NeurIPS 2020 Oral | 基于因果干预的弱监督语义分割
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

论文已上传,文末附下载方式
本文作者:ERLING的铲屎官
https://zhuanlan.zhihu.com/p/260967655
本文已由原作者授权,不得擅自二次转载
本文介绍我们今年被NeurIPS 2020收录的一篇oral文章: Causal Intervention for Weakly-Supervised Semantic Segmentation。

文章和代码的链接如下:
论文:https://arxiv.org/abs/2009.12547
代码:https://github.com/ZHANGDONG-NJUST/CONTA
我们提出的基于因果干预的Context Adjustment (CONTA)模型主要有以下几个优势:
CONTA是第一个使用因果图来分析弱监督语义分割模型中各component之间的关系,从而找出了造成现有的pseudo-mask不准确的本质原因是因为数据集中的上下文先验是混淆因子。在此基础上,我们又进一步提出了使用因果干预切断上下文先验和图像之间的关联,从而提升pseudo-mask的质量。
不同于以往的基于graph neural network或复杂的attention机制的弱监督语义分割模型,CONTA的设计简洁,并没有很复杂的操作和训练步骤在其中。
我们在4种不同的弱监督语义分割模型上都进行了实验,结果表明CONTA可以提升模型CAM、pseuso-mask和segmentation mask的质量,从而验证了CONTA的通用性和有效性。我们相信CONTA在将来也可以被应用到其他的弱监督语义分割模型上。
一、背景简介
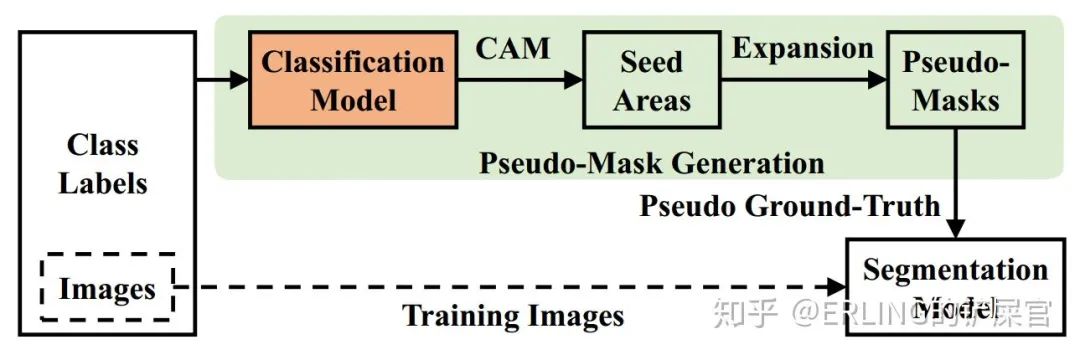
语义分割(Semantic Segmentation)任务需要对输入图像中的每一个像素都进行类别预测。因此想要训练一个全监督的segmentation模型,则首先需要消耗大量的人力、财力对训练图像进行逐像素的标注。为缓解这个问题,人们利用一些较容易获取的弱标签(Weak Label)作为图像的监督信息来训练segmentation模型。比如,常见的弱标签有Bounding Box、Scribble、Point以及Image-level class label。我们的研究内容是基于image-level class label的,其是这些弱标签中是容易获取但也是最难处理的,因为image-level class label本身只提供了图像的类别信息而没有目标在图像中的位置信息。目前流行的基于image-level class label的弱监督segmentation模型主要分为以下三个步骤进行,如图1所示:1)首先通过multi-label image classification模型获取图像的类响应激活图(Class Activation Map)作为种子区域(Seed Area);2)在种子区域的基础上,通过计算像素之间的语义相似性对种子区域进行扩张(Exoansion)得到图像的伪标签(Pseudo-Mask);3)使用伪标签作为Ground-Truth训练一个全监督的语义分割模型,并在训练好的模型上对val/test集合进行预测。
