中文NLP难于英文?从语言学角度看中文NLP、NLU难在哪里
本文结合语言学和 NLP 的几个基本任务,从理论上对中文 NLP 的特点进行说明,同时展望 NLU 在中文自然语言交互上的一些方向。
1.中文分词
词是最小的能够独立运用的语言单位。「词」这个概念,是从西方引入的,在 1898 年《马氏文通》出版之前,传统的语言学研究对象是「字」,而不是「词」。汉语和英语最直观、最明显的不同,就是英语的词是天然的,由空格分开,而汉语的字紧密排列,从形式上看,其实没有「词」这个单位。
现代汉语的典型特征之一是双音节词占优势。古汉语常常是一字即一词,而现代汉语都把它们双音节化了,比如「目-->眼睛」「悦-->高兴、喜欢」。如果单单把「睛」、「兴」等字拿出来,它们承载的意义与原词是有差异的。加之考虑到实际应用的需求,以词为索引可以减小搜索空间、加快搜索速度、提高准确率,所以做分词是有必要的。
由于汉语的特殊性,在分词任务中,会碰到两种歧义现象:交叉歧义 (Cross Ambiguity) 和组合歧义 (Combination Ambiguity)。
(1) 老板有意见他。
(2) 老板对他有意见。
和 (2) 的正确切分是:
(1) 老板/有意/见/他/。
(2) 老板/对/他/有/意见/。
这种属于交叉歧义。abc 三个成分,ab 可以分成一个词,bc 也可以分成一个词。
(3) 其他语言学起来很难。
(4) 语言学是以人类语言为研究对象的学科。
和 (4) 的正确切分是:
(3) 其他/语言/学/起来/很/难/。
(4) 语言学/是/以/人类/语言/为/研究/对象/的/学科/。
这种就是组合歧义。ab 两个成分,组合在一起的时候是一个词,分开以后可以各自成词。
解决分词歧义的技术方法主要有三大类,分别是基于规则的方法,基于统计的方法(例如 CRF、HMM、Deep Learning 等),以及规则和统计结合。网上,也能查到一些相关的分词器实现。
在技术需求方面,有的需要细粒度的分词,有的需要粗粒度的,这都是实际应用会面对的矛盾。这也是由于汉语本身语素、词和短语的界限不明造成的。
臣妾做不到啊。
(5) 中的「做不到」,属于动补结构 (动词+补语),从语言学的角度看,是个短语。实际应用时,可以分成「做/不/到」,也可以「做不到」合在一起,看成一个词。
中文分词也是英文和中文 NLP 的一个基本不同,英文不需要分词,而中文需要进行分词,以便能够更好地进行后续 NLP 任务。当然,目前也有一些中文 NLP 技术,可以避开中文分词任务。
2. 词性标注 (Part-of-speech Tagging, POS)
汉语词性的独特之处在于,汉语作为孤立语/分析语,没有明显的形态变化,与英语等屈折语不同。比如:
(6) 我感觉他喜欢我。(动词)
(7) 我的感觉很准。(名词)
如果用英语说这两句话,应该是:
(8)I feel he loves me. (动词)
(9)My feeling is reliable.(名词)
同样一个「感觉」,其实是同形异义词。我们必须准确识别两种词性。
上面说的这种情况名词和动词的区别是比较明显的。但汉语的复杂之处还不止这个。比如:
(10) 他喜欢你。(动词)
(11) 我很珍惜她的喜欢。(动词用作名词)
「喜欢」从绝大多数情况来看,都被人们看成一个动词,但例 (11) 就把动词当作名词用了,而且没有词形变化。这种情况在汉语里大量存在,这也就是沈家煊先生提出的汉语「名动包含」的观点。
汉语的这一特点会造成句子里的核心谓语动词难以识别的问题。还是拿例 (11) 来说,句子里有两个动词「珍惜」和「喜欢」,但核心谓语动词是「珍惜」。「喜欢」最好不要被判断为动词,否则会影响后续的句法、语义分析。
中科院计算所汉语词性标记集提供了 vn、an 等词性标签,v 代表动词,a 代表形容词,后面加上 n,其实有一种「动名词」「形名词」的意思,也是对英语的一种借鉴。vn 等标签可以帮我们解决掉一些非谓动词干扰的问题,但不能解决全部。
在实际应用中,我们以「依句辨品,离句无品」的原则去做词性标注,关注词在句子里的位置和作用,虽然这未必是黎锦熙先生说这句话时的本意。
3. 句法分析
目前在做的句法分析包括句法树 (Parse Tree) 和依存句法分析 (Dependency Parsing, DP),谈到这两点不得不放出下面这两张图:
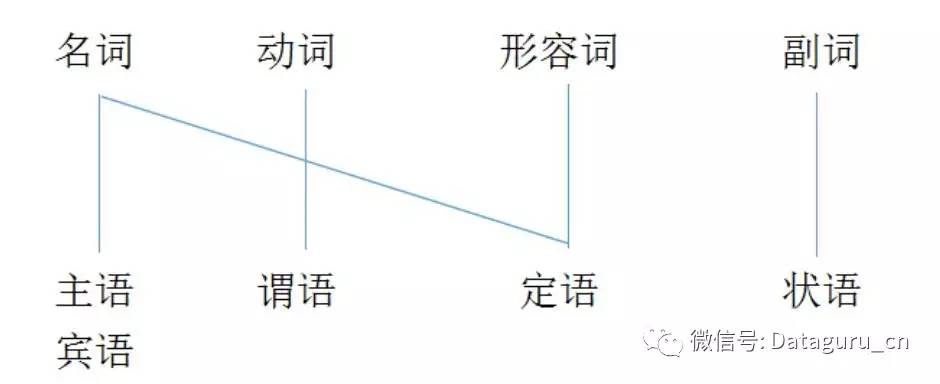
图 (1)
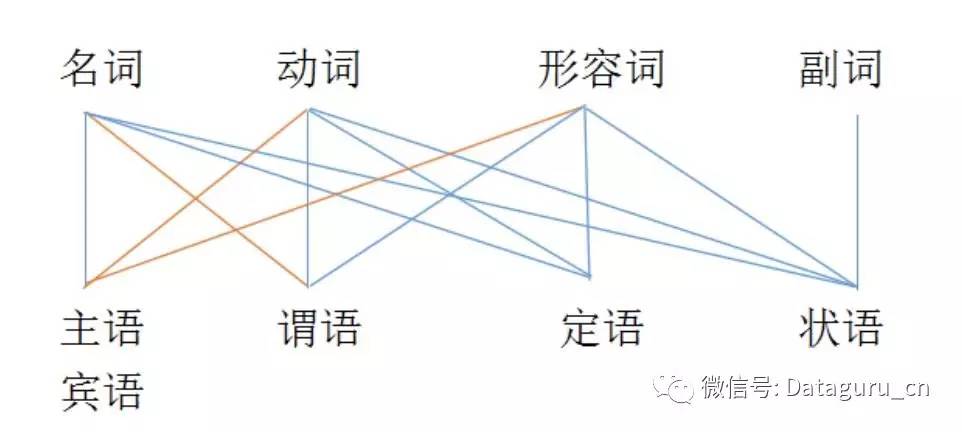
图 (2)
不同的词类在句子中行使的功能是不一样的。图 (1) 基本可以代表英语词类的功能,这张图比较符合我们的一般认识,即名词作主语宾语,动词作谓语,形容词作定语,副词作状语。
但是汉语的情况,如图 (2),要复杂得多。名词也可以作谓语,动词也可以作主宾语。比如:
我永远十八岁。
例 (12) 就是一个典型的名词性短语作谓语的例子,这个句子不需要动词也成立。「我」是代词,「永远」是副词,「十八岁」是数量短语。
句法树分析结果如下:
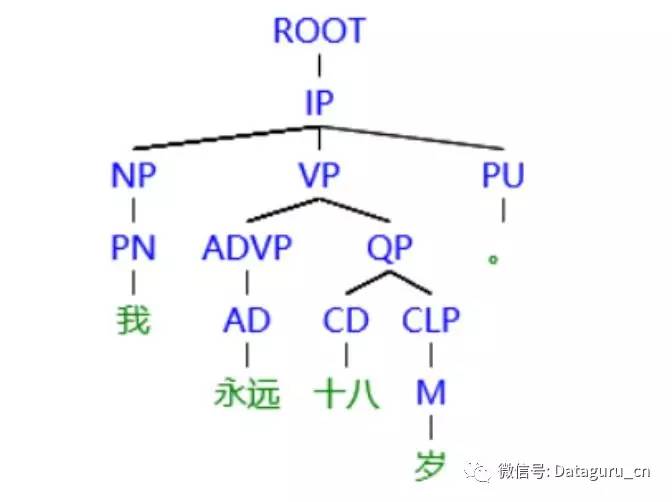
图 (3)
图 (3) 借用 CTB(美国宾州大学的汉语树库)的标注体系,NP 代表名词性短语,VP 代表动词性短语,虽然这句话中没有动词,但仍需要 VP 作为谓语的框架。
依存句法分析结果如下:
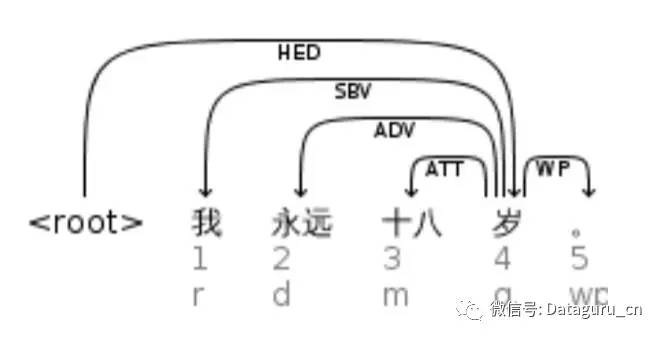
图 (4)
图 (4) 借用 LTP(哈工大社会计算与信息检索研究中心研发的「语言技术平台」)的标注体系,SBV 代表主语,root 是「岁」,即使没有动词,也能正确分析句子结构。
汉语还有一些特殊句型,比如主谓谓语句、存现句、连谓句、兼语句等,在句法分析层面上都有自己独特的结构,也是需要特殊处理的。
4. 其他方面
汉语还有一个特点是重意合而不重形式,句子结构比较松散,多分句;英语则多从句,多引导词,句子结构比较容易判断。如果要判断句子里的因果关系、让步关系、目的关系、假设关系等,目前来说还比较难。况且我们说话的时候,常常会省略「因为」「即使」「如果」等明显的关联词,这也样也就使得特征变得不明显。比如:
(13) 人勤地不懒。
(14) 如果人勤地就不懒。
例 (13) 和 (14) 表达了一样的意思,但它们的表现形式是不一样的。
汉语结构松散还表现为:
(15) 一斤苹果多少钱?
(16) 苹果一斤多少钱?
(17) 多少钱一斤苹果?
例 (15)(16)(17) 都说得通,而且还很常用。
在语义分析层面,如语义角色标注 (Semantic Role Labeling, SRL) 和语义依存分析 (Semantic Dependency Parsing, SDP),汉语这个特点着实加大了实现的难度。
5. 从 NLP 到 NLU,从处理到理解
再来谈谈 NLU,传统的 NLP 基本上都是在做「处理」的工作,是把人类的语言掰开揉碎,而 NLU 则解决更深层的「理解」问题,即如何消化 NLP 已经处理好的东西,真正让机器明白人类语言的语义(semantic)。NLU 的出现也对中文 NLP 起到了重要的补足作用。
NLP 和传统语言学已经可以帮助人工智能解决一部分初级问题,但却还远远不能 cover 千变万化的语言形式,比如机器可以理解「我心情不好」,却难以理解「我的心淅淅沥沥下着小雨」这样的转喻;机器可以理解「我要吃饭」,却难以体会同样是吃饭,「上饭店」和「下馆子」,这一「上」一「下」间表达的心理上的微妙差异。
人机自然语言交互涉及到语法、语义、语用三个层面,越往后越难。为了推动人机自然语言交互的发展,需要在 NLP 的基础上,引入 NLU、认知语言学、心理语言学、社会语言学等学科的综合参与。甚至如竹间智能正在探索的,为了理解「寒暄」、「安抚」甚至是「讽刺」、「幽默」这样的言语修辞行为,需要在深度学习方法中结合对心理学的研究,在语义理解的基础上增加意图识别和情感判断,以弥补传统中文 NLP 在语言理解上的不足,让机器真正读懂人类语言的复杂语义,以及背后的意图和情感。在此基础上给予对话者拟人的反馈,从而达到更好的人机自然语言交互效果。
同样,人工智能也必将改变语言学研究的发展方向。传统的重理论分析而轻实例,坐着想句子的研究方法将逐渐退出舞台;真实语料、口语和书面语并重,侧重对语言形态进行统计分析的研究将大量涌现。另外,传统语言学将进一步向计算语言学靠拢,未来将会有新的、更容易被计算机接受的语法提出。
文章来源:机器之心

《机器读心术之文本挖掘与自然语言处理》即将开课,课程在全国的独有性,以及将艰难知识通俗化讲授的能力,学完将熟悉文本挖掘与自然语言处理技术,懂得怎样运用到自己的实际工作,将数据挖掘能力从有限的结构化数据延伸到非结构化的海量文字材料。点击下方二维码报名课程