论文浅尝 - ESWC2020 | ESBM:一个面向实体摘要的评测集
本文转载自公众号:南大Websoft。
实体摘要(Entity Summarization),是知识图谱研究与应用中的一个关键问题。南京大学Websoft团队为此制作了一个评测集,称作ESBM,是目前可以公开获取的规模最大的评测集。这项工作被知识图谱领域重要国际会议ESWC 2020(CCF-C类)授予“最佳资源论文提名奖”。以下是论文第一作者博士生刘庆霞对这项工作的介绍。
引言
RDF数据集,如知识图谱,采用大量三元组描述实体。实体摘要的任务,就是从描述给定实体的大量三元组中,选出一个满足容量限制的最优子集作为实体的摘要。研究领域对该问题提出了多种求解方法,然而这些方法之间缺乏统一的比较。原因之一在于缺乏高质量的评测集。为此,我们构建并发布了评测集ESBM,其是目前实体摘要领域公开发布的规模最大的评测集。此外,基于ESBM,我们实验评测了9个现有实体摘要方法,以及基于监督学习的实体摘要方法。
本文介绍了ESBM评测集的构造、分析和相关评测实验的主要内容,更多详细内容,欢迎阅读我们发表在ESWC 2020的研究论文:
Qingxia Liu, Gong Cheng, Kalpa Gunaratna, Yuzhong Qu: ESBM: An Entity Summarization BenchMark. ESWC 2020: 548-564
该评测集的相关数据和代码已在GitHub公开发布:https://github.com/nju-websoft/ESBM
一、研究背景
RDF数据以三元组形式描述实体相关的属性-值信息,我们将用于描述某个特定实体的三元组构成的集合称为该实体的实体描述。例如,在下图所示关于实体“Tim Berners-Lee”的实体描述中,三元组<Tim Berners Lee, alias, “TimBL”>描述了该实体的属性“alias”和值“TimBL”。

在大规模RDF数据集中,实体描述所包含的三元组数量庞大,往往超出应用场景所能提供的容量。例如,在谷歌搜索结果页面的实体卡片中,通常只提供了10行以内的空间用以呈现实体相关的属性-值内容。实体摘要的任务就是从实体描述所包含的大量三元组中,选出给定容量限制内的子集,以满足用户的信息需求。
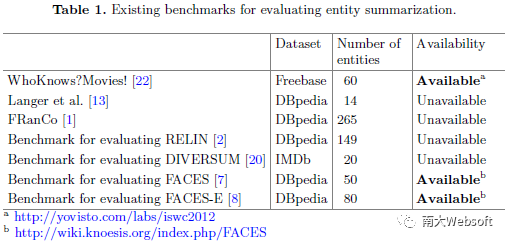
然而,实体摘要领域的发展面临两个挑战。其一,是缺乏高质量的评测集。表1列出了实体摘要领域目前已知的评测集。可以看出,这些评测集都基于单个数据集,并且所包含的实体数量也有限。在列出的7个评测集中,其中4个已无法公开获取,而WhoKnows?Movies!面向特定领域的摘要任务,而FACES和FACES-E所构造的评测集则未包含取值为字面量或类的三元组。其二,是缺乏统一的评测实验,缺乏为后续研究和应用在技术选择上提供参考的依据。面对这两个挑战,我们提出ESBM评测集,在其设计中克服现有评测集的上述问题,同时基于ESBM对大量现有实体摘要方法进行了统一的实验比较。
二、ESBM构造过程
我们在ESBM的设计中要求其满足两个目标:首先,应当满足[18]提出的高质量评测集应当满足的7个条件; 其次,要避免上述现有评测集所存在的问题。我们构造ESBM用来评价实体摘要系统生成的摘要的质量。一个实体摘要任务,需要给定实体描述作为输入;而要评价一个摘要的质量,则通常采取与标准摘要进行比较的方式来得到。所以,我们将从两个方面来介绍ESBM的构造过程,即实体描述的数据选择,以及标准摘要的收集。
实体描述
