重磅!百度飞桨产业级PaddleCV最新全景图来了
导读:PaddleCV是飞桨开源的产业级CV工具与预训练模型集,提供了依托于百度实际产品打磨,能够极大地方便 CV 研究者和工程师快速应用。使用者可以使用PaddleCV 快速实现图像分类、目标检测、图像分割、视频分类和动作定位、图像生成、度量学习、场景文字识别和关键点检测8大类任务,并且可以直接使用百度开源工业级预训练模型进行快速应用于工业、农业、医疗、零售、媒体、驾驶等领域。用户在极大地减少研究和开发成本的同时,也可以获得更好的基于产业实践的应用效果。
一张图了解PaddleCV!
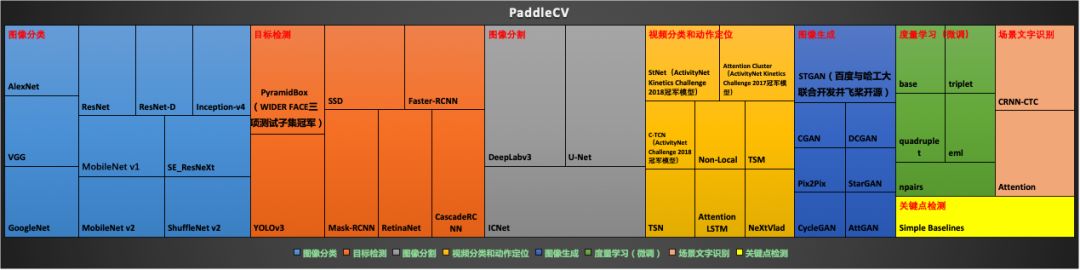
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV
PaddleCV全解读
1. 图像分类
图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉中重要的基础问题,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层视觉任务的基础,在许多领域都有着广泛的应用。如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
在深度学习时代,图像分类的准确率大幅度提升,在图像分类任务中,我们向大家介绍了如何在经典的数据集ImageNet上,训练常用的模型,包括AlexNet、VGG、GoogLeNet、ResNet、Inception-v4、MobileNet、SE-ResNeXt、ShuffleNet模型,也开源了预训练的模型方便用户下载使用。
经典的分类模型架构图:
