百度推出完全端到端的并行音频波形生成模型,比WaveNet快千倍 | 论文
稿件来源:百度硅谷研究院
量子位授权转载 | 公众号 QbitAI
语音合成(Text-to-Speech,TTS)是将自然语言文本转换成语音音频输出的技术,在AI时代的人机交互中扮演至关重要的角色。
百度硅谷人工智能实验室的研究员最近提出了一种全新的基于WaveNet的并行音频波形(raw audio waveform)生成模型ClariNet,合成速度比起原始的WaveNet提升了数千倍,可以达到实时合成速度的十倍以上。
更值得注意的是,ClariNet还是语音合成领域第一个真正的端到端模型:使用单个神经网络,直接从文本输入到原始音频波形输出。
注:ClariNet名称由来——clari词根在拉丁语中是clear, bright的意思。同时clarinet是一种”端到端”的乐器,而且其声音与人的声音接近

最近,百度硅谷人工智能实验室的研究员提出的ClariNet(合成语音展示),是一种全新的基于WaveNet的并行音频波形(raw audio waveform)生成模型。
WaveNet 是目前能够完美模仿人类声音的语音合成技术(注:Google I/O大会所展示的超逼真语音合成背后的支撑技术),自从其被提出,就得到了广泛的离线应用。
但由于其自回归(autoregressive)的特点,只能按时间顺序逐个生成波形采样点,导致合成速度极慢,无法在online应用场合使用。ClariNet中所提出的并行波形生成模型基于高斯逆自回归流(Gaussian inverse autoregressive flow),可以完全并行地生成一段语音所对应的原始音频波形。
比起自回归的WaveNet模型,其合成速度提升了数千倍,可以达到实时合成的十倍以上(实时合成即合成1秒音频波形需要1秒钟的计算)。
△ClariNet模型生成音频
对比DeepMind稍早提出的Parallel WaveNet,ClariNet中所用到的teacher WaveNet的输出概率分布是一个方差有下界的单高斯分布,并且直接使用最大似然估计来学习,并不需要引入任何额外的训练技巧。
特别值得瞩目的是,ClariNet中的概率分布蒸馏(probability density distillation)过程简单优美,直接闭式地(closed-form)来计算训练目标函数KL散度(KL divergence),大大简化了训练算法,并且使得蒸馏过程效率极高——通常5万次迭代后,就可以得到很好的结果(DeepMind的论文中需要100万步迭代)。
同时作者还提出了正则化KL散度的办法,大大提高了训练过程的数值稳定性,使得蒸馏学习过程简单易训练 。而Parallel WaveNet由于需要蒙特卡洛采样来近似KL散度,使得梯度估计的噪音很大,训练过程很不稳定,外界极难重现DeepMind的实验结果——截至目前开源社区无人能够成功重现。
更值得注意的是,ClariNet还是语音合成领域第一个完全的端到端系统(end-to-end system),可以通过单个神经网络,直接将文本转换为原始的音频波形(raw audio waveform)。而先前为业界所熟知的“端到端”语音合成系统(比如Google提出的Tacotron,百度之前提出的Deep Voice 3 ),实际是先将文本转换为频谱(spectrogram),然后通过波形生成模型WaveNet或者Griffin-Lim 算法,将频谱转换成原始波形输出。
这种方法由于文本到频谱的模型和WaveNet是分别训练优化的,往往导致次优的结果。而百度研究员提出的ClariNet,则是完全打通了从文本到原始音频波形的端到端训练,实现了对整个TTS系统的联合优化, 比起分别训练的模型,在语音合成的自然度上有大幅提升(参见文末合成语音示例)。
另外,ClariNet是全卷积模型,模型隐状态(hidden states)之间没有顺序依赖关系,可以完全利用GPU这样的并行计算资源,因而训练速度比起基于循环神经网络(RNN)的模型要快10倍以上。
ClariNet的网络结构如下图所示。
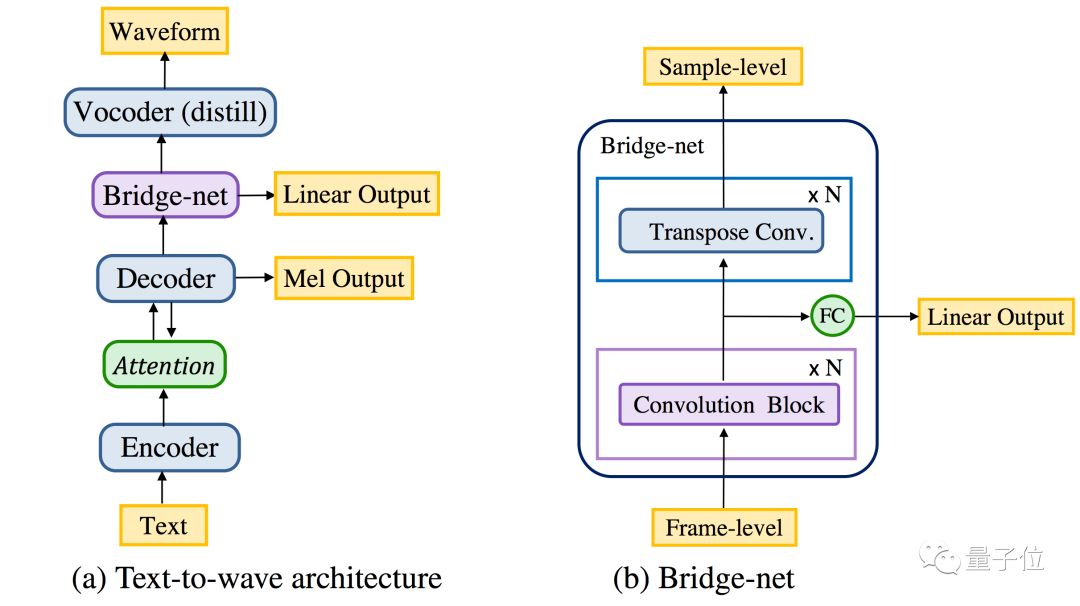
它使用基于注意力机制(Attention)的编码器-解码器模块(Encoder-Decoder)来学习文本字符与频谱帧之间的对齐关系。解码器的隐状态(hidden states)被送给Bridge-net来进行双向的时序信息处理和升采样(upsample)。最终Bridge-net的隐状态被送给音频波形生成模块(Vocoder),作为其条件输入(conditioner),来最终合成原始音频波形。整个网络的各个模块,使用一维卷积操作(convolution block)来进行时序信息的建模。
传送门

论文地址:https://arxiv.org/pdf/1807.07281.pdf
合成语音示例:https://clarinet-demo.github.io/
— 完 —
资源推荐

△ 扫码或点击“阅读原文”,可查看腾讯WeTest最新测试福利。
腾讯WeTest引入AI技术,开放“深度兼容测试”,并提供更多测试优惠,为广大测试者提高工作效率,降低测试成本

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




