EMNLP 2020 | 基于反事实推理的开放域生成式对话
论文名称: Counterfactual Off-Policy Training for Neural Dialogue Generation 论文作者:朱庆福,张伟男,刘挺,王威廉 原创作者:朱庆福 论文链接:https://arxiv.org/abs/2004.14507 转载须标注出处:哈工大SCIR
2. 模型结构
2.1 结构因果模型(Structural Causal Model)
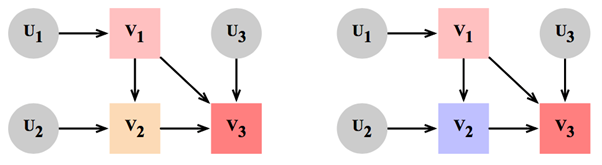
2.2 干预(Intervention)
2.3 反事实推理(Counterfactual Inference)
给定一个SCM并观测到随机变量 ,反事实推理的概念用于回答如下的问题:在SCM上执行一次干预操作而其他条件不变的情况下,随机变量 将会得到什么结果?因此,将生成式对话模型转化为SCM即可利用反事实推理回答:观测到回复 ,假设执行观测到对话策略的替代策略同时保持其他条件不变,回复Y将会得到什么结果?我们将得到的回复称为反事实回复。一方面,反事实回复扩展了训练过程中的回复空间,解决了训练数据不足的问题。另一方面,反事实回复从真实回复中推理得出,比其他对抗训练方法中随机合成的回复质量更高。因此,使用反事实回复训练模型可以进一步提升模型的表现。具体地,反事实推理的步骤为:
a. 给定真实回复 和其在生成式对话SCM下的生成过程: ,其中 为极大似然估计的用户对话策略,推理出真实回复的场景:
b. 将用户对话策略 替换为模型学习的策略
c. 根据替换后得到的生成式对话SCM, ,推理出在 下执行策略 的回复y
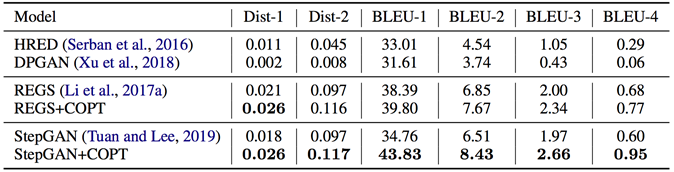
3. 实验结果
表1 自动评价实验结果
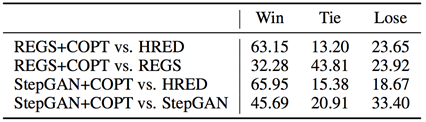
人工评价方面,共有5位标注者在200条测试数据上独立进行了评价。每位标注者在两条回复中挑选出更优的一个,其中的两条回复分别由基线方法和我们的方法生成。结果如表2所示,我们的方法取得了更优的结果。
表2 人工评价实验结果
4. 实验分析
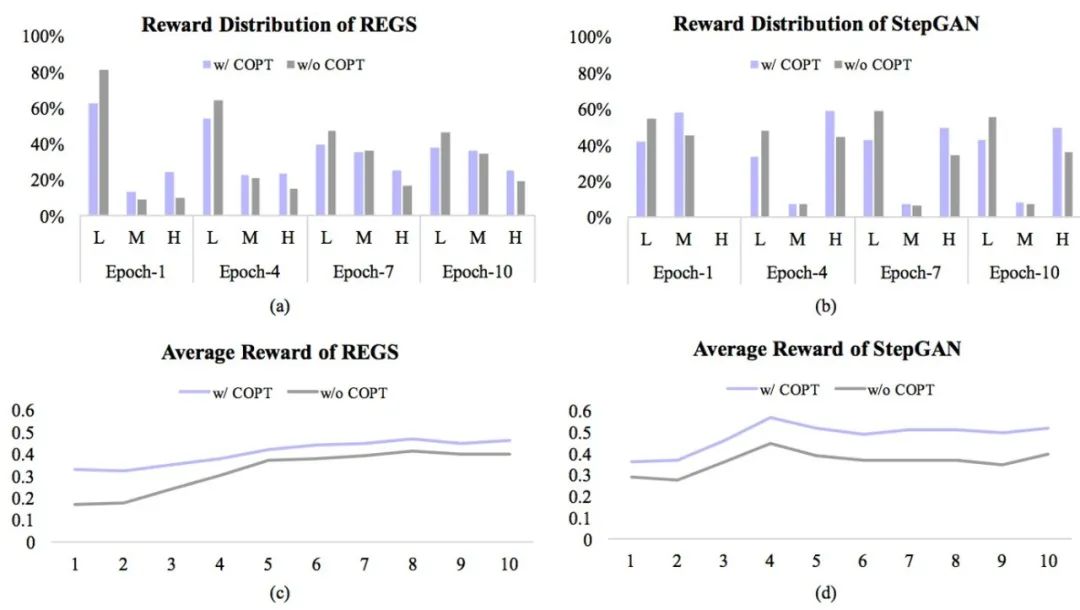
图2 反事实回复与基线回复的奖励分布、均值
5. 结论
参考文献
[1] Judea Pearl and Dana Mackenzie. 2018. The book of why: the new science of cause and effect. Basic Books.
[2] Lars Buesing, Theophane Weber, Yori Zwols, Nicolas Heess, Sebastien Racaniere, Arthur Guez, and Jean Baptiste Lespiau. 2019. Woulda, coulda, shoulda: Counterfactually-guided policy search. In Proceedings of the Seventh International Conference on Learning Representations.
[3] Michael Oberst and David Sontag. 2019. Counterfactual off-policy evaluation with gumbel-max structural causal models. In International Conference on Machine Learning, pages 4881–4890.
[4] Iulian V Serban, Alessandro Sordoni, Yoshua Bengio, Aaron Courville, and Joelle Pineau. 2016. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence.
[5] Jingjing Xu, Xuancheng Ren, Junyang Lin, and Xu Sun. 2018. Diversity-promoting GAN: A cross-entropy based generative adversarial network for diversified text generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3940–3949.
[6] Jiwei Li, Will Monroe, Tianlin Shi, Se ́bastien Jean, Alan Ritter, and Dan Jurafsky. 2017a. Adversarial learning for neural dialogue generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2157–2169.
[7] Yi-Lin Tuan and Hung-Yi Lee. 2019. Improving conditional sequence generative adversarial networks by stepwise evaluation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(4):788–798.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏

