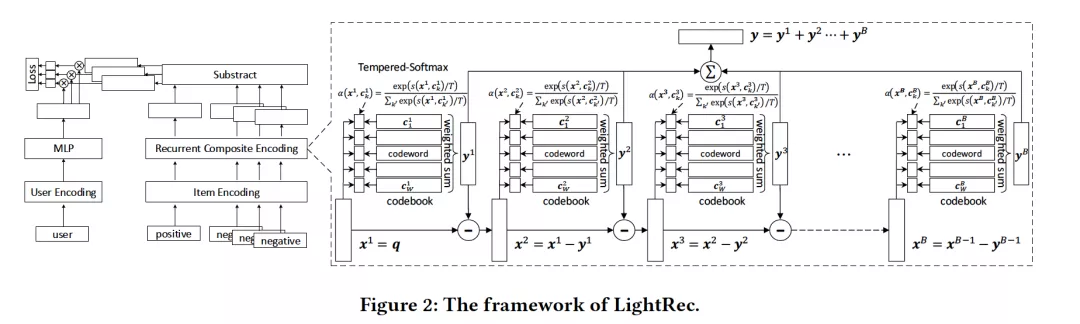
- LightRec: a Memory and Search-Efficient Recommender System
作者:Defu Lian, Haoyu Wang, Zheng Liu, Jianxun Lian, Enhong Chen, Xing Xie
摘要:近年来,深度推荐系统已经取得了显着的进步。尽管具有出色的排名精度,但实际上运行效率和内存消耗在现实中却是严重的瓶颈。为了克服这两个瓶颈,我们提出了LightRec,这是一个轻量级的推荐系统,具有快速的在线推断功能和经济的内存消耗。LightRec的主干是总共B个codebooks,每个codebook均由W个潜在向量组成,称为codewords。在这种结构的顶部,LightRec将有一个商品表示为B codewords的加法组合,这些B codewords是从每个codebook中选择的最佳的。为了有效地从数据中学习codebooks,我们设计了一个端到端的学习工作流程,其中所提出的技术克服了固有差异性和多样性方面的挑战。另外,为了进一步提高表示质量,采用了几种distillation策略,可以更好地保留用户-商品的相关性得分和相对排名顺序。我们对LightRec在四个真实数据集上进行了广泛评估,得出了两个经验发现:1)与最先进的轻量级baseline相比,LightRec在召回性能方面取得了超过11%的相对改进;2)与传统推荐算法相比,在top-k推荐算法中,LightRec的精度下降幅度可以忽略不计,但速度提高了27倍以上。
网址: http://staff.ustc.edu.cn/~liandefu/paper/lightrec.pdf
- Hierarchical Adaptive Contextual Bandits for Resource Constraint based Recommendation
作者:Mengyue Yang, Qingyang Li, Zhiwei Qin, Jieping Ye
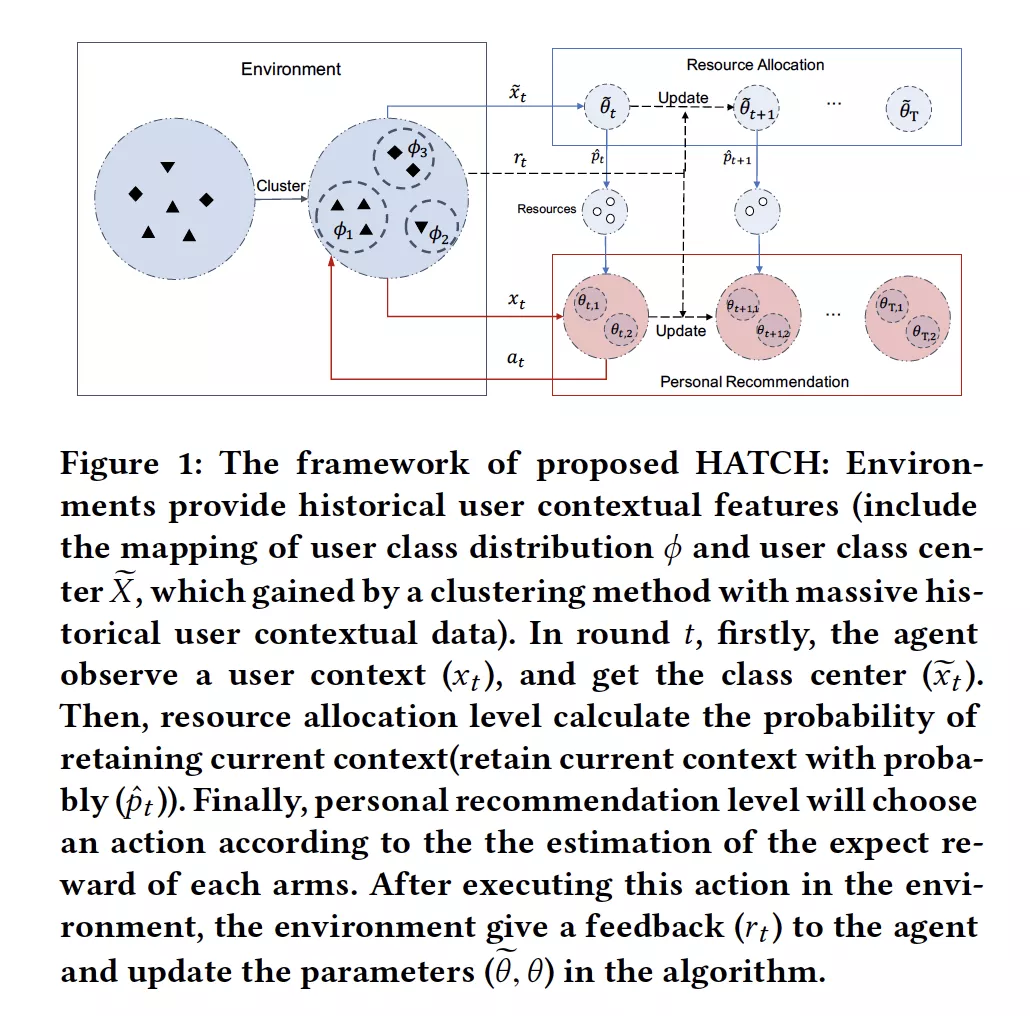
