吴恩达团队新研究:在ImageNet上优化的模型,真的能更好胜任医学影像任务吗?

新智元推荐
新智元推荐
来源:数据实战派
作者:青苹果
【新智元导读】有观点认为,经 ImageNet 检验的架构越好,性能效果便越佳,本文所讲述的这项工作中,斯坦福大学吴恩达团队则给出不一样答案。

目前,已经有不少深度学习模型被广泛地用于辅助性的胸片(Chest X-Ray)解释,这有助于帮助减轻临床医生的日常工作。
其中,使用预训练的 ImageNet 模型进行迁移学习,已经成为开发模型的标准方法,不仅适用于胸片,也适用于许多其他医学成像模式。
因此,有观点认为,经 ImageNet 检验的架构越好,性能效果便越佳,以及调整预训练的权重可以提高目标医疗任务的性能等。
用于胸片解释的深度学习方法通常依赖于为 ImageNet 开发的预训练模型。与此同时,该范例假设,更好的 ImageNet 架构在胸片任务上表现得更好,并且 ImageNet 预训练的权重比随机初始化所提供的性能更高。
本文所讲述的这项工作 “CheXtransfer: Performance and Parameter Efficiency of ImageNet Models for Chest X-Ray Interpretation” 中,斯坦福大学吴恩达团队则给出不一样答案。
通过在大型胸片数据集 CheXpert 上比较 16 种流行的卷积架构的迁移性能和参数效率,他们探索了 ImageNet 架构和权重两个因素与胸片任务的性能之间的关系。
团队发现,无论模型是否经过预训练,基于 ImageNet 的体系结构改进带来的性能提升,和 CheXpert 性能之间并无明显关系。
CheXpert 数据集和模型的选择
该研究所使用的 CheXpert 数据集,由吴恩达带领的斯坦福团队所开发的,相关文章 “CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison” 发表在 AAAI2019 上。
这个大型数据集包含了源自 65,240 例患者的 224,316 张带标注的胸片,以及放射科医师为每张胸片写的病理报告。每份报告都对 14 项观察进行具体标记:阳性(positive),阴性 (negative) 或不确定性 (uncertain)。
团队比较感兴趣的任务是,从单张或多张胸片中预测不同病理的可能性。
他们使用的便是上文所说的 CheXpert 数据集中曾指定的 5 个比赛任务 —— 肺不张(Atelectasis)、心脏肥大(Cardiomegaly)、肺实变(Consolidation)、肺水肿(Edema)、胸腔积液(Pleural Effusion)以及健康(No Finding)类别中的 AUROC 指标(AUC)的平均值对模型进行评估,以平衡验证集中的临床重要性和患病率。
他们从 PyTorch 1.4.0 上实现的公共检查点中选择了 16 个在 ImageNet 上预训练的模型:DenseNet(121、169、201),ResNet (18、34、 50、101),Inception (V3、V4),MNASNet,EfficientNet (B0、B1、B2、B3)和 MobileNet(V2、V3),并分别在有 / 无预训练参与的情况下对这些架构进行了微调和评估。
对于每个模型,团队对 CheXpert 训练集上的参数进行微调。如果模型经过了预训练,使用从 ImageNet 学习的均值和标准差对输入进行归一化;反之,使用 CheXpert 学习的均值和标准差进行归一化。
至于参数的更新,团队选择使用 Adam 优化器,其中,学习率为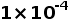
模型分为 3 个 epochs 进行训练,并按照 8192 个梯度步长来评估每个模型。团队成员对每个模型进行训练,并从 10 个检查点中创建最终的集成模型,该模型在验证集的 6 个任务中获得了最佳的 CheXpert AUC 均值。所有结果均在 CheXpert 测试集中给出报告。
此外,团队使用非参数 bootstrap 估计每个统计量的置信区间:从测试集中抽取 1000 个副本,并计算每个副本的统计量并生成分布,使用 bootstrap 值的第 2.5 个百分位数和第 97.5 个百分位数作为 95% 的置信区间。
对挑选出的四个模型(DenseNet121、MNASNet、ResNet18 和 EfficientNetB0)进行截断操作后,团队附加了一个分类块,其中包含一个全局平均池化层,既大量减少了参数量,还保持了图像的空间结构;然后使用一个全连接层,分配权重,以产生正确形状(shape)的输出。除了随机初始化分类块外,团队使用 ImageNet 预训练的权重来初始化模型,并使用与 16 个 ImageNet 模型相同的训练过程进行微调。
局限性所在
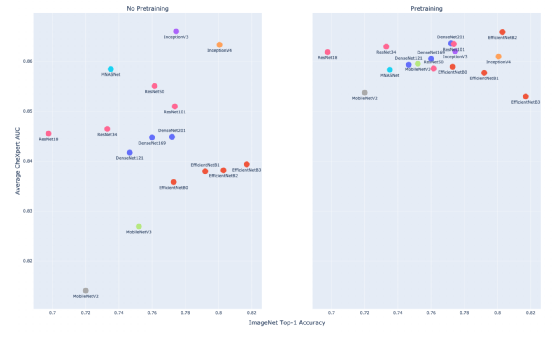
上图形象展现了是否经过 ImageNet 预训练的 CheXpert AUC 与 ImageNet top-1 精度之间的关系,其中左侧图表示没有进行预训练,右侧则表示模型经过预训练。
显然,在没有预训练的情况下,团队发现 ImageNet top-1 的准确率与 CheXpert AUC(斯皮尔曼相关系数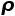
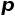
而在模型经过预训练的情况下,研究团队再次观察到 ImageNet top-1 的准确率与 CheXpert AUC(斯皮尔曼相关系数
由此,可得出以下结论, ImageNet 和 CheXpert 的性能之间无关,所以在 ImageNet 上成功的模型不一定在 CheXpert 上仍然成功。
换句话说,ImageNet 性能与 CheXpert 性能之间的关系远弱于 ImageNet 性能与各种自然图像任务性能之间的关系。
其次,研究团队还比较了 CheXpert 在架构族内部和跨架构族的性能,同样也是分两种情况进行讨论。在没有预训练的情况下,ResNet101 的 AUC 性能表现只比 ResNet18 高出 0.005,这完全在该度量的置信区间内。
与之相类似,DenseNet201 的 AUC 性能表现比 DenseNet121 高 0.004,EfficientNetB3 的 AUC 性能表现比 EfficientNetB0 高 0.003。
而在经过预训练的情况下,团队继续发现了在每个族中进行测试的最大模型和最小模型间的微小性能差异。
其中,ResNet、DenseNet 和 EfficientNet 的 AUC 值分别增加了 0.002、0.004 和 - 0.006。由此说明,在一个模型族内增加复杂性并不会像在 ImageNet 中增加相应的性能那样对 CheXpert 的性能带来影响。
模型架构重要吗?
这项研究中,在没有预训练参与的情况下,所研究的最好的模型的性能显著高于所研究的最差模型。
其中,InceptionV3 的性能最好,AUC 值为 0.866,而 MobileNetV2 的 AUC 值最差,为 0.814。显然,两者性能差值为 0.052。对应于前面的介绍,InceptionV3 是研究团队选择的所有研究体系中的第三大架构,而 MobileNetV2 则是最小的。这些模型的 CheXpert 性能存在显著差异,这种差异也再次暗示出模型架构设计的重要性。
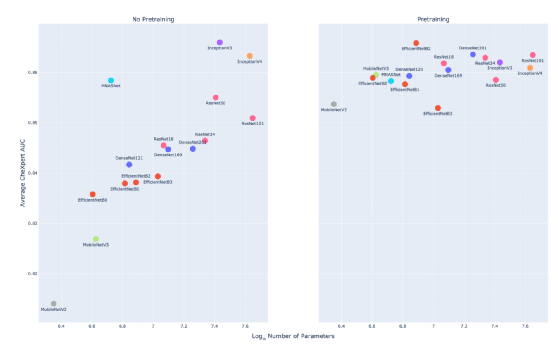
在团队研究的过程中,模型架构的大小是由多参数来衡量的,如上图所示。
在未经过 ImageNet 预训练的情况下,体系结构的参数数量和 CheXpert 性能(斯皮尔曼相关系数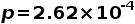
举例来说,ResNet101 的模型架构比 EfficientNetB0 要大 11.1 倍,而 CheXpert AUC 值在预训练的情况下却只增加了 0.005。这说明,在模型族中,增加参数数量并不会给 CheXpert AUC 值带来有意义的收益。如图 3 所示,研究团队所研究所有未经过预训练的模型族(EfficientNet、DenseNet、ResNet)中均可以发现这种关系。
例如,DenseNet201 模型的 AUC 值比 DenseNet121 仅高出 0.003,但模型规模上却比 DenseNet121 要大 2.6 倍。EfficientNetB3 的 AUC 值比 EfficientNetB0 高出 0.004,但模型规模上却比 EfficientNetB0 大 1.9 倍。
这显然说明,尽管在所有的模型中,模型的规模与 CheXpert 性能之间存在正相关关系,但在模型族中,规模越大却并不一定意味着性能越好。因为在模型族中,模型的规模大小与 CheXpert 性能之间的关系比在所有模型中都弱。
并且,CheXpert 性能更多地受宏观架构设计的影响,而非大小。族内的模型具有相似的架构设计选择,但大小不同,因此它们在 CheXpert 上的性能表现相似。此外,团队还观察到不同架构族之间的性能差异很大。举例来说,无论规模大小如何,DenseNet、ResNet 和 Inception 通常都优于 EfficientNet 和 MobileNet 架构。
需要注意的是,EfficientNet、MobileNet 以及 MNASNet 等架构在某种程度上均通过神经网络架构搜索(NAS,Neural Architecture Search)而生成,这一过程对 ImageNet 的性能进行了优化。研究团队的这一发现也就暗示出,上述的搜索可能对自然图像目标过度拟合,从而在胸片任务上造成一定程度上的削弱。
ImageNet 预训练对 CheXpert 性能有帮助吗?
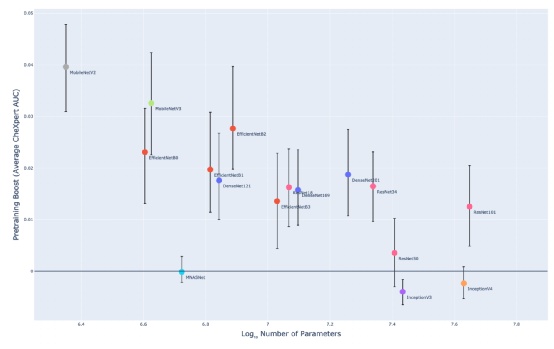
上图显示了预训练增强与模型大小的关系。
团队发现 ImageNet 预训练对大多数架构(AUC 均值为 0.015)提供了有意义的提升。并且斯皮尔曼系数为
因此,对于较小的架构,如 EfficientNetB0 (0.023),MobileNetV2 (0.040) 和 MobileNetV3 (0.033),这种提升往往会更大;而对于较大的架构,像 InceptionV4 (−0.002) 和 ResNet101 (0.013),提升则较小。但这种关系仍需要进一步地研究才能得到更好的解释。
在模型族内,预训练提升不会随着模型尺寸大小的增加而有意义地增加。例如,DenseNet201 的预训练提升的 AUC 值仅比 DenseNet121 高 0.002。这一发现也刚好支撑了团队先前的结论,即无论规模大小,模型族在 CheXpert 上的性能表现都是相似的。
最后,简单总结,本研究的主要贡献在于以下 4 点:
(1)ImageNet 和 CheXpert 性能之间并没有统计学上的显著关系,胸片解释任务与自然图像分类存在很多不同之处。
(2)模型架构的选择很重要,对于未进行预训练的模型,模型架构族的选择对性能的影响可能大于模型的规模大小。
(3)ImageNet 的预训练是有帮助的,团队发现 ImageNet 的预训练在胸片分类的性能上具有显著提高。
(4)模型架构可以通过截断策略而变得更小,这种方法可以保留结构体系设计的关键组成部分,同时减小其规模,研究团队通过截断 ImageNet 预训练的体系结构的最终块,可以使模型的参数效率平均提高 3.25 倍,而性能没有统计学上的显着下降。
Refrence:
1、https://arxiv.org/pdf/2101.06871.pdf
本文来自公众号“数据实战派”。“数据实战派”希望用真实数据和行业实战案例,帮助读者提升业务能力,共建有趣的大数据社区。