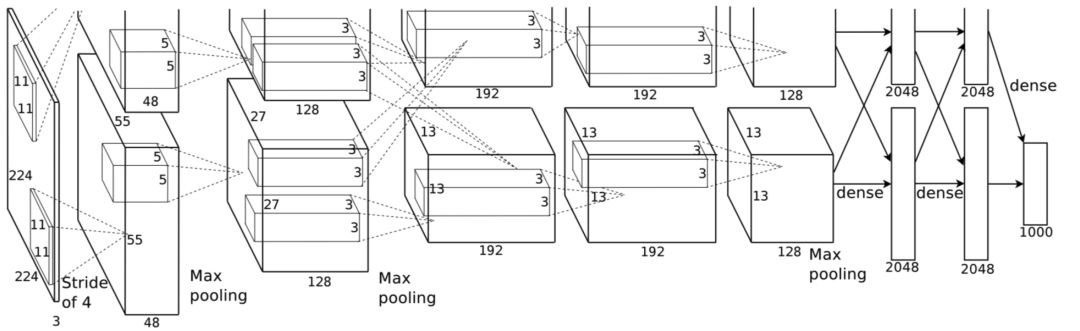
AlexNet结构图
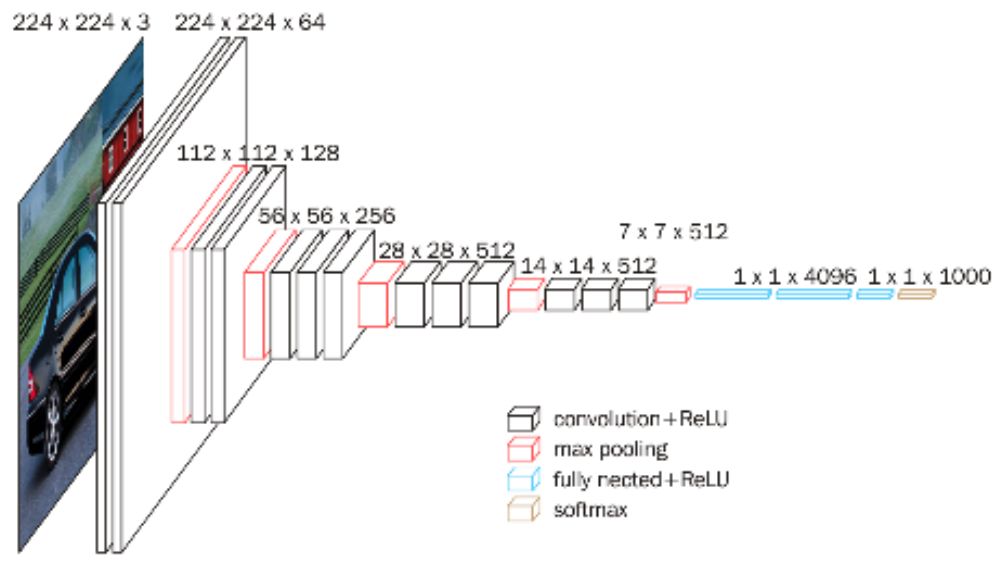
VGG系列结构图
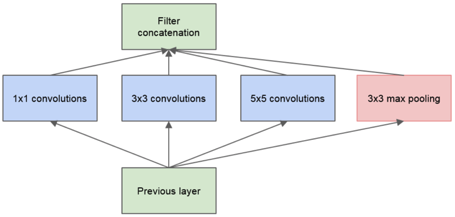
GoogleNet结构图
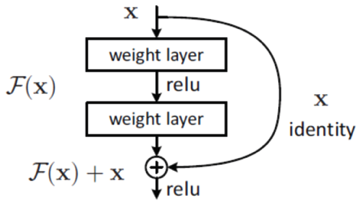
ResNet系列结构图
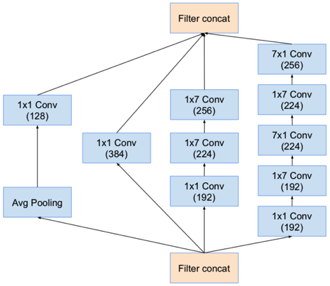
Inception-v4结构图
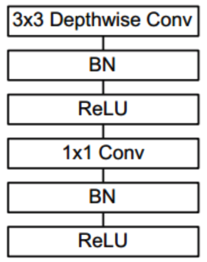
MobileNet核心结构图
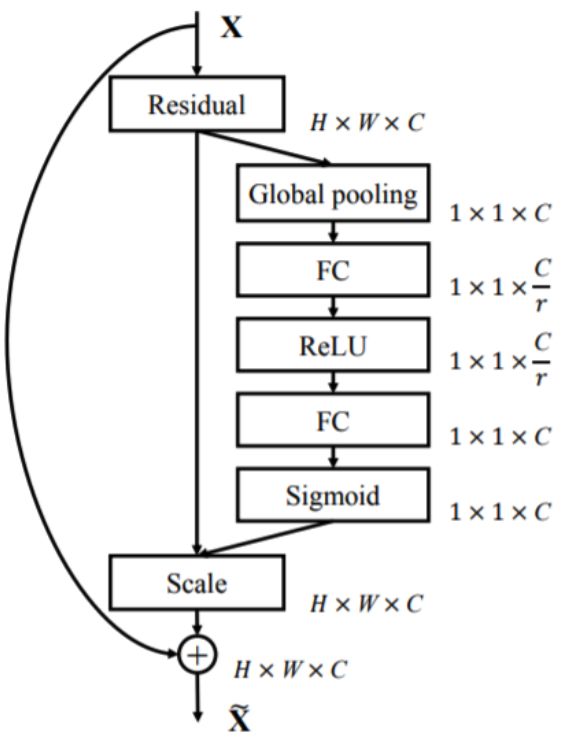
SE-ResNeXt系列核心结构图
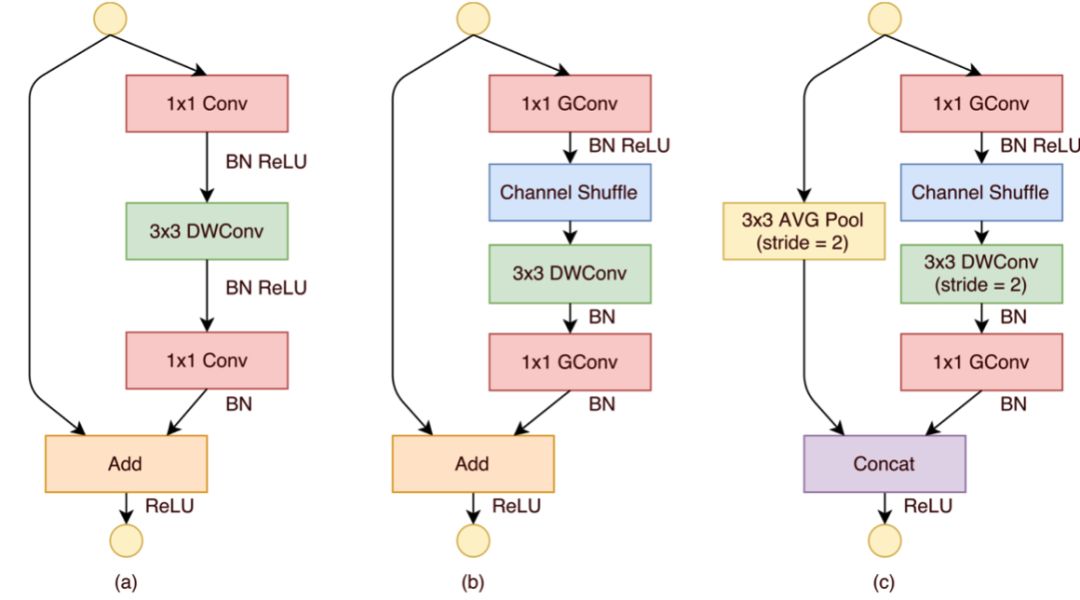
ShuffleNet系列结构图
性能评测(在ImageNet-2012验证集合上的top-1/top-5精度):
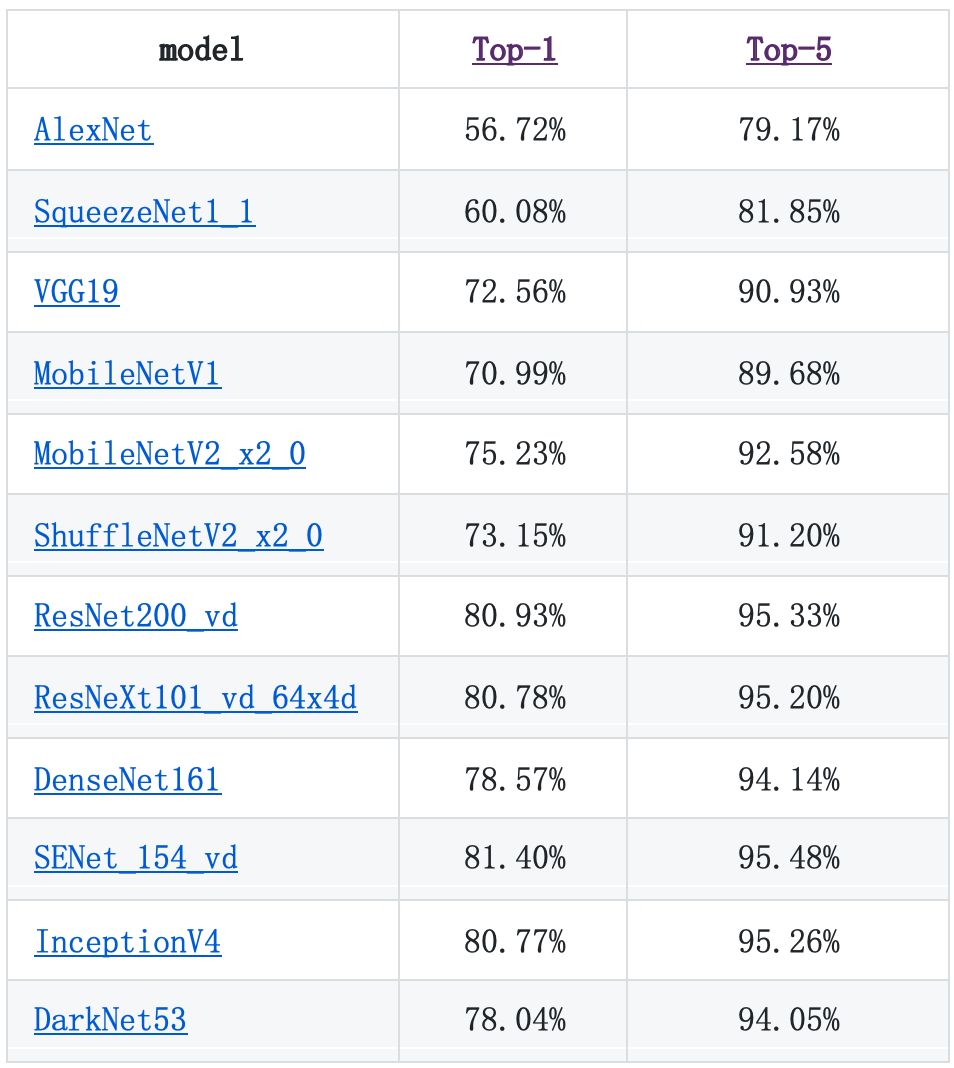
图像分类系列模型评估结果
传送门 :https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/image_classification
2. 目标检测
目标检测任务的目标是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别。对于人类来说,目标检测是一个非常简单的任务。然而,计算机能够“看到”的是图像被编码之后的数字,很难解图像或是视频帧中出现了人或是物体这样的高层语义概念,也就更加难以定位目标出现在图像中哪个区域。与此同时,由于目标会出现在图像或是视频帧中的任何位置,目标的形态千变万化,图像或是视频帧的背景千差万别,诸多因素都使得目标检测对计算机来说是一个具有挑战性的问题。
在目标检测任务中,经典的模型包括SSD、PyramidBox、Faster RCNN、MaskRCNN等。
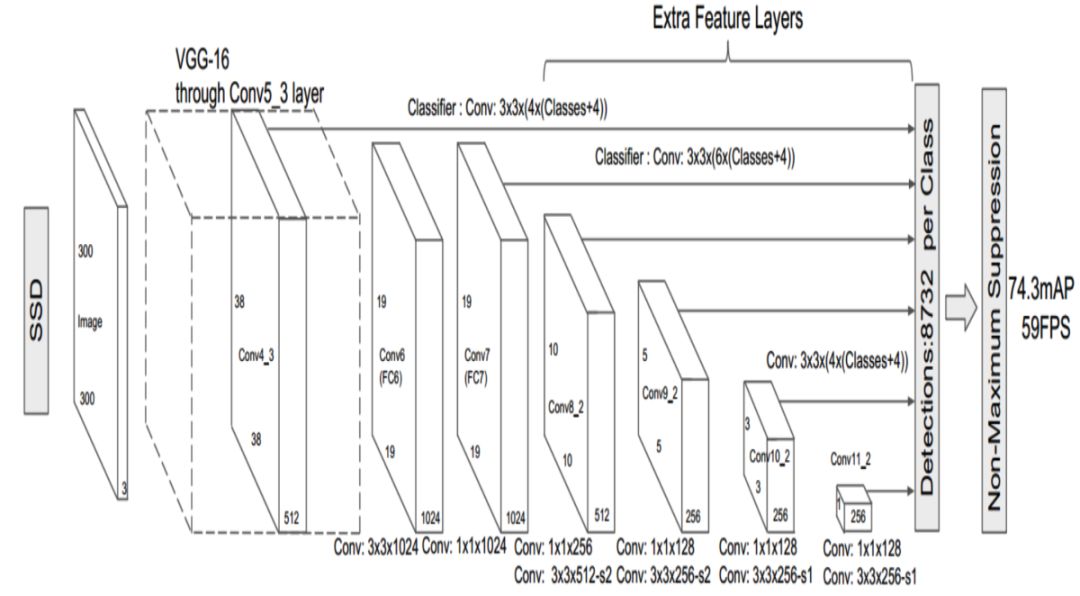
SSD目标检测模型结构
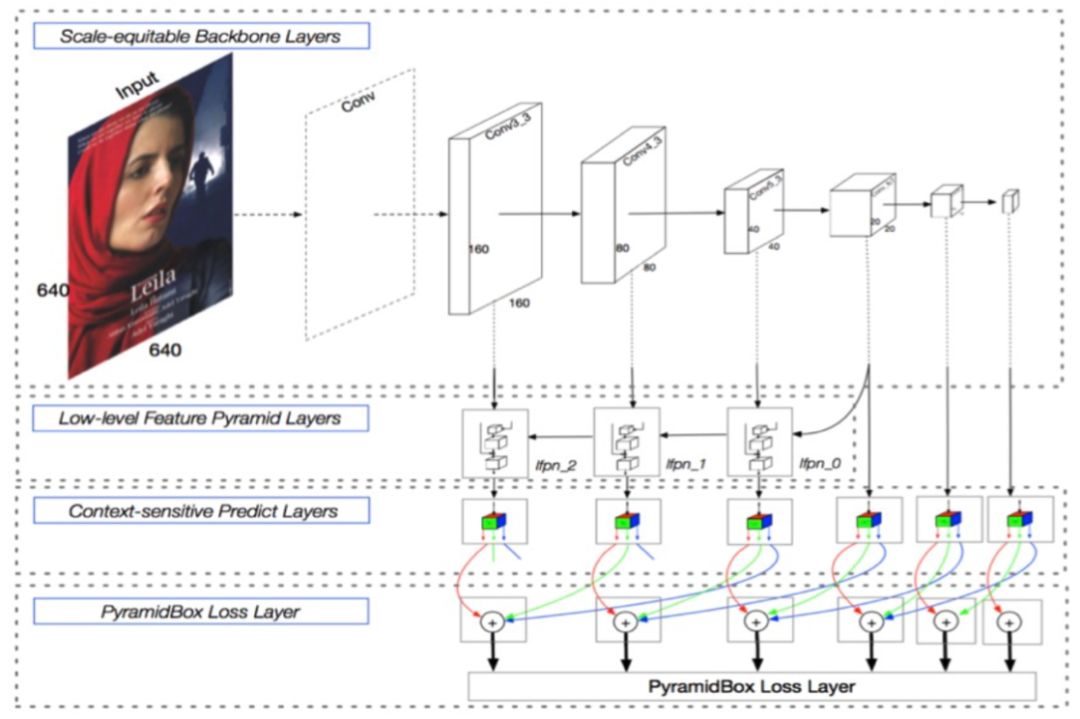
Pyramidbox 人脸检测模型
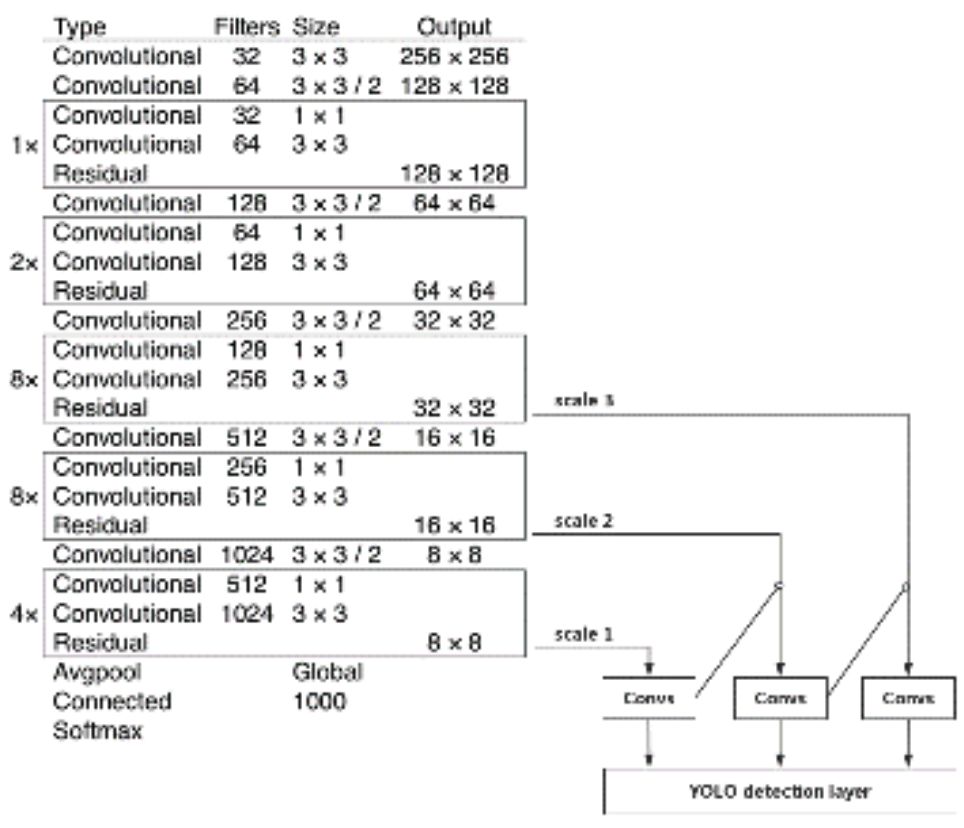
YOLOv3 结构
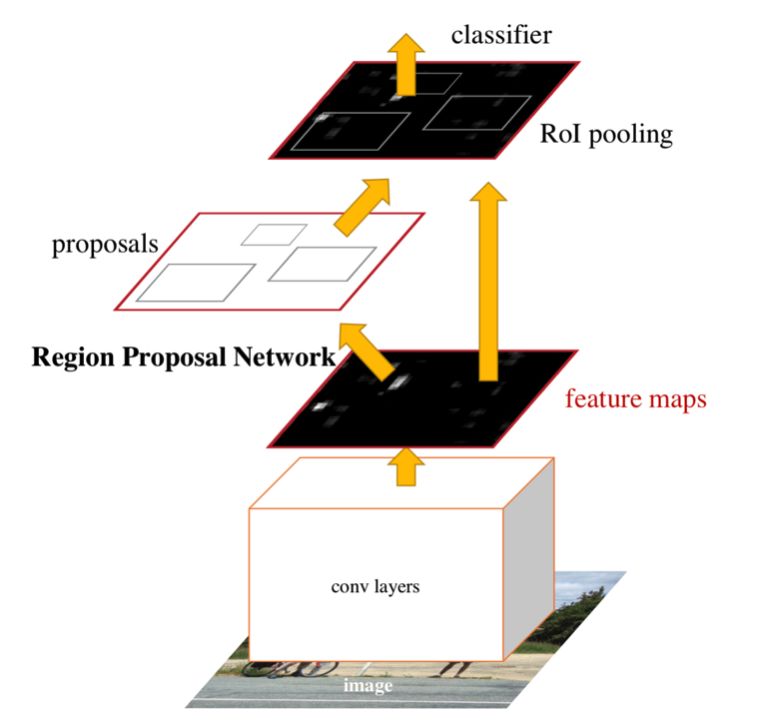
Faster RCNN 结构
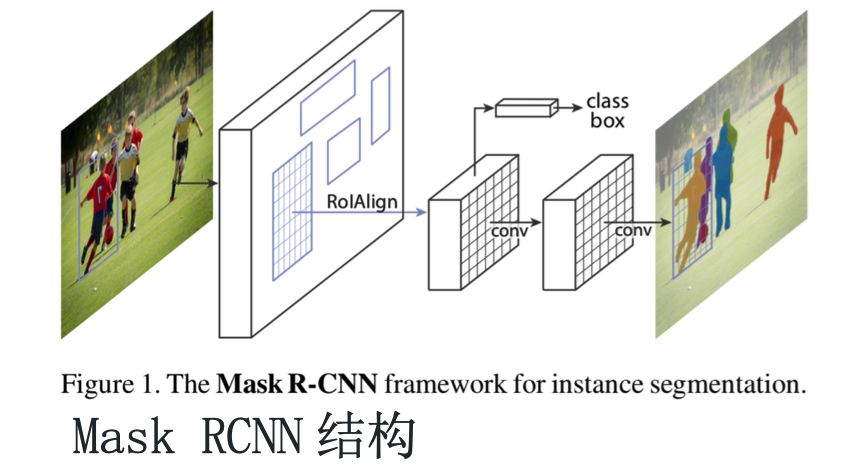
Mask RCNN结构
性能评测

传送门:
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/PaddleDetection
3. 图像语义分割
图像语意分割顾名思义是将图像像素按照表达的语义含义的不同进行分组/分割,图像语义是指对图像内容的理解,例如,能够描绘出什么物体在哪里做了什么事情等,分割是指对图片中的每个像素点进行标注,标注属于哪一类别。近年来用在无人车驾驶技术中分割街景来避让行人和车辆、医疗影像分析中辅助诊断等。分割任务主要分为实例分割和语义分割,实例分割是物体检测加上语义分割的综合体,上文介绍的MaskRCNN是实例分割的经典网络结构之一。在图像语义分割任务中,我们介绍了兼顾准确率和速度的ICNet,DeepLab中最新、执行效果最好的DeepLab v3+。