摘要:上下文多臂 bandit(MAB)在各种问题上实现了优异性能。然而,当涉及到推荐系统和在线广告等现实场景时,必须考虑探索的资源消耗。在实践中,通常存在与在环境中执行建议(ARM)相关联的非零成本,因此,应该在固定的探索成本约束下学习策略。由于直接学习全局最优策略是一个NP难题,并且极大地使bandit算法的探索和开发之间的权衡复杂化,因此直接学习全局最优策略是一个很大的挑战。现有的方法着重于通过采用贪婪策略来解决问题,该策略估计预期的收益和成本,并基于每个臂的预期收益/成本比使用贪婪的选择,利用历史观察直到勘探资源耗尽为止。然而,现有的方法当没有更多的资源时,学习过程就会终止,因此很难扩展到无限的时间范围。本文提出了一种分层自适应上下文bandit方法(HATCH)来进行有预算约束的上下文bandit的策略学习。HATCH采用一种自适应的方法,根据剩余资源/时间和对不同用户上下文之间报酬分配的估计来分配勘探资源。此外,我们利用充分的上下文特征信息来找到最好的个性化推荐。最后,为了证明提出的理论,我们进行了regret bound分析,并证明HATCH的regret bound低至O(√T)。实验结果证明了该方法在合成数据集和实际应用中的有效性和效率。
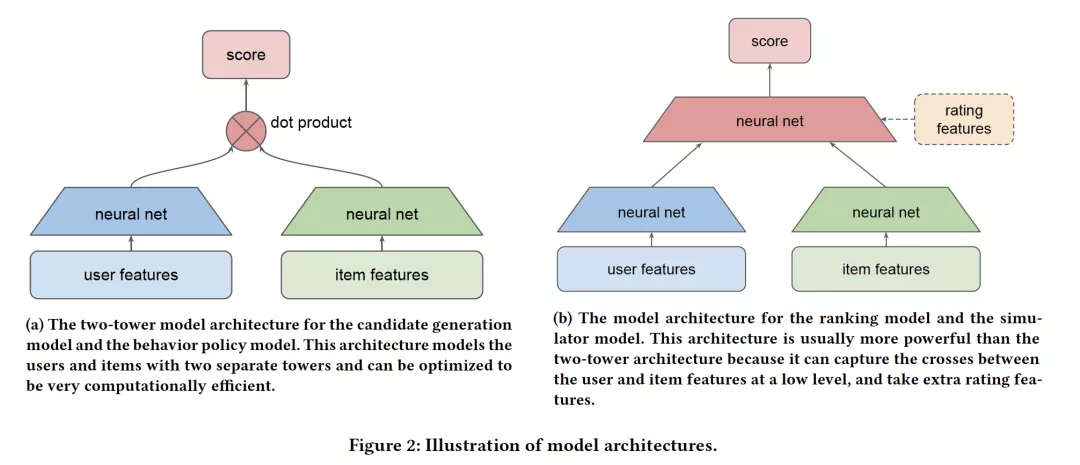
- Off-policy Learning in Two-stage Recommender Systems
作者:Jiaqi Ma, Zhe Zhao, Xinyang Yi, Ji Yang, Minmin Chen, Jiaxi Tang, Lichan Hong, Ed H. Chi
摘要:许多现实世界中的推荐系统需要高度可伸缩性:将数百万个项目与数十亿用户进行匹配,并只具有毫秒级的延迟。可伸缩性的要求导致了广泛使用的两阶段推荐系统,由第一阶段高效的候选生成模型和第二阶段更强大的排序模型组成。通常使用记录的用户反馈(例如,用户点击或停留时间)来构建用于推荐系统的候选生成和排名模型。虽然很容易收集大量这样的数据,但因为反馈只能在以前系统推荐的项目上观察到,因此这些数据在本质上是有偏见的。近年来,推荐系统研究领域对此类偏差的off-policy 修正引起了越来越多的关注。然而,现有的大多数工作要么假设推荐系统是一个单阶段系统,要么只研究如何将离策略校正应用于系统的候选生成阶段,而没有显式地考虑这两个阶段之间的相互作用。在这项工作中,我们提出了一种两阶段离策略(two-stage off-policy)策略梯度方法,并证明了在两阶段推荐系统中忽略这两个阶段之间的交互会导致次优策略。该方法在训练候选生成模型时明确考虑了排序模型,有助于提高整个系统的性能。我们在具有大项目空间的真实数据集上进行了实验,验证了所提方法的有效性。