二、伪标签中存在的问题
从以上的介绍中,我们很容易可以看出,获取种子区域,以及对种子区域进行扩张是弱监督语义分割中最重要的两个步骤,其决定了我们得到的pseudo-mask的质量。那么我们能否只使用弱标签而获取和ground-truth完全一致的pasudo-mask ?答案是否定的。因为我们通过image classification模型只能获取目标在分类过程中一部分最具有判别性的区域,比如狗的头、猫的耳朵、车的轮子等。而仅仅通过种子扩张的方法去准确cover到目标的所有区域并不超出目标的边界显然是不可能的。而对于一个具体的object而言,其不完美的pseudo-mask无非就以下两种基本的情况,如图2所示:1)没cover到完整的区域(Incomplete Foreground);2)超出了本身的区域。对于第二种情况我们又将其分为两种具体的case:超出到了其他前景目标区域中(Object Ambiguity),以及超出到了背景区域中(Incomplete Background)。在实际生成的pseudo-mask中,以上的三种情况往往是混合在一起出现的。另外,图2种的“context”是我们把数据集中每个类对应的目标区域使用mask扣出来后求mean的结果,其能反映出来当前类在图像中的一个大概的位置、形状等信息。

三、结构化因果图
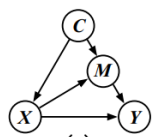
为了解决伪标签中存在的问题,我们首先需要知道的是什么原因产生了这些问题。因果关系作为可以用来分析模型component之间因果效应的工具,被理论和实践验证是有用的,并已经被成功应用在多个计算机视觉任务中。在我们的论文中,我们通过建立结构化因果图(Structural Causal Model)分析弱监督语义分割模型中各个component之间的因果关系,从而发掘导致不完美的pseudo-mask的原因。图3就是我们提出的结构化因果关系图,其中C是数据集的上下文先验,X是输入图像,Y是图像对应的类别标签,M被认为是X在上下文先验C下的一个具体的表示。至于为什么这四个components之间的因果关系可以这么表示,以及各个component之间的具体的关系,大家可以去查看我们的论文 Section 3.1,里面有详细的解释。另外,关于因果关系的一些背景知识,建议大家可以参考[1,2]。
四、因果干预
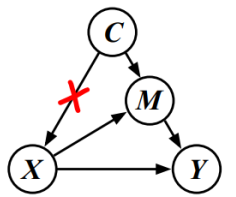
通过以上的结构化因果图,我们可以很清楚的发现,上下文先验C在整个模型中是一个混淆因子,其导致了弱监督语义分割模型在分类的过程中将标签Y和一些存在于X中的和Y无关的像素“虚假关联”了起来。例如,在PASCAL VOC 2012数据集中,只要有“马”出现的时候,那么一般同时都会有“人”的存在,那么分类模型就会把“马”和“人”进行关联,导致马的部分的CAM会落到人所在的像素区域中,可视化的例子大家可以参照图2中的Object Ambiguity。
为了消除这种混淆因子,一个最直接的方法就是我们可以获得这样一个数据集:其中不同种类的目标的各种角度均被放在所有可能的上下文中进行了拍摄,显然这是不可能实现的。退一步讲,即使我们可以这么做,那也是得不偿失的。为了达到相同的目的,我们只能使用因果干预来达到近似的效果。如图4所示,通过切断上下文先验C和图像X之间的关联,使得X能和每一种C都公平地进行结合,从而打破弱监督语义分割模型在分类过程中的X和Y之间的虚假关联,以产生质量更高的CAM用于seed area。
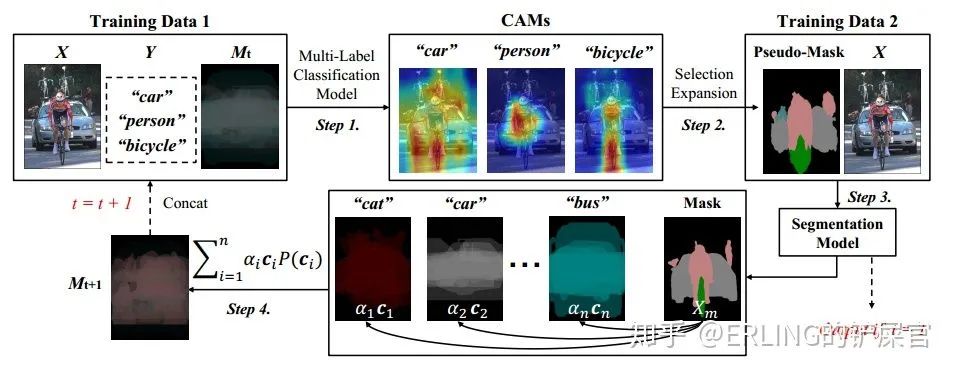
然而在弱监督语义分割的task中,上下文先验C本身是不可知的。我们能拿到的所有的信息只有图像X,图像类别标签Y,以及通过X和Y产生的pseudo-mask。为此,在本文提出的Context Adjustment方法中,我们使用Class-Specific Average Mask来近似构建一个Confounder set,其中Confounder Set中的每一项是通过对每个类的mask进行平均后获得的均值。在已知X和C的情况下,M则可以被表示为C的一种线性组合。如图5所示,包含类别信息“car”,“person”,和“bicycle”的图像X可以被表示为0.12“bird” + 0.13“bottle” + ... + 0.29“person”,其中“bird”,"person"和“bottle”均为数据集中提供的目标类别。

五、实施步骤
以上分析的干预后的因果图,其本质上是一个包含了mask信息的多标签分类模型。那我们如何把这个分类模型再次用到弱监督的分割任务中?由于mask在当前步骤中已经被使用了,所以很容易想到的就是把模型设计为一种循环的模式。如图6,首先,通过初始化弱监督语义分割模型获取图像的mask信息;然后,构建Confounder set并去除confounder。该步骤参考了我们组之前的几个工作[3,4];最后将去除confounder后的mask拼接到下一轮的分类模型的backbone中以产生更高质量的CAM。产生的CAM又可以用来产生更高质量的mask,以此形成一个良性循环(其收敛性可以由EM算法保证)。
六、实验结果
我们在PASCAL VOC 2012和COCO数据集上都进行了实验,在以SEAM [5]和IRNet [6]为baseline的基础上,我们的模型在PASCAL VOC 2012和COCO均取得了当前最好的效果。
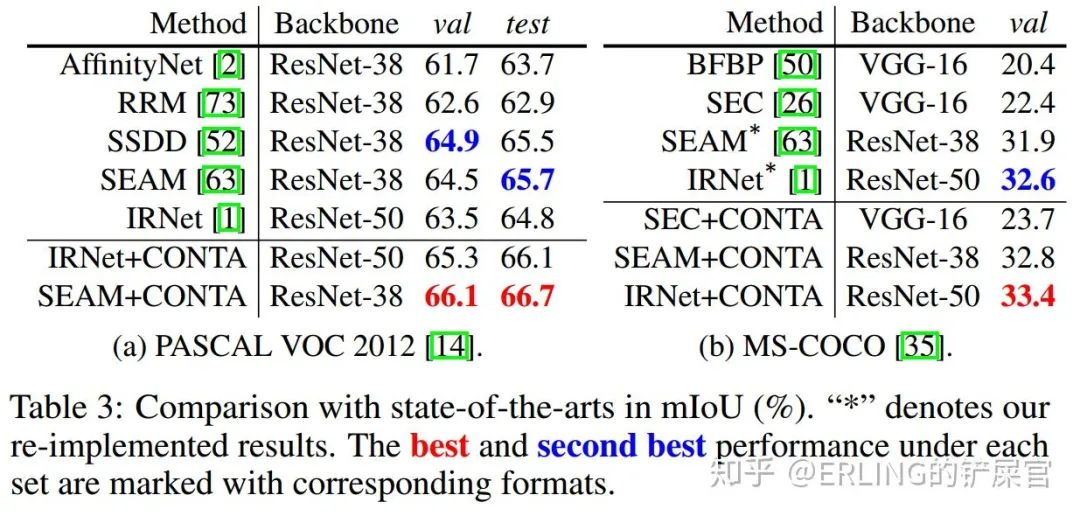