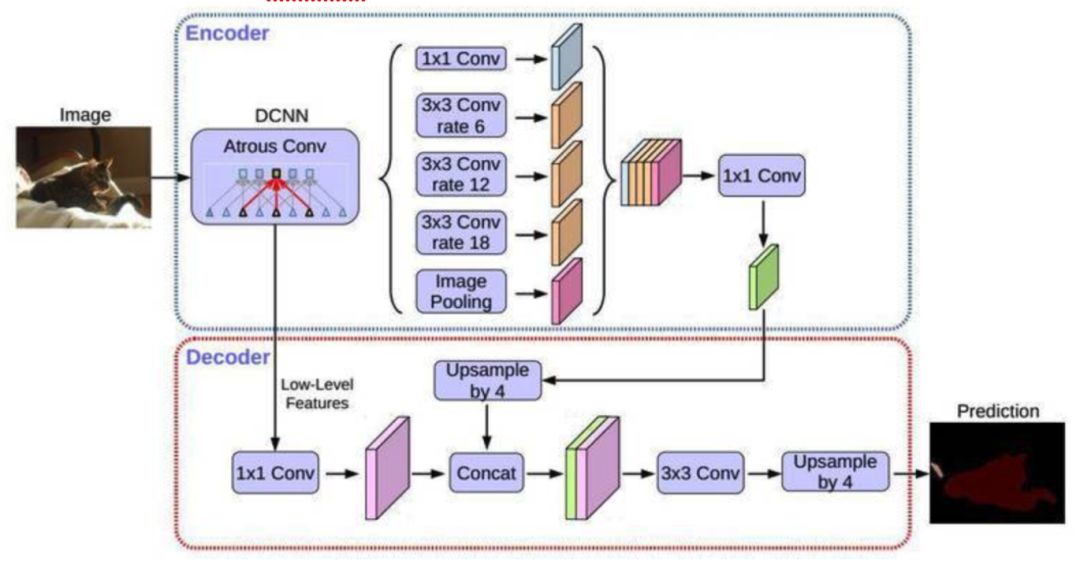
DeepLabv3+基本结构
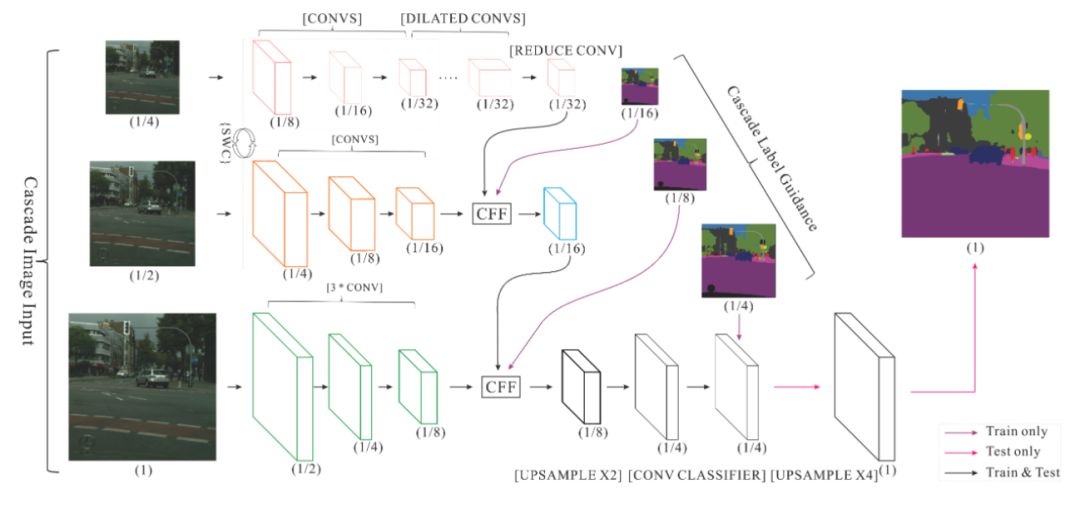
ICNet网络结构
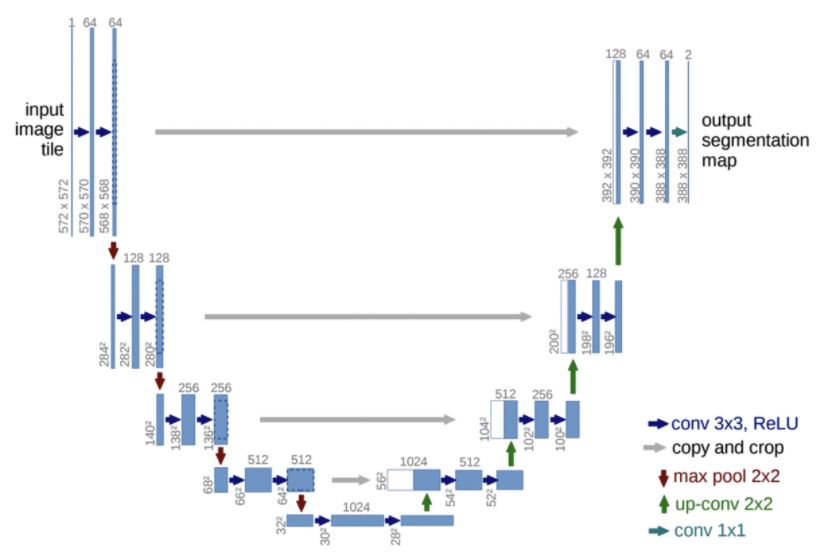
U-Net基本结构
性能评测


传送门:
https://github.com/PaddlePaddle/PaddleSeg
4. 视频分类
视频分类是视频理解任务的基础,与图像分类不同的是,分类的对象不再是静止的图像,而是一个由多帧图像构成的、包含语音数据、包含运动信息等的视频对象,因此理解视频需要获得更多的上下文信息,不仅要理解每帧图像是什么、包含什么,还需要结合不同帧,知道上下文的关联信息。视频分类方法主要包含基于卷积神经网络、基于循环神经网络、或将这两者结合的方法。
在视频分类任务中,我们介绍视频分类方向的多个主流领先模型,其中Attention LSTM,Attention Cluster和NeXtVLAD是比较流行的特征序列模型,TSN和StNet是两个End-to-End的视频分类模型。Attention LSTM模型速度快精度高,NeXtVLAD是2nd-Youtube-8M比赛中最好的单模型, TSN是基于2D-CNN的经典解决方案。Attention Cluster和StNet是百度自研模型,分别发表于CVPR2018和AAAI2019,是Kinetics600比赛第一名中使用到的模型。
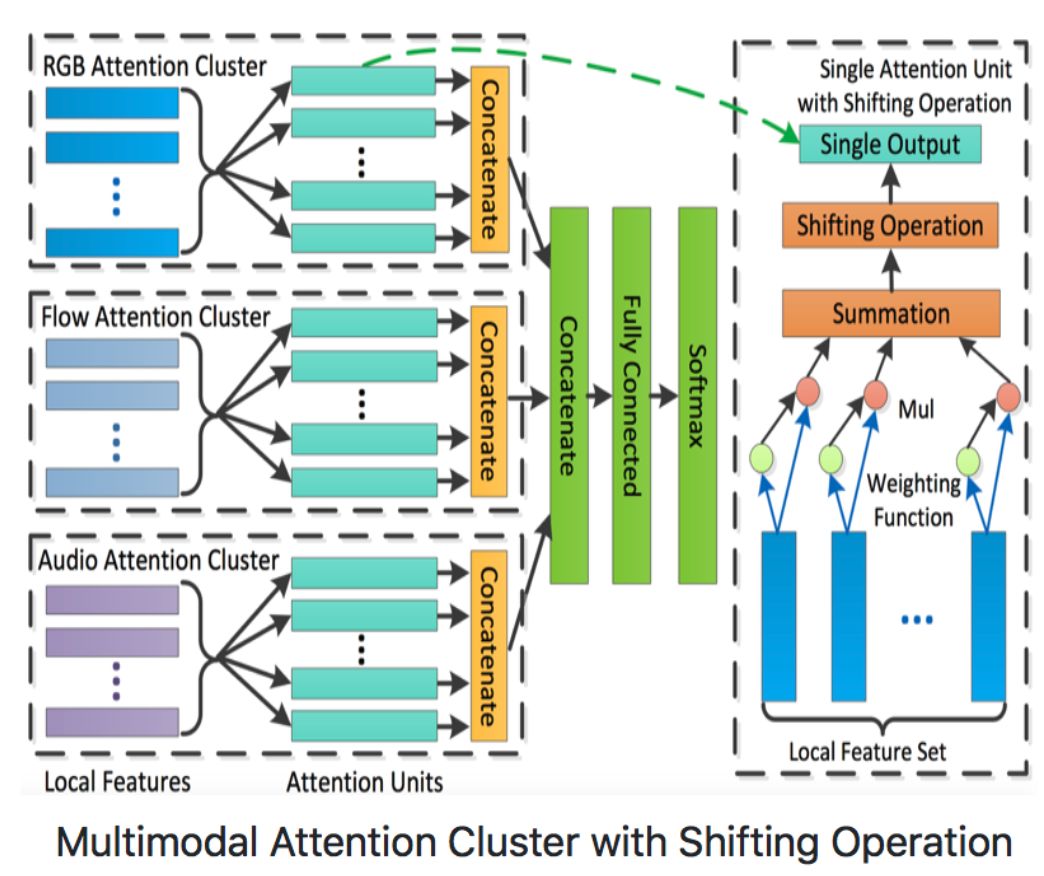
AttentionCluster模型结构
