近期必读的八篇【Meta-Learning(元学习)】相关论文和代码
【导读】Meta-Learning(元学习)是最新研究热点热,这两年相关论文非常多,结合最新的热点方法,在应用到自己的领域,已经是大部分研究者快速出成果的一个必备方式。元学习旨在通过一些训练少量样本可以学习新技能或快速适应新环境的模型!今天小编专门整理最新八篇Meta-Learning(元学习)包括NeuralPS、ICCV、EMNLP等顶会论文,涵盖图元学习、隐式梯度元学习等。

请关注专知公众号(点击上方蓝色专知关注)
后台回复“元学习” 就可以获取所有元学习论文下载链接~
1、Learning to Propagate for Graph Meta-Learning(图元学习的学习传播)
NeuralPS ’19 ,悉尼科技大学,华盛顿大学
作者:Lu Liu, Tianyi Zhou, Guodong Long, Jing Jiang, Chengqi Zhang
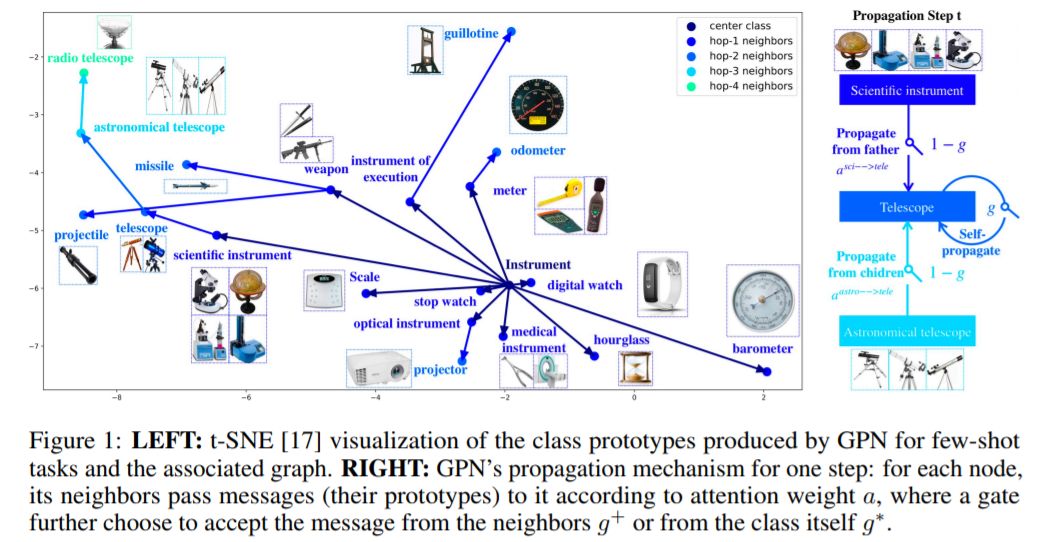
摘要:元学习旨在从学习不同任务中获得共同知识,并将其用于不可见的任务。它在训练数据不足的任务上,如少样本学习的任务上,显示出明显的优势。在大多数元学习方法中,任务是通过共享模型或优化器隐式关联的。在这篇论文中,我们证明了一个元学习器可以显式地将任务与描述其输出维度(如类)关系的图表联系起来,从而显著地提高少样本学习的性能。这种类型的图通常是免费或廉价获得的,但在以前的工作中很少进行探索。我们研究了基于原型的少样本分类,其中每个类生成一个原型,使原型之间的最近邻搜索产生一个准确的分类。引入“门控传播网络(GPN)”,学会在图上不同类的原型之间传播消息,使学习每个类的原型受益于其他相关类的数据。在GPN中,注意机制用于聚合来自邻近类的消息,并部署了一个gate来在聚合的消息和来自类本身的消息之间进行选择。GPN是针对子图抽样生成的多样本到少样本的任务序列进行训练的。在训练期间,它能够重用和更新以前实现的原型从记忆中在一个终身学习周期。在实验中,我们改变了训练-测试差异和测试任务生成设置,以进行彻底的评估。在所有的实验中,GPN在两个基准数据集上都优于最近的元学习方法。
网址:
https://www.zhuanzhi.ai/paper/61e36771d2ee93c416e8eb2ebed7c307
