【导读】机器学习公平性是现在关注的焦点之一。最近来自Tel-Aviv大学的学者在ACM CSUR最新《机器学习公平性》综述论文阐述七大类公平机器学习算法
![]()
在医疗、交通、教育、大学入学、招生、贷款等领域,人工智能(ai)和机器学习(ML)算法控制人类日常生活的决策正在增加。由于它们现在涉及到我们生活的许多方面,开发不仅准确而且客观和公平的ML算法是至关重要的。最近的研究表明,算法决策可能天生就倾向于不公平,即使没有这样的意图。本文概述了在分类任务上使用ML算法时识别、度量和改进算法公平性的主要概念。本文首先讨论了算法偏见和不公平产生的原因,以及公平的常见定义和衡量标准。公平促进机制然后审查和分为前过程,在过程中,和后过程机制。然后对这些机制进行全面的比较,以便更好地理解在不同的场景中应该使用哪些机制。文章最后回顾了算法公平性的几个新兴研究子领域,不仅仅是分类。
https://dl.acm.org/doi/10.1145/3494672
如今,越来越多的决策由人工智能(AI)和机器学习(ML)算法控制,自动化决策系统在商业和政府应用中的应用越来越多。自动化学习模型的动机很明确——我们希望算法比人类表现得更好,原因有几个。首先,算法可能会整合比人类所能掌握的更多的数据,并考虑更多的因素。第二,算法可以比人类更快地完成复杂的计算。第三,人类的决定是主观的,通常包含偏见。
因此,人们普遍认为,使用自动算法会使决策更客观或更公平。然而,不幸的是,情况并非如此,因为ML算法并不总是像我们期望的那样客观。ML算法无偏差的想法是错误的,因为注入模型的数据是无偏差的假设是错误的。更具体地说,一个预测模型实际上可能具有固有的偏见,因为它学习并保留了历史偏见[125]。
由于许多自动化决策(包括个人将获得工作、贷款、药物、保释或假释)会对人们的生活产生重大影响,因此评估和改善这些自动化系统做出的决策的道德规范非常重要
。
事实上,近年来,对算法公平性的关注已经成为头条新闻。
最常见的例子之一是在刑事司法领域,最近的披露表明,美国刑事司法系统使用的算法错误地预测了非裔美国人未来的犯罪率,其预测率是白人的两倍[6,47]。
在另一个招聘应用的案例中,亚马逊最近发现他们的ML招聘系统歧视女性求职者,尤其是在软件开发和技术岗位上。
一个值得怀疑的原因是,大多数记录在案的历史数据都是男性软件开发人员[54]。
在广告业的另一个不同场景中,谷歌的广告定位算法提出男性比女性获得更高薪水的高管职位[56,187]。
这些证据和对算法公平性的关注使得人们对定义、评估和提高ML算法公平性的文献越来越感兴趣(例如,见[20,48,79,97])。然而,值得注意的是,提高ML算法的公平性的任务并不简单,因为在准确性和公平性之间存在固有的权衡。换句话说,当我们追求更高程度的公平时,我们可能会牺牲准确性(例如,见[125])。本文综述了ML中的公平问题。与该领域最近的其他综述相比[48,79,147],我们的工作提出了一个全面和最新的领域概述,从公平的定义和措施到最先进的公平增强机制。我们的综述还试图涵盖各种措施和机制的利弊,并指导它们应在何种环境下使用。最后,尽管本文的主要部分主要处理分类任务,但本综述的主要目标是突出和讨论分类之外的新兴研究领域,这些研究领域预计将在未来几年得到发展。总的来说,这项综述提供了相关的知识,使新的研究人员进入该领域,告知当前的研究人员快速发展的子领域,并为实践者应用结果提供必要的工具。
本文其余部分的结构如下。
第二节讨论了算法不公平的潜在原因。第三节介绍了公平的定义和衡量标准以及它们的权衡。第四节回顾了公平机制和方法,并对各种机制进行了比较,重点讨论了每种机制的优缺点。第五节介绍了在ML中超越分类的公平性的几个新兴的研究子领域。第六节提供了结束语和概述几个开放的挑战,为未来的研究。
偏差已经包含在用于学习的数据集中,这些数据基于有偏差的设备测量、历史上有偏差的人类决策、错误的报告或其他原因。ML算法本质上就是为了复制这些偏差而设计的。
缺失数据引起的偏差,如缺失值或样本/选择偏差,导致数据集不能代表目标人群。
来自算法目标的偏差,其目的是最小化总体总体的预测误差,因此有利于多数群体而不是少数群体。
敏感属性的“代理”属性导致的偏差。敏感属性区分特权群体和非特权群体,例如种族、性别和年龄,通常不适合在决策中使用。代理属性是可以用来派生敏感属性的非敏感属性。当数据集包含代理属性时,ML算法可以在使用假定合法属性[15]的掩护下,基于敏感属性进行隐式决策。
![]()
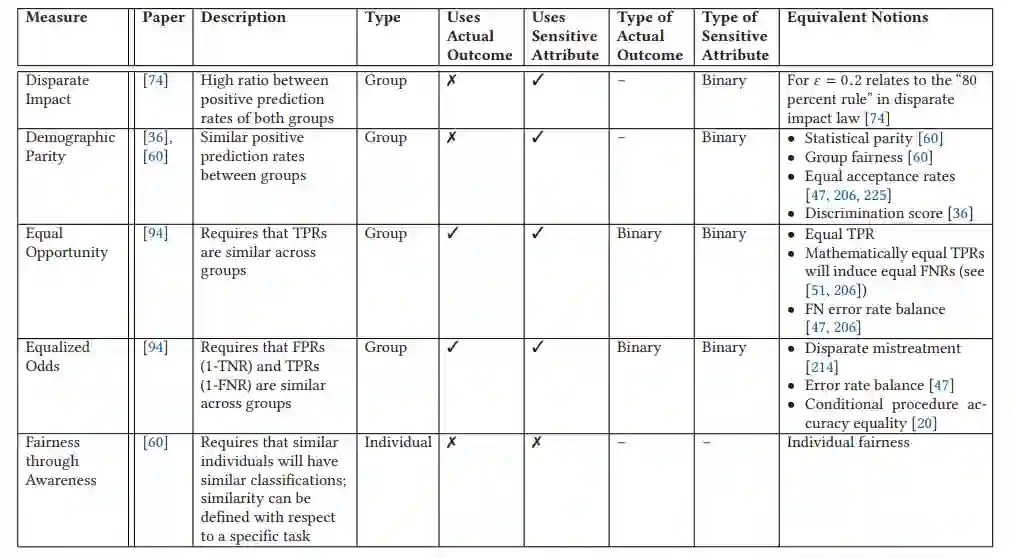
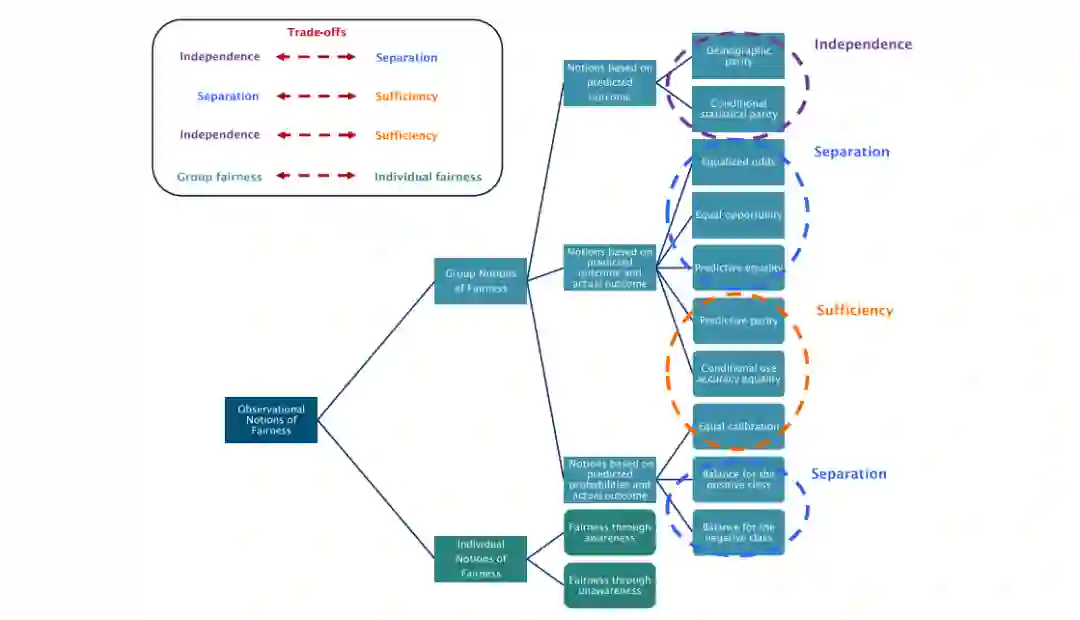
算法公平的度量和定义
现有的算法公平性研究大多考虑批量分类,其中完整的数据可以提前获得。然而,许多学习设置具有动态性质,数据是随时间收集的。与批量学习不同,在这些设置中,系统包括反馈循环,因此每一步的决策都可能影响未来的状态和决策。这也适用于公平决策,因为它们现在应该在每个步骤中考虑,其中短期的公平决策可能会影响长期的公平结果,这一设置通常被称为顺序学习。在这种情况下,有必要平衡利用现有知识(例如,雇佣一个已知的人群)和探索次优解决方案来收集更多的数据(例如,雇佣不同背景的人群,与当前员工不同)。
今天,公平对抗学习在公平分类和公平表征的生成方面越来越受到关注。在一起令人痛心的事件中,一款面部修改应用被曝光为种族主义应用,因为该应用的“图像滤镜”旨在将面部图像变得更“有吸引力”,却让皮肤变得更白[167]。
单词嵌入模型构建单词的表示,并将它们映射到向量(通常也称为word2vec模型)。单词嵌入的训练是使用带有大量文本文档的原始文本数据进行的,并且是基于出现在相同上下文中的单词往往具有相似含义的假设。这些模型的设计主要是为了使嵌入的向量能够指示单词之间的含义和关系(即,含义相似的单词在向量空间中具有接近的向量)。因此,它们被广泛应用于许多自然语言处理应用程序,如搜索引擎、机器翻译、简历过滤、工作推荐系统、在线评论等。
由于CV模型在多个任务中产生了的偏倚结果,CV公平性的研究最近得到了广泛的关注。例如,Buolamwini和Gebru[33]发现,由于数据集中女性深肤色面孔的代表性不足,面部分析模型对判别结果产生了负面影响。Kay等人[117]发现,谷歌引擎中对职业的图像搜索会导致性别偏见的结果。谷歌的标签申请鲁莽地将美国黑人认定为“大猩猩”[160,188]。此外,一款根据照片对个人吸引力进行分类的应用被证明对黑皮肤有歧视[144]。
推荐系统在许多自动化和在线系统中都很普遍,其设计目的是分析用户的数据,为他们提供符合每个用户口味和兴趣的个性化建议。推荐的一个固有概念是,对一个用户来说最好的项目可能与对另一个用户来说不同。推荐项目的例子有电影、新闻文章、产品、工作和贷款等。这些系统具有促进提供者和消费者活动的潜力;然而,他们也被发现表现出公平性问题[34,35,67,68]。例如,谷歌的广告定位算法表明,男性比女性更容易获得高薪的高管职位[56,187]。