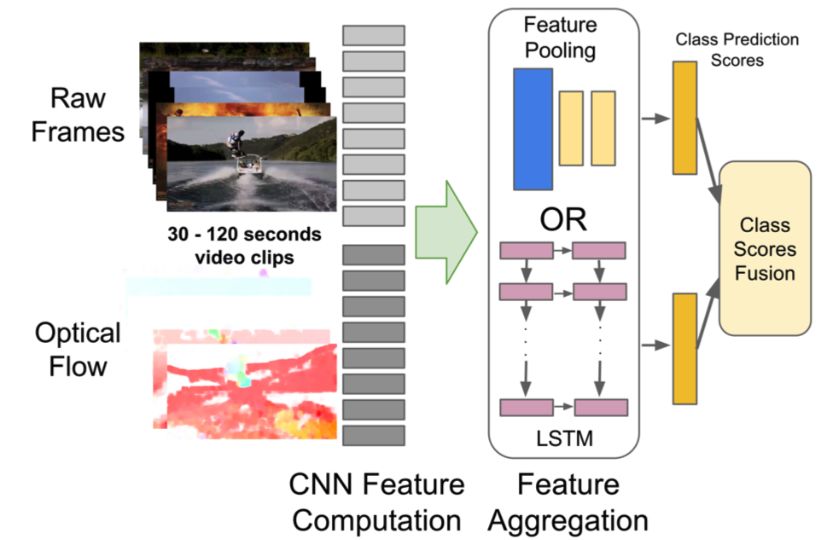
Attention LSTM模型结构
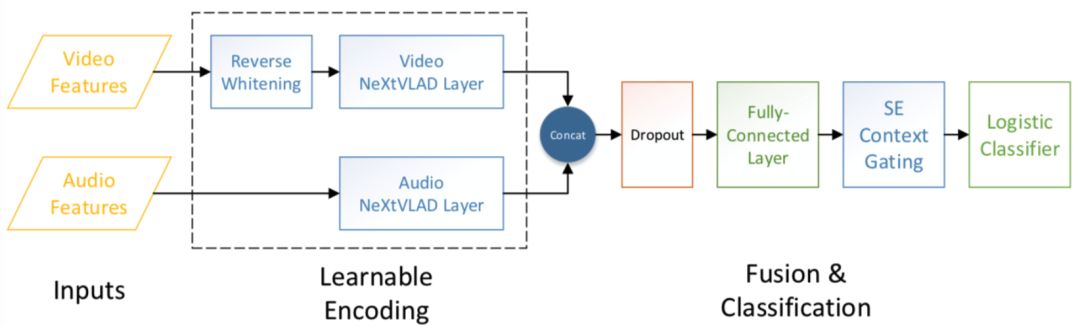
NeXtVLAD模型结构
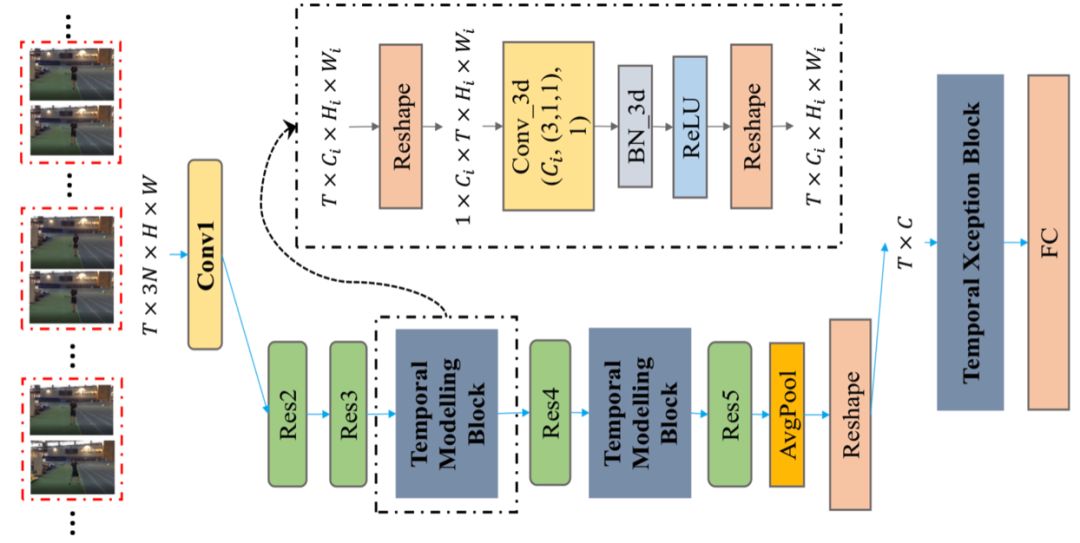
StNet模型结构
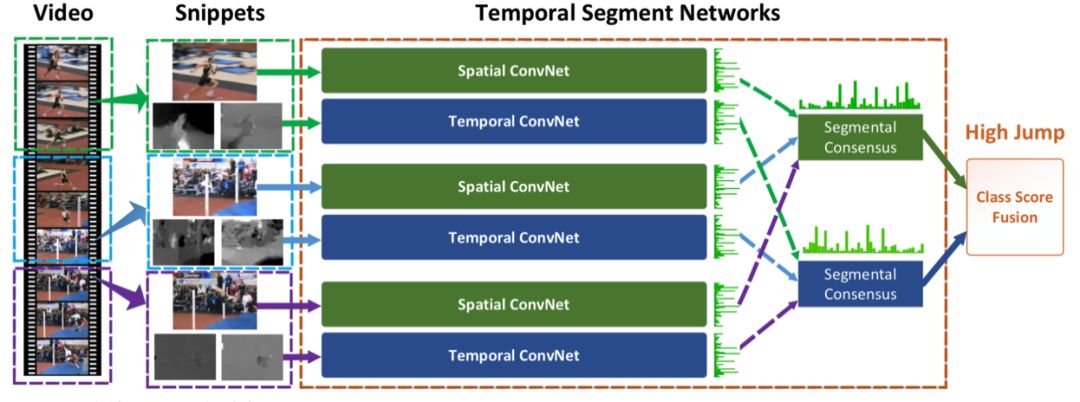
TSN模型结构
性能评测
基于Youtube-8M数据集的视频分类模型评估结果
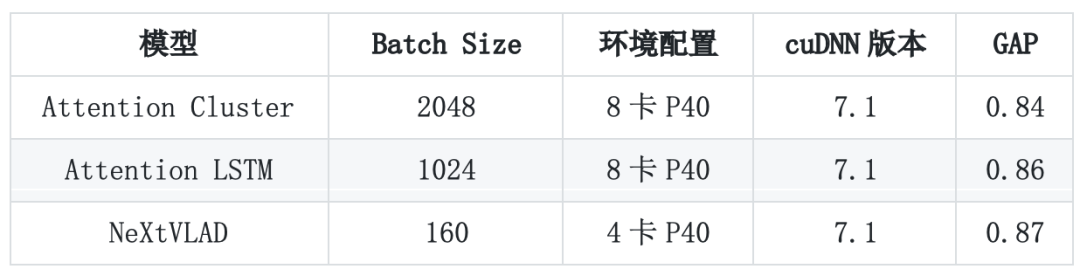
基于Kinetics数据集的视频分类模型 评估结果
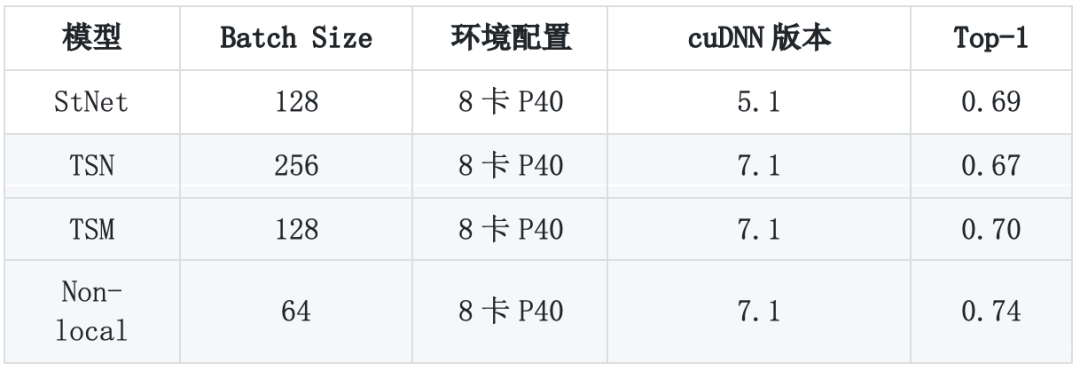
基于ActivityNet的动作定位模型:

传送门:
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/PaddleVideo
5. 图像生成
图像生成是指根据输入向量,生成目标图像。这里的输入向量可以是随机的噪声或用户指定的条件向量。具体的应用场景有:手写体生成、人脸合成、风格迁移、图像修复、超分重建等。当前的图像生成任务主要是借助生成对抗网络(GAN)来实现。生成对抗网络(GAN)由两种子网络组成:生成器和识别器。生成器的输入是随机噪声或条件向量,输出是目标图像。识别器是一个分类器,输入是一张图像,输出是该图像是否是真实的图像。在训练过程中,生成器和识别器通过不断的相互博弈提升自己的能力。
在图像生成任务中,我们介绍了如何使用DCGAN和ConditioanlGAN来进行手写数字的生成,另外还介绍了用于风格迁移的CycleGAN。