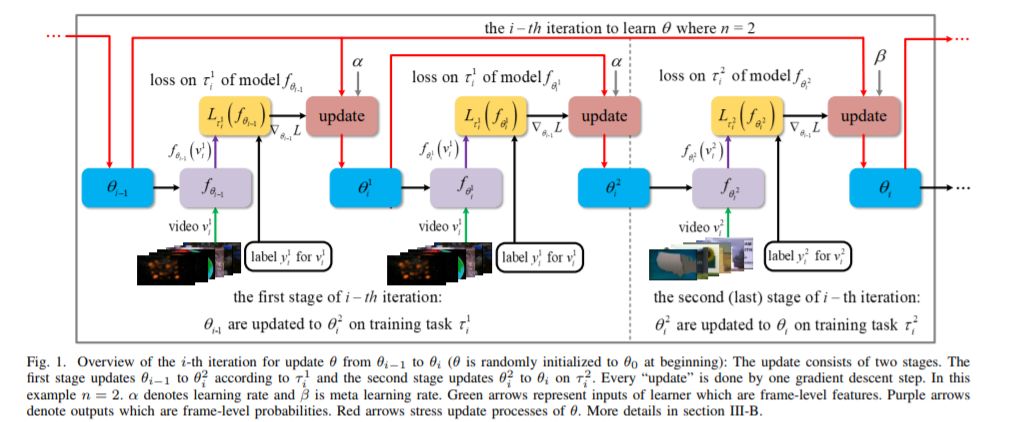
2、Meta-Learning with Implicit Gradients(隐式梯度元学习)
NeuralPS ’19 ,加州大学伯克利分校
作者:Aravind Rajeswaran, Chelsea Finn, Sham Kakade, Sergey Levine
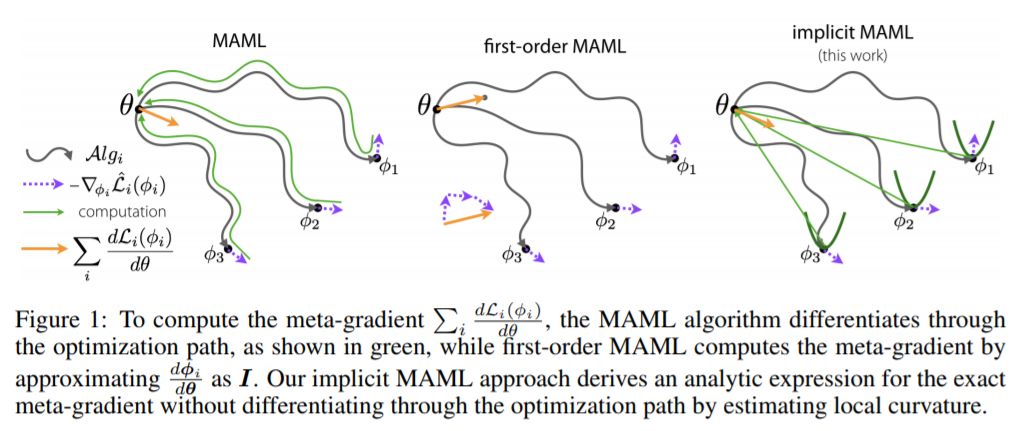
摘要:智能系统的一个核心能力是能够通过借鉴以往的经验快速学习新任务。基于梯度(或优化)的元学习是近年来出现的一种有效的学习方法。在这个范式中,元参数在外部循环中学习,而特定于任务的模型在内部循环中只使用当前任务的少量数据学习。扩展这些方法的一个关键挑战是需要通过内部循环学习过程进行区分,这可能带来相当大的计算和内存负担。利用隐式微分法,提出了隐式MAML算法,该算法只依赖于内部层次优化的解,而不依赖于内部循环优化器所采用的路径。这有效地将元梯度计算与内部循环优化器的选择解耦。因此,我们的方法对内部循环优化器的选择是不可知的,并且可以优雅地处理许多梯度步骤,而不会消失梯度或内存约束。从理论上,我们证明了隐式MAML可以计算精确的元梯度,其内存占用不超过计算单个内循环梯度所需的内存占用,且不增加总计算成本。实验表明,隐式MAML的这些优点可以转化为基于少量样本图像识别基准的经验增益。
网址:
https://www.zhuanzhi.ai/paper/75b6ea47af934e635108622e60e66c44
https://sites.google.com/view/imaml
3、Learning to Learn and Predict: A Meta-Learning Approach for Multi-Label Classification (学会学习和预测:一种用于多标签分类的元学习方法)
EMNLP ’19 ,加州大学圣塔芭芭拉分校
作者:Jiawei Wu, Wenhan Xiong, William Yang Wang
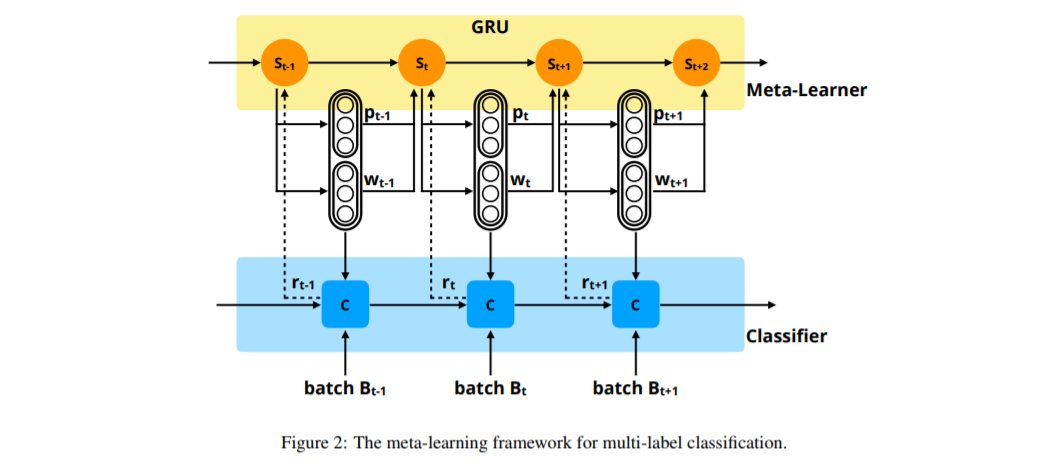
摘要:自然语言处理中的许多任务都可以看作是多标签分类问题。然而,现有的模型大多采用标准的交叉熵损失函数训练,对所有的标签使用固定的预测策略(如阈值0.5),完全忽略了不同标签之间的复杂性和依赖性。在本文中,我们提出了一种元学习方法来捕获这些复杂的标签依赖关系。更具体地说,我们的方法利用元学习者来共同学习不同标签的训练策略和预测策略。然后利用训练策略训练具有交叉熵损失函数的分类器,并进一步实现预测策略进行预测。基于细粒度实体分类和文本分类的实验结果表明,该方法能够获得更准确的多标签分类结果。
网址:
https://www.zhuanzhi.ai/paper/a443f941e075d1df7dbccf3b5cf55568
4、Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs (元关联学习用于知识图谱中少样本链接预测)
EMNLP ’19 ,浙江大学,阿里巴巴
作者:Mingyang Chen, Wen Zhang, Wei Zhang, Qiang Chen, Huajun Chen
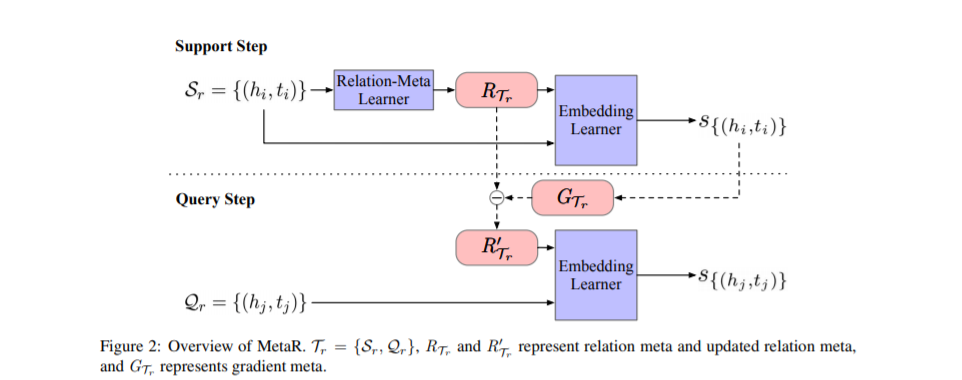
摘要:链接预测是完成知识图谱(KGs)的一种重要方法,而基于嵌入的方法是KGs中链接预测的有效方法,但在只有少量关联三元组的关系上,其性能较差。在这项工作中,我们提出了一个元关系学习(MetaR)框架来做KGs中常见但具有挑战性的少量样本链接预测,即通过观察几个关联三元组来预测一个关系的新三元组。通过重点转移关系相关的元信息,使模型学习最重要的知识,学习速度更快,从而解决了少样本链接预测问题,分别对应于MetaR中的关系元和梯度元。从经验上看,我们的模型在少样本链路预测KG基准上取得了最先进的结果。
网址:
https://www.zhuanzhi.ai/paper/a443f941e075d1df7dbccf3b5cf55568
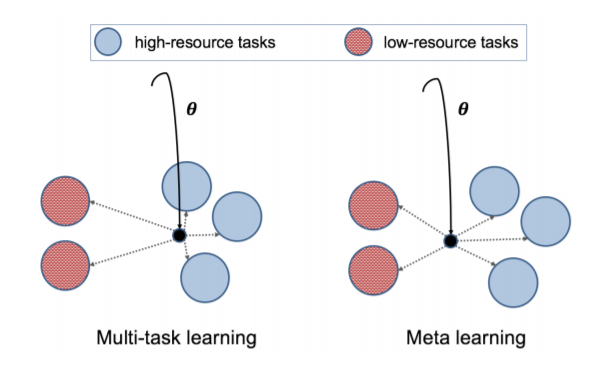
5、Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks(研究低资源自然语言理解任务的元学习算法)
EMNLP ’19 ,卡内基梅隆大学CMU
作者:Zi-Yi Dou, Keyi Yu, Antonios Anastasopoulos
摘要:学习文本的一般表示是许多自然语言理解(NLU)任务的一个基本问题。以前,研究人员提出使用语言模型预训练和多任务学习来学习鲁棒表示。然而,这些方法在低资源场景下获得次优性能。受最近基于优化的元学习算法成功的启发,本文研究了模型无关元学习算法(MAML)及其在低资源NLU任务中的变体。我们在GLUE基准测试上验证了我们的方法,并表明我们提出的模型可以优于几个强基线。我们进一步的经验证明,学习表征可以有效地适应新的任务。
网址:
https://www.zhuanzhi.ai/paper/d7271232452b98d7ff27301681fa65e7
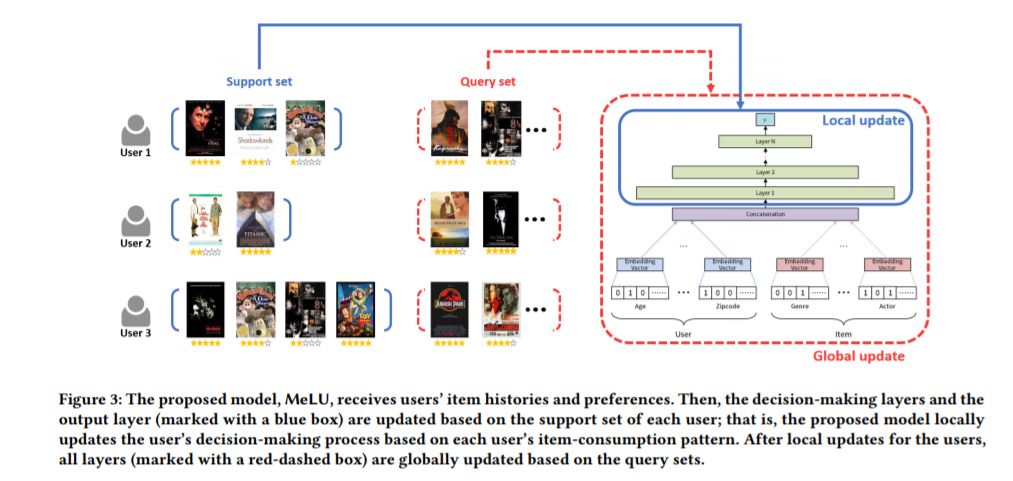
6、MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation (MeLU:用于冷启动推荐的元学习用户偏好估计器)
KDD ’19 ,韩国NCSOFT
作者:Hoyeop Lee, Jinbae Im, Seongwon Jang, Hyunsouk Cho, Sehee Chung
摘要:本文提出了一种新的推荐系统,解决了基于少量样本物品来估计用户偏好的冷启动问题。为了确定用户在冷启动状态下的偏好,现有的推荐系统,如Netflix,最初向用户提供商品;我们称这些物品为候选证据。然后根据用户选择的物品提出建议。以往的推荐研究有两个局限性:(1)消费了少量商品的用户推荐不佳,(2)候选证据不足,无法识别用户偏好。为了克服这两个限制,我们提出了一种基于元学习的推荐系统MeLU。从元学习中,MeLU可以通过几个例子快速地采用新任务,通过几个消费项来估计新用户的偏好。此外,我们提供了一个证据候选选择策略,以确定自定义偏好估计的区分项目。我们用两个基准数据集对MeLU进行了验证,与两个比较模型相比,该模型的平均绝对误差至少降低了5.92%。我们还进行了用户研究实验来验证证据选择策略。
网址:
https://www.zhuanzhi.ai/paper/041f96c7f86a79ebdf9399ea61405aa7
7、Meta Learning for Task-Driven Video Summarization (元学习用于任务驱动的视频摘要)
IEEE Transactions on Industrial Electronics, 2019 ,西北工业大学
作者:Xuelong Li, Hongli Li, Yongsheng Dong
摘要:现有的视频摘要方法主要集中于视频数据的序列或结构特征。然而,他们对视频摘要任务本身并没有给予足够的重视。本文提出了一种基于任务驱动的视频摘要元学习方法(MetaL-TDVS),明确探索了不同视频摘要过程之间的视频摘要机制。其中MetaL-TDVS旨在通过将视频摘要重新定义为元学习问题,挖掘视频摘要的潜在机制,提高训练模型的泛化能力。MetaL-TDVS将每一个视频的总结作为一个单独的任务,更好的利用总结其他视频过程中学习到的经验和知识来总结新的视频。此外,MetaL-TDVS通过两倍反向传播对模型进行更新,使模型在一个视频上得到优化,从而在每个训练步骤中对另一个视频获得较高的精度。在基准数据集上的大量实验表明,金属- tdvs相对于几种最先进的方法具有优越性和更好的泛化能力。
。
网址:
https://www.zhuanzhi.ai/paper/e5ecefaca79ad73526af031b6aec6fb6
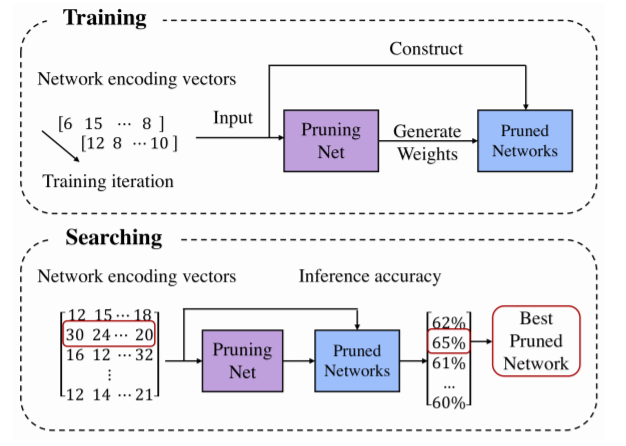
8、MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning (MeLU:用于冷启动推荐的元学习用户偏好估计器)
ICCV’19 ,清华大学,旷视科技
作者:Zechun Liu, Haoyuan Mu, Xiangyu Zhang, Zichao Guo, Xin Yang, Tim Kwang-Ting Cheng, Jian Sun
摘要:在本文中,我们提出了一种新的元学习方法来自动剪枝非常深的神经网络的通道。我们首先训练一个剪枝网络,这是一种元网络,它能够为给定目标网络的任何剪枝结构生成权重参数。我们使用一种简单的随机结构抽样方法来训练剪枝网络。然后,应用进化过程搜索性能良好的剪枝网络。由于权值直接由训练过的剪枝网络生成,因此在搜索时不需要任何微调,因此搜索效率很高。通过对目标网络的单一剪枝网络进行训练,我们可以在不需要人工参与的情况下搜索不同约束条件下的各种剪枝网络。与目前最先进的剪枝方法相比,我们已经在MobileNet V1/V2和ResNet上展示了优越的性能。代码可以在https://github.com/liuzechun/runing上找到
。
网址:
https://www.zhuanzhi.ai/paper/e5ecefaca79ad73526af031b6aec6fb6
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