从真实世界系统中收集的观测数据大多可以提供关联和相关性,而不是因果结构理解。相反,因果学习依赖于作为因果模型构建的额外知识。仅基于可观测数据的测量方法的一个局限性是,它们没有考虑数据产生的机制,因此可能会产生错误的解释[143]。此外,如第3节所述,公平概念存在着不兼容性的挑战。观测方法的另一个局限性是,如4.4节所述,它们可能会受到缺失数据的严重影响。。
Dwork等人[60]对隐私与公平的关系进行了讨论。我们注意到算法公平性研究与隐私研究密切相关,因为通过混淆敏感信息可以增强公平性和隐私,而对手的目标是最小化数据失真[65,118]。此外,侵犯隐私(例如,推理隐私[53,64,82])可能导致不公平,因为对手有能力推断个人的敏感信息,并以一种有区别的方式使用这些信息。
![]()
参考文献
[1] Himan Abdollahpouri, Gediminas Adomavicius, Robin Burke, Ido Guy, Dietmar Jannach, Toshihiro Kamishima, Jan Krasnodebski, and Luiz Pizzato. 2019. Beyond personalization: Research directions in multistakeholder recommendation. arXiv preprint arXiv:1905.01986 (2019).
[2] Himan Abdollahpouri, Gediminas Adomavicius, Robin Burke, Ido Guy, Dietmar Jannach, Toshihiro Kamishima, Jan Krasnodebski, and Luiz Pizzato. 2020. Multistakeholder recommendation: Survey and research directions. User Modeling and User-Adapted Interaction 30 (2020), 127–158.
[3] Adel Abusitta, Esma Aïmeur, and Omar Abdel Wahab. 2019. Generative adversarial networks for mitigating biases in machine learning systems. arXiv preprint arXiv:1905.09972 (2019).
[4] Alekh Agarwal, Alina Beygelzimer, Miroslav Dudik, John Langford, and Hanna Wallach. 2018. A reductions approach to fair classification. In Proceedings of the International Conference on Machine Learning. 60–69.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~
![]()
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取70000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取70000+AI主题知识资源