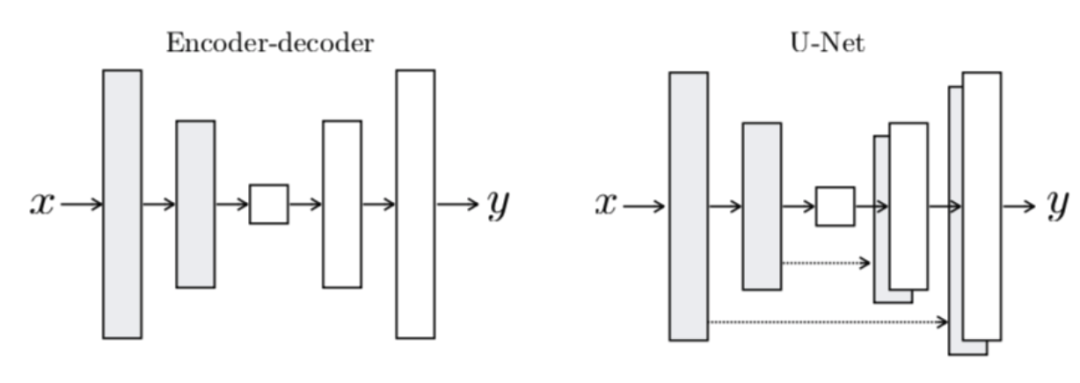
Pix2Pix生成网络结构图
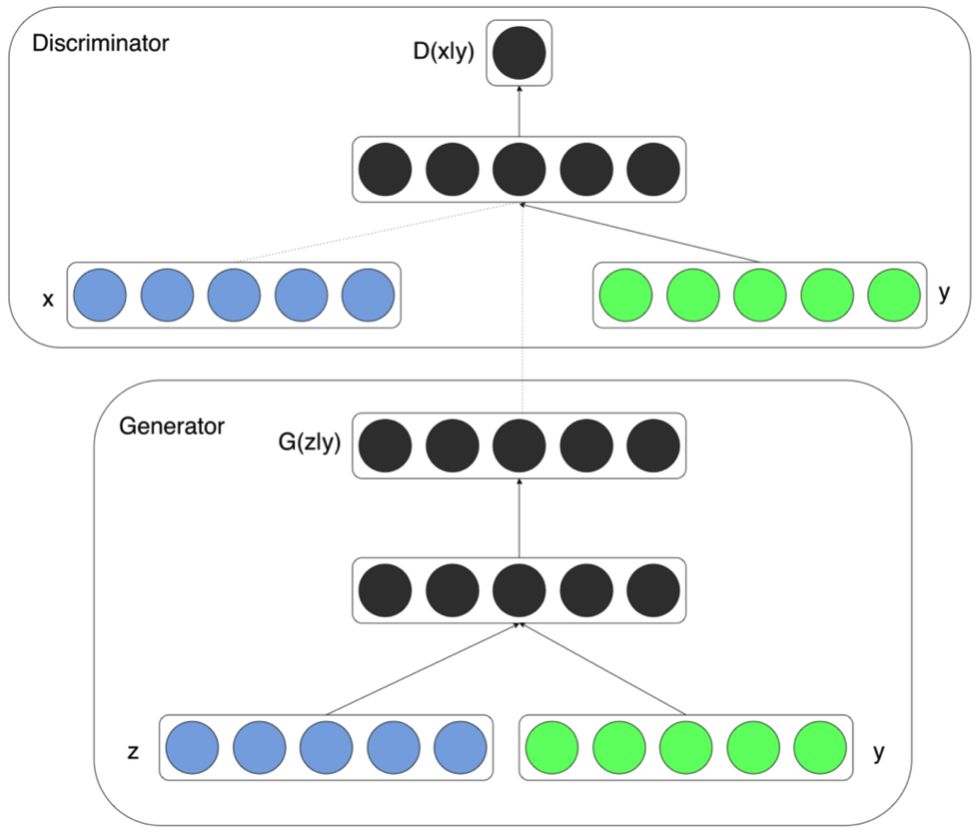
ConditioanlGAN结构
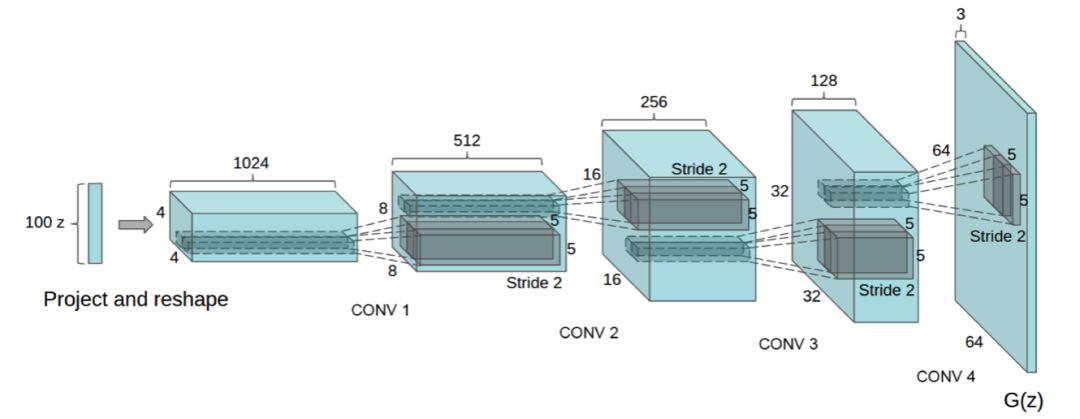
DCGAN结构
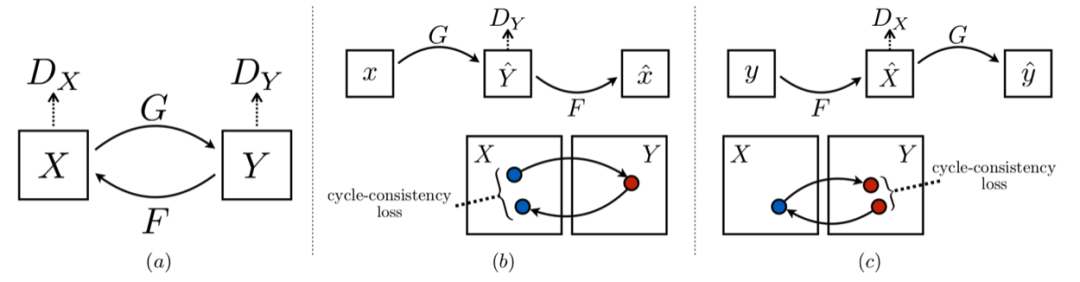
CycleGAN 结构

AttGAN的网络结构


StarGAN的生成网络结构[上]和判别网络结构[下]
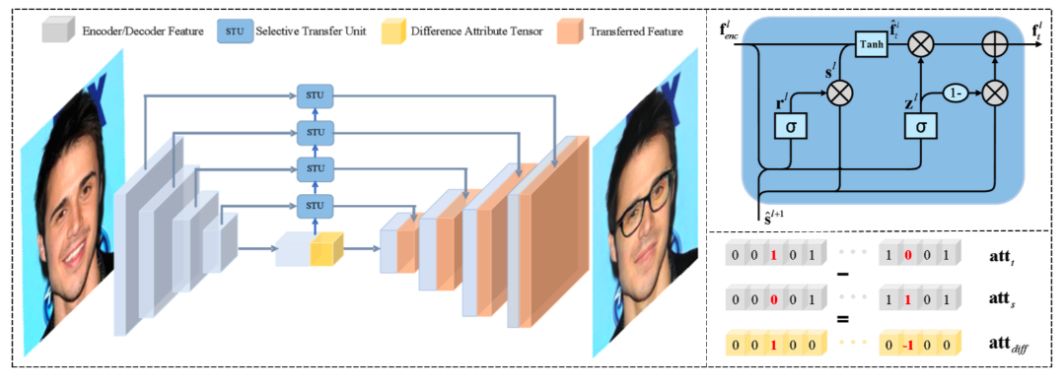
STGAN的网络结构
传送门:
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/PaddleGAN
6. 度量学习
度量学习也称作距离度量学习、相似度学习,通过学习对象之间的距离,度量学习能够用于分析对象时间的关联、比较关系,在实际问题中应用较为广泛,可应用于辅助分类、聚类问题,也广泛用于图像检索、人脸识别等领域。以往,针对不同的任务,需要选择合适的特征并手动构建距离函数,而度量学习可根据不同的任务来自主学习出针对特定任务的度量距离函数。度量学习和深度学习的结合,在人脸识别/验证、行人再识别(human Re-ID)、图像检索等领域均取得较好的性能,在这个任务中我们主要介绍了基于Fluid的深度度量学习模型,包含了三元组、四元组等损失函数。
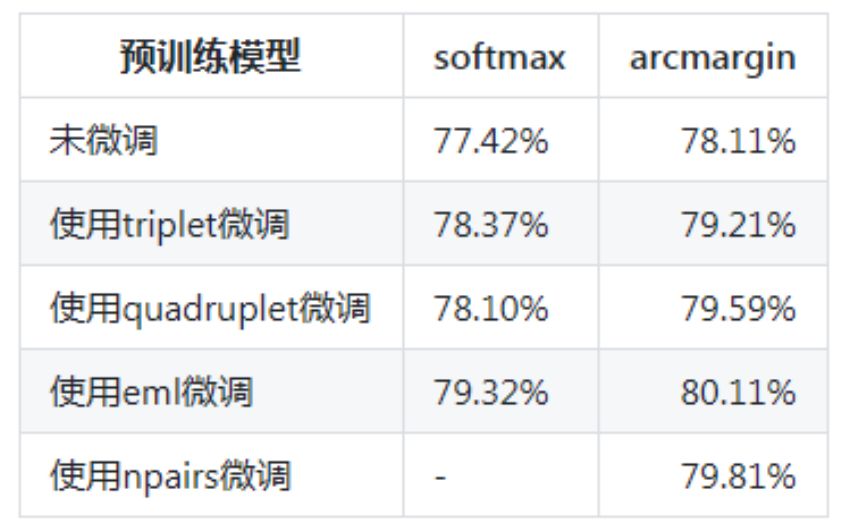
传送门 :https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/metric_learning