针对现有评测数据涉及的RDF数据集单一的问题,我们考虑了两个不同类型RDF数据集:百科型数据集DBpedia,和特定领域型数据集LinkedMDB。我们从这两个数据集分别选择覆盖度最高的实体类型,从这些类型中随机选择实体作为实体,并抽取其实体描述所涉及的三元组。最终,我们从DBedia中选出了5个实体类型:Agent,Event,Location,Species,Work;从LinkedMDB中选出了2个实体类型:Film,Person。每个类型随机选择25个实体(要求实体描述中包含至少20个三元组),就得到了相应的175个实体描述。实体描述中,对取值为字面量、类型、实体的三种三元组都有涉及。
标准摘要
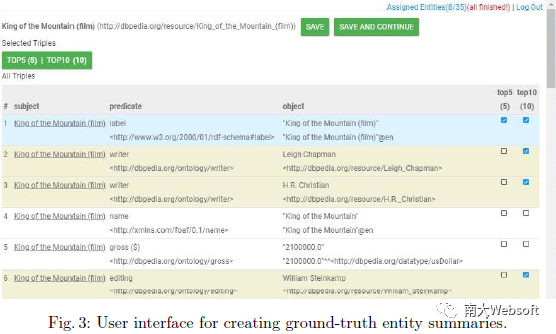
我们邀请了30位用户来对所选实体标注标准摘要。每个用户负责标注35个实体,而每个实体可以得到6个不同用户的标注。在每个标注任务中,用户需要对应两种不同容量限制(k=5,k=10)对实体各标注一个标准摘要,分别称为top-5摘要和top-10摘要。标注的方式,即从实体描述的所有三元组中,选出k个三元组来构成用户认为最佳的摘要。标注系统截图如下图所示。最终,我们得到175*6*2=2100个标准摘要。
数据划分
一些实体摘要方法的开发需要调参,为此,我们对ESBM数据进行了训练集、验证集和测试集的划分。为了支持以5折交叉验证的方式评测摘要方法,我们将ESBM中的175个实体划分成五等份P(0),…,P(4),交替将这些等份分别归入训练集、验证集和测试集,并使三者所含实体比例为3:1:1。具体做法为,在第i折数据中,P(i),P(i+1 mod 5),P(i+1 mod 5)作为训练集,P(i+3 mod 5)作为验证集,P(i+4 mod 5)作为测试集。最终报告的评测结果为各折测试集上结果的平均值。
三、ESBM数据分析
接下来,我们通过分析ESBM收集的数据,来对实体摘要的特点和目标有更具体的认识。
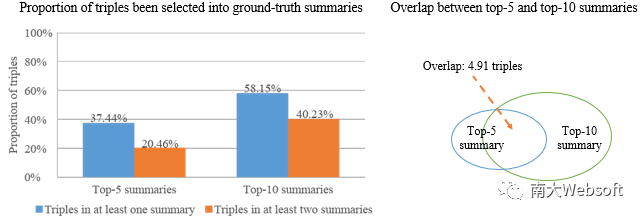
总体而言,ESBM包含175个实体,共6584个三元组。其中,37.44%的三元组被选入过top-5摘要,而58.15%的三元组被选入过top-10摘要。每个实体由6个用户标注。然而,大多数三元组仅被一个用户选入过标准摘要。20.46%三元组被至少两个用户选入过top-5摘要,而对top-10摘要该比例则为40.23%.
一个常被问到的问题是:top-5摘要是否一定是top-10摘要的子集?在标准答案的标注过程中,我们并没有对此做任何限制。我们分析ESBM的各类实体中,同一个用户构造的top-5和top-10摘要之间选入相同三元组的情况,结果平均有4.80-4.99的三元组同时出现在top-5和top-10摘要中。而在所有实体范围内,top-5和top-10摘要平均有4.91个三元组相同,非常接近top-5摘要容量为5的设定,说明top-5摘要很大程度上来源于top-10摘要的子集。
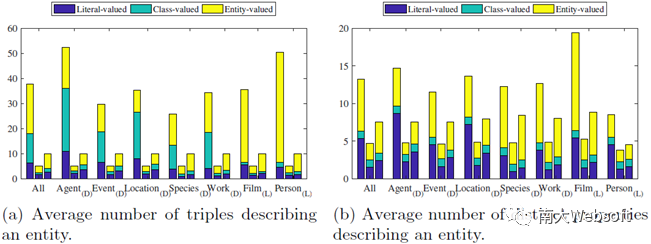
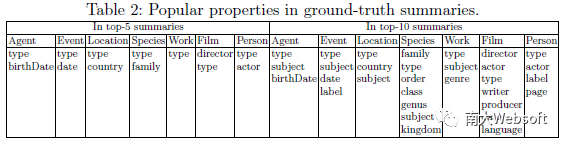
下图按实体类型呈现了ESBM中各实体集的三元组构成情况。我们分析ESBM中三类实体集:实体描述、top-5摘要、top-10摘要,分别对应柱状图中每组的左、中、右三个柱子。图(a)统计取值分别为字面量(Literal)、类型(Class)和实体(Entity)的三类三元组在各集合中的数量。 可以看出取值为字面量的三元组,虽然在实体描述中占比不高,但在标准摘要中都占有较大的比例,其在top-5和top-10摘要中分别占比30%和25%。这说明,若实体摘要方法将字面量类型的三元组排除在任务之外,将影响其摘要质量。图(b)统计的是各类三元组所占属性的个数。其中,在top-5摘要平均包含4.7个不同属性(非常接近5),说明用户倾向于从不同属性中选取三元组来构造摘要,避免出现属性的冗余。
我们再来分析实体的异质性。下图列出了不同实体类型所涉及的属性集之间的Jaccard相似度。结果表明不同类型间该相似度极低,体现了不同类型实体描述之间的较高的异质性, 也说明ESBM选择的数据有助于评价实体摘要方法的泛化能力。

下表列出了各类实体中,出现在至少一半的标准摘要中的属性。平均每个实体包含13个不同属性,而该表中的结果是仅有一两个属性是top-5标准摘要中常见的。这说明各个实体的标准摘要涉及的属性各有不同,所以通过人工为每个类型制定实体统一制定摘要的方式不太可行。
在ESBM中,每个实体被6个不同用户标注,并在每种容量限制下各得到6个标准摘要。我们计算同一个实体的这6个标准摘要之间的一致情况。下表中将ESBM上统计的平均一致程度与相关评测集在其文献中给出的结果进行了比较。结果表明ESBM的标准摘要之间存在中等程度的一致。

四、ESBM实验结果
我们采用ESBM对实体摘要方法进行评测,参与评测的方法包括:
现有实体摘要方法:我们选取了9个方法,即RELIN, DIVERSUM, LinkSUM, FACES, FACES-E, CD, MPSUM, BAFREC, KAFCA,用以代表该问题当前研究水平;
ORACLE方法:基于标准摘要构造摘要的方法,即优先选取被标准答案选中次数最多的三元组进入摘要,该方法用以近似体现在ESBM上能达到的最佳水平;
基于监督学习的实体摘要方法:不同于以往的实体摘要方法,我们尝试探索监督学习在解决实体摘要问题上的潜力,我们利用了三元组的7个特征,并分别基于6种监督学习模型构造了实体摘要方法。
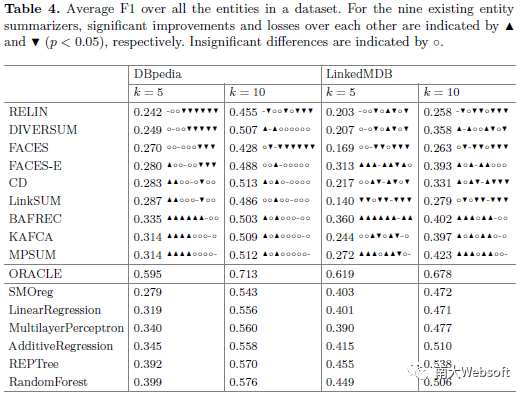
总体评测结果如下表所示,从中我们可以得出以下结论:
现有实体摘要方法中,BAFREC, MPSUM, CD分别在不同设定下达到优于其他方法的效果;
监督学习方法的效果普遍好于现有实体摘要方法;
上述两类方法的最佳效果与ORACLE相比仍有较大差距。
这同时也说明,ESBM中的实体摘要任务有一定的难度,有利于促进后续研究工作提出更为有效的摘要方法。
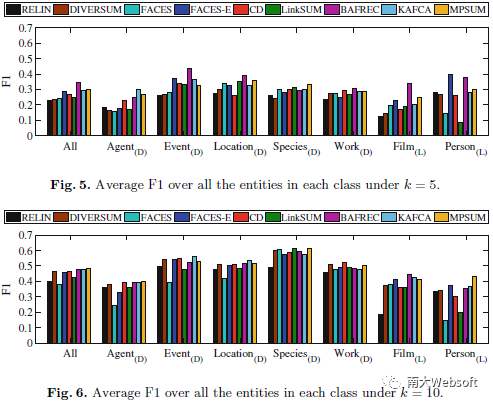
此外,我们还分析了现有摘要方法在不同类型实体上的表现,如下图所示。从中可以看出,在k=5时,BAFREC和MPSUM的效果在处理不同类型实体上具有较高的泛化能力,而在k=10时,MPSUM同样表现出相对较高的泛化能力。
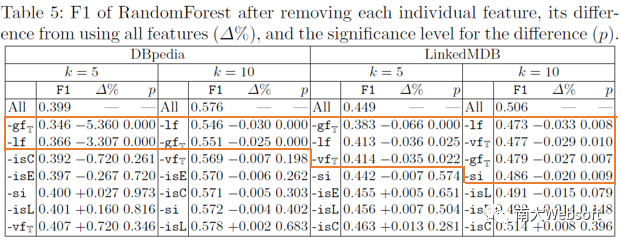
对于监督学习方法,我们进行消融实验分析7个特征对模型效果的影响,结果如下表所示。可以看出,属性的全局频度(gf_T),属性的局部频度(lf),对模型效果有显著影响,删除这些特征将导致摘要效果显著降低;取值的全局频度(vf_T),三元组的自信息(si)仅在LinkedMDB数据集上表现出显著有效。而关于取值类别的三个布尔型特征,即取值是否为类型(isC)、是否为实体(isE)、是否为字面量(isL)则未带来摘要F1值的显著变化。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