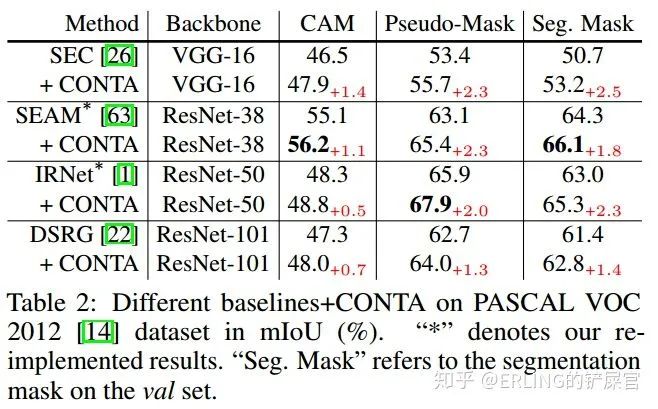
除了在两个SOTA模型上进行实验之外,我们还在SEC和DSRG模型上进行了实验,并report了在training set上的CAM和pseudo-mask的量化结果。实验结果均验证了CONTA的有效性。
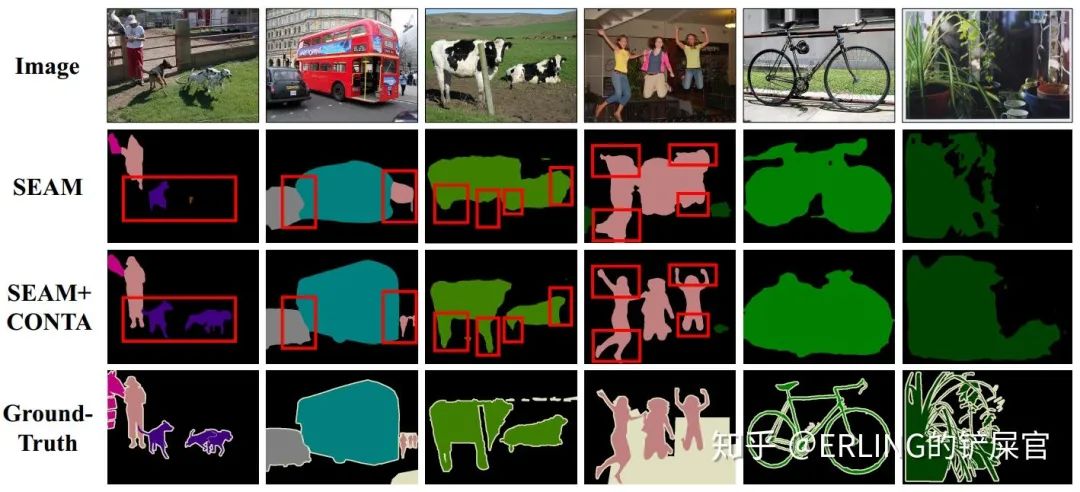
最后,提供一些分割的可视化结果。可以看到在CONTA的帮助下,原本一些错误分割的目标可以被准确的分割,比如“狗”。一些较小和较细的目标的mask也得到了改善,比如“牛腿”和远处的“人”等等。除此之外,我们还可视化两个失败的例子:自行车和植物。造成这种目标分割失败的原因是由于目标本身太细了,而我们的分割模型最后的特征图是8倍下采样的,因此这类目标不能被很好的分割。这些问题可以通过使用一些更细粒度的特征得到解决。
七、小结
以往的弱监督语义分割模型往往都是一锤子买卖,使用pseudo-mask训练好了语义分割模型后就结束了,下游的模型并没有用来反哺上游的模型,但是下游的模型本身却往往包含着自己想要的重要信息。CONTA或许可以给大家提供这样一种思路,不仅仅适用于弱监督的语义分割模型中,怎么样可以使得这种类似的“multi-stage”任务活起来,使用一些自带的信息进行补充后,再用到下一轮的循环中解决存在的问题。
参考
[1] https://zhuanlan.zhihu.com/p/111306353
[3] Xu Yang, Hanwang Zhang, and Jianfei Cai. Deconfounded image captioning: A causal retrospect. In arXiv, 2020.
[4] Jiaxin Qi, Yulei Niu, Jianqiang Huang, and Hanwang Zhang. Two causal principles for improving visual dialog. In CVPR, 2020.
[5] Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In CVPR, 2020.
[6] Jiwoon Ahn, Sunghyun Cho, and Suha Kwak. Weakly supervised learning of instance segmentation with inter-pixel relations. In CVPR, 2019.
论文PDF下载
本文论文PDF已打包好,在CVer公众号后台回复:CONTA,即可下载访问
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已汇集1500人!涵盖语义分割、实例分割、全景分割、医学图像分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!