7. 场景文字识别
许多场景图像中包含着丰富的文本信息,对理解图像信息有着重要作用,能够极大地帮助人们认知和理解场景图像的内容。场景文字识别是在图像背景复杂、分辨率低下、字体多样、分布随意等情况下,将图像信息转化为文字序列的过程,可认为是一种特别的翻译过程:将图像输入翻译为自然语言输出。场景图像文字识别技术的发展也促进了一些新型应用的产生,如通过自动识别路牌中的文字帮助街景应用获取更加准确的地址信息等。
在场景文字识别任务中,我们介绍如何将基于CNN的图像特征提取和基于RNN的序列翻译技术结合,免除人工定义特征,避免字符分割,使用自动学习到的图像特征,完成字符识别。当前,介绍了CRNN-CTC模型和基于注意力机制的序列到序列模型。
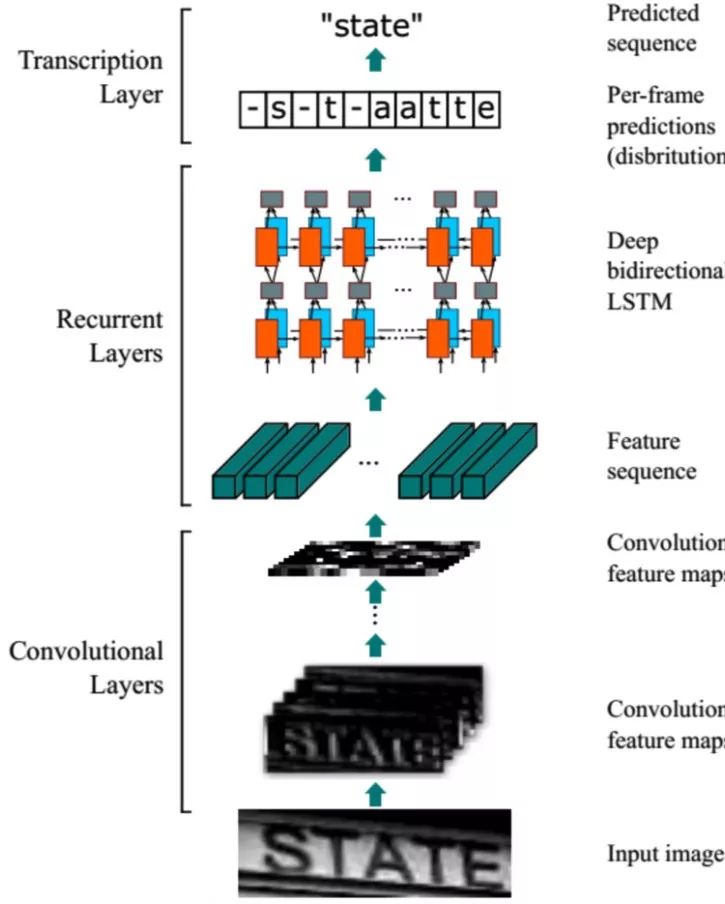
CRNN-CTC模型结构
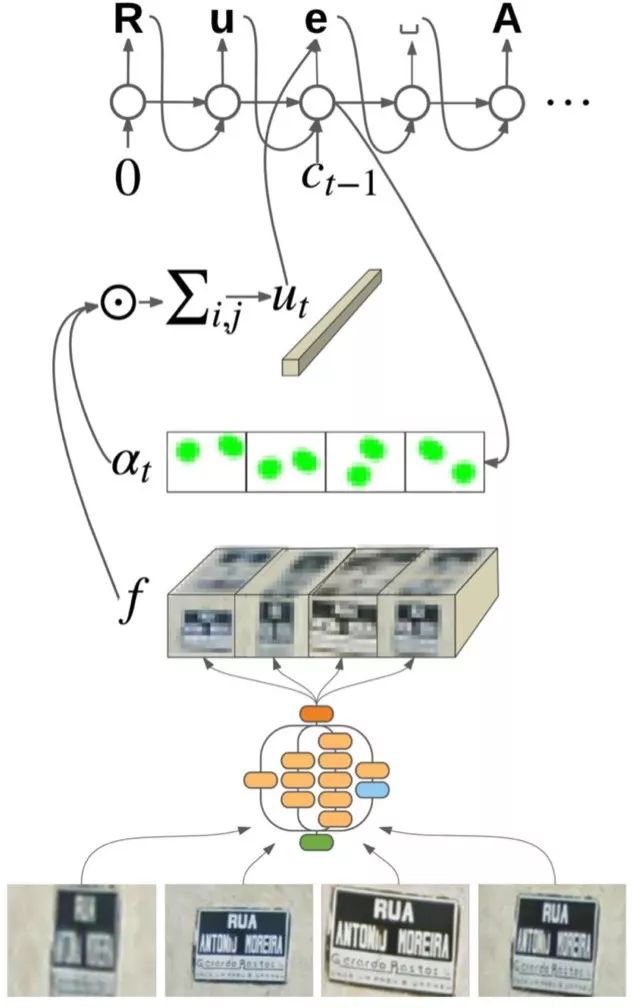
基于注意力机制的序列到序列模型结构:

OCR模型评估结果
传送门 :https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/ocr_recognition
8. 人体关键点检测
人体关键点检测,通过人体关键节点的组合和追踪来识别人的运动和行为,对于描述人体姿态,预测人体行为至关重要,是诸多计算机视觉任务的基础,例如动作分类,异常行为检测,以及自动驾驶等等,也为游戏、视频等提供新的交互方式。
在人体关键点检测任务中,我们介绍了网络结构简单的coco2018关键点检测项目的亚军方案。
Simple Baselines for Human Pose Estimation in Fluid,coco2018关键点检测项目的亚军方案,没有华丽的技巧,仅仅是在ResNet中插入了几层反卷积,将低分辨率的特征图扩张为原图大小,以此生成预测关键点需要的Heatmap。没有任何的特征融合,网络结构非常简单,但是达到了state of theart 效果。
视频:Demo: BrunoMars - That’s What I Like [官方视频]
传送门:
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/human_pose_estimation
历史PaddleCV文章传送门:
PaddleCV-2. 计算机视觉八大任务全概述:PaddlePaddle工程师详解热门视觉模型PaddleCV-3. ActivityNet Kinetics夺冠 | PaddlePaddle视频联合时空建模方法开源
PaddleCV-4. PaddlePaddle实战 | 经典目标检测方法Faster R-CNN和Mask R-CNN
PaddleCV-5. PaddlePaddle实战 | WIDER FACE三料冠军 - Pyramidbox模型实现
PaddleCV-18. 不止有top-1近80%的ResNet50,基于飞桨(PaddlePaddle)的多种分类预训练模型强势发布
想与更多的深度学习开发者交流,请加入飞桨官方QQ群:796771754。
如果您想详细了解更多相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
项目地址:
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV





