谷歌发布电影动作数据集AVA,57600精准标注视频教AI识别人类行为

【AI WORLD 2017世界人工智能大会倒计时 16 天】
“AI达摩”齐聚世界人工智能大会,AI WORLD 2017议程嘉宾重磅发布
大会早鸟票已经售罄,现正式进入全额票阶段。还记得去年一票难求的AI WORLD 2016盛况吗?今年,即将于2017年11月8日在北京国家会议中心举办的AI World 2017世界人工智能大会上,我们请到CMU教授、冷扑大师发明人Tuomas Sandholm、 百度副总裁王海峰 、微软全球资深副总裁王永东、亚马逊AWS机器学习总监Alex Smola 、科大讯飞执行总裁胡郁,华为消费者事业群总裁邵洋、腾讯优图实验室杰出科学家贾佳亚等国内外人工智能领袖参会并演讲,一起探讨中国与世界AI的最新趋势。
点击文末阅读原文,马上参会!
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
大会官网:http://www.aiworld2017.com
新智元编译
来源:qz.com
作者:Dave Gershgorn 编译: 马文
【新智元导读】教机器理解视频中的人的行为是计算机视觉中的一个基本研究问题,谷歌最新发布一个电影片段数据集AVA,旨在教机器理解人的活动。 该数据集以人类为中心进行标注,包含80类动作的 57600 个视频片段,有助于人类行为识别系统的研究
数据集地址:https://research.google.com/ava/
论文:https://arxiv.org/abs/1705.08421

教机器理解视频中的人的行为是计算机视觉中的一个基本研究问题,对个人视频搜索和发现、运动分析和手势界面等应用十分重要。尽管在过去的几年里,对图像进行分类和在图像中寻找目标对象方面取得了令人兴奋的突破,但识别人类的动作仍然是一个巨大的挑战。这是因为动作的定义比视频中的对象的定义要差,因此很难构造一个精细标记的动作视频数据集。许多基准数据集,例如 UCF101、activitynet 和DeepMind 的 Kinetics,都是采用图像分类的标记方案,在数据集中为每个视频或视频片段分配一个标签,而没有数据集能用于包含多个可能执行不同动作的人的复杂场景。
谷歌上周发布一个新的电影片段数据集,旨在教机器理解人的活动。这个数据集被称为 AVA(atomic visual action),这些视频对人类来说并不是很特别的东西——仅仅是 YouTube 上人们喝水、做饭等等的3秒钟视频片段。但每段视频都与一个文件捆绑在一起,这个文件勾勒了机器学习算法应该观察的人,描述他们的姿势,以及他们是否正在与另一个人或物进行互动。就像指着一只狗狗给一个小孩看,并教他说“狗!”,这个数据集是这类场景的数字版本。
与其他动作数据集相比,AVA具有以下几个关键特征:
以人类为中心的标注(Person-centric annotation)。每个动作标签都与一个人相关联,而不是与一个视频或视频剪辑关联。因此,我们能够为在同一场景中执行不同动作的多个人分配不同的标签,这是种情况很常见。
原子视觉动作(Atomic visual actions)。我们将动作标签限制在一定时间尺度(3秒),动作需要是物理性质的,并且有清晰的视觉信号。
真实的视频材料。我们使用不同类型、不同国家的电影作为AVA的数据源,因此,数据中包含了广泛的人类行为。

3秒视频片段示例,每个片段的中间帧都有边界框标注。(为了清晰起见,每个样本只显示一个边界框)
当视频中有多个人时,每个人都有自己的标签。这样,算法就能知道“握手”的动作需要两个人。
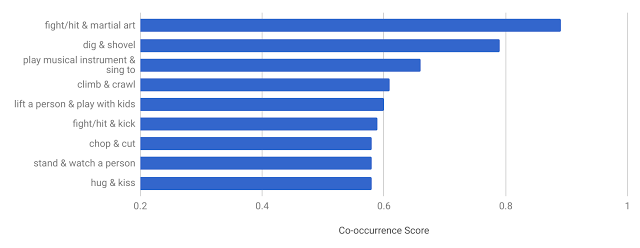
AVA 中共同出现频率最高的动作对
这项技术可以帮助谷歌分析 YouTube 上的视频。它可以应用来更好地投放定向广告,或用于内容过滤。作者在相应的研究论文中写道,最终的目标是教计算机社会视觉智能(social visual intelligence),即“理解人类正在做什么,他们下一步将会做什么,以及他们想要达到的目的。”
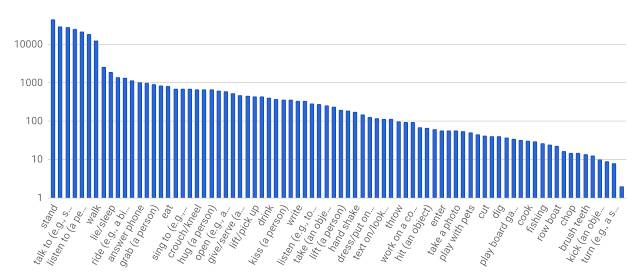
AVA 数据集的动作标签分布(x轴只包括了词汇表中的一部分标签)
AVA 数据集包含 57600 个标记好的视频,详细记录了80类动作。简单的动作,例如站立、说话、倾听和走路等在数据集中更有代表性,每个标签都有超过1万个视频片段。研究人员在论文中写道,使用电影中的片段确实会给他们的工作带来一些偏见,因为电影有其“语法”,一些动作被戏剧化了。
“我们并不认为这些数据是完美的。”论文中写道:“但这比使用由用户上传的内容更好,比如动物杂耍视频、DIY教学视频、儿童生日派对之类的视频等等。”
论文引用中试图找到“不同国籍的顶级演员”,但没有详细说明数据集可能会因种族或性别而产生偏见。研究者希望AVA的发布将有助于人类行为识别系统的研究,为基于个人行为层面的精细时空粒度的标签对复杂活动进行建模提供机会。
原文:https://qz.com/1108090/google-is-teaching-its-ai-how-humans-hug-cook-and-fight/

【AI WORLD 2017世界人工智能大会倒计时 16 天】点击图片查看嘉宾与日程。
大会门票销售火热,抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
【扫一扫或点击阅读原文抢购大会门票】
AI WORLD 2017 世界人工智能大会购票二维码:






