赛尔原创 | COLING 2018 上下文敏感的开放域对话回复生成
作者:哈工大SCIR 李凌志 张伟男
1 摘要
目前在单轮回复生成任务中,研究人员提出了较多的方法,也带来了一定程度的提升,但从回复连贯性角度考虑,人类的回复过程实际是一个上下文敏感的过程,受到现有工作的启发,我们提出了应用于上下文敏感回复生成的动态和静态注意力机制网络。在两份公开数据集的实验结果表明,我们提出的方法在客观指标和主观指标均优于现有方法。
2 论文介绍
近年来,训练一个说话内容、方式与人类似的开放域对话系统,成为了学术研究的热点和难点,之前的研究工作包括非监督聚类方法、短语统计机器翻译方法或向量空间搜索方法等等,随着深度学习的兴起,目前这一任务多数建模成端到端的“编码-解码”过程,在单轮回复生成任务中,现有的方法取得了一定的进步,但从人类对话过程中观察,我们的回复过程实际上是一个上下文敏感的过程,如表格1所示,不同的上下文对回复内容影响很大。
表格1 不同上下文对人类回复产生不同影响举例

2.1 研究现状
目前采用“Seq2Seq”的对话生成模型一般包含“编码器”和“解码器”两部分,“编码器”将输入信息编码成一串语义向量,“解码器”根据该语义向量和前面的隐层状态向量逐词生成回复。在包含上下文的回复生成模型中,“编码器”通常编码前几轮对话历史信息,因此,一个关键问题就是如何建模对话历史信息。图1介绍了目前在上下文敏感对话生成的两种最好的编码方式。
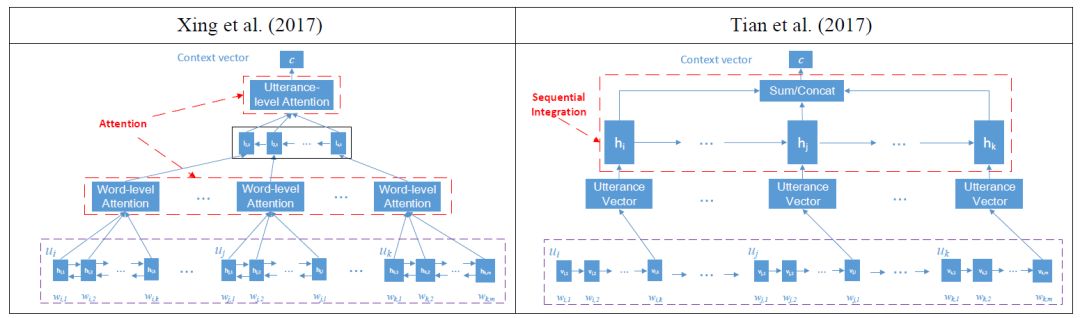
图1 两种目前最优的上下文敏感对话生成编码方法
两种方法均是先将上下文每句语句编码成语句向量,然后层次化的建模出用于解码过程的编码向量“c”。以上两种方法在语句表示和语句间建模上有所不同。
2.2 模型介绍
我们提出的方法同样采用了“编码-解码”框架,为了更好地表示上下文信息,我们采用层次化表示的建模方法来编码上下文,受到现有最优方法的启发,在句内我们采用GRU建模语句表示,并提出用于建模句间表示的两种注意力机制,分别是动态注意力机制和静态注意力机制,模型建模过程如图2。
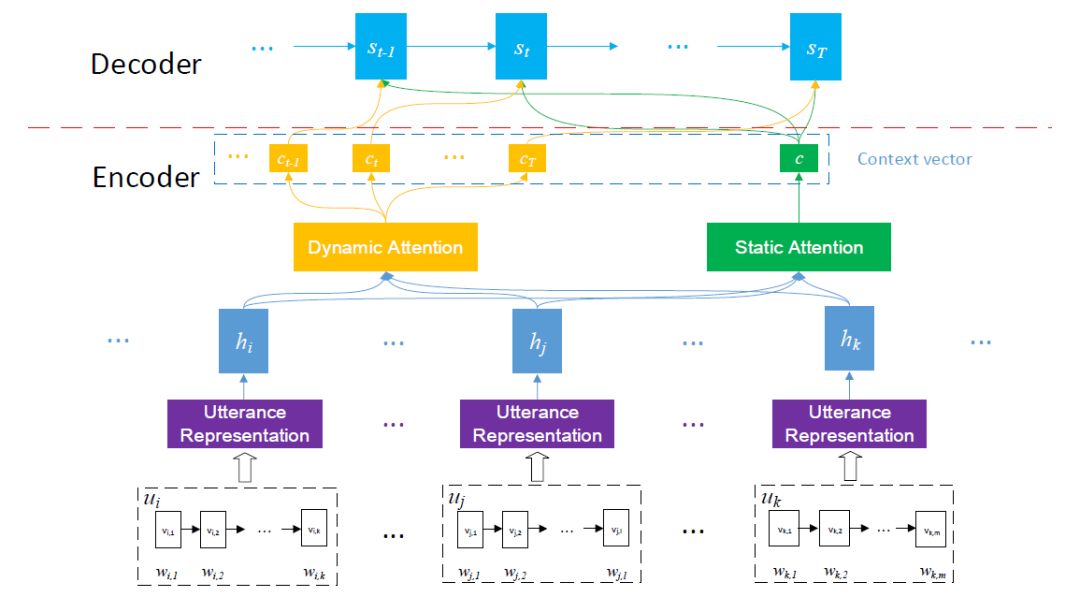
图2 动态、静态注意力机制编码上下文示意图
2.2.1 静态注意力机制解码过程
如图2所示,静态注意力机制计算每一个输入语句的重要性,从而根据权重计算出用于解码的隐层状态“c”,注意力计算过程如下:
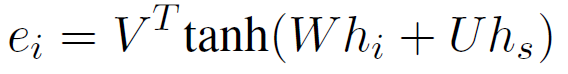
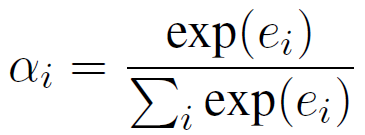
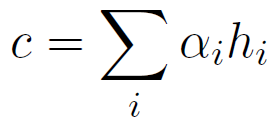
其中hi和hs分别表示上文第i句和最后一句的隐层状态,V、W和U是参数,每一句话的权重计算出来后,在解码过程中都不会改变。解码过程中,第t步隐层状态st可以按如下计算:
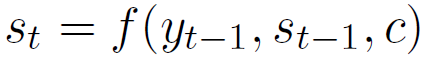
其中yt-1是解码的第t-1步输出,是st-1解码第t-1步的隐层状态。
2.2.2 动态注意力机制解码过程
静态注意力解码过程是在解码之前固定每一句话的权重,而动态注意力解码过程是维护一个权重矩阵,在解码过程中动态的更新每一句话的权重。动态注意力计算过程如下:
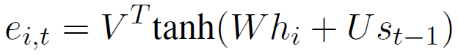
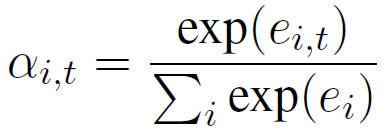
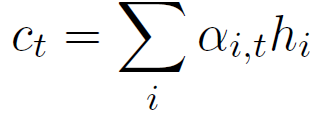
其中V、W和U是独立于静态注意力机制的另外一套参数,ei,t和αi,t在解码第t步计算出来,而第t步隐层状态通过如下公式计算:
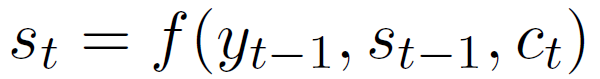
2.3 模型比较
该方法与之前提出的两种现有研究方法的主要不同之处,在于获取上下文表示的建模过程。之前的研究(Xing et al., 2017)采用层次化注意力网络来获取对话上下文表示,而我们提出了两种语句级别的注意力方法,来为上下文中每一句话分配权重,结构上更简单,包含更少参数。同时与采用启发式方法来进行编码向量计算不同(Tian et al., 2017),我们提出的方法中,注意力机制的权重是从数据中学习而来,相比之下更灵活有效。
3 实验结果
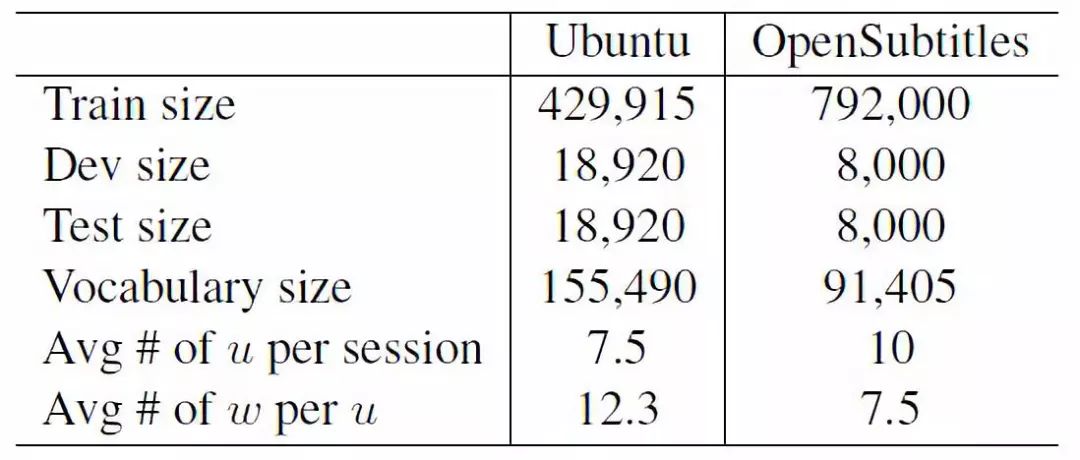
我们在回复生成相关的公开数据集Ubuntu和OpenSubtitles上进行了实验,数据情况如表格2所示。
表格2 数据统计情况
为了实验比较,我们设立了六个基线方法,其中四种(VHRED,CVAE,WSI和HRAN)均是目前在回复生成任务上最优的方法,具体可查阅参考文献。
针对同一句话可以有不同但同样优良的回答,所以,应用于机器翻译的BLEU、应用于语言模型的困惑度评价等方法,均不完全适合于该任务的评价。目前在回复生成相关任务的评价上,一般同时采用客观、主观两种评价方法。
3.1 客观指标
我们采用了Serban提出的评价矩阵进行客观指标验证,该方法侧重计算生成语句与答案之间的语义相似度,从Average、Greedy和Extrema三个角度进行衡量,具体计算过程可参考引用文献。
表格3 客观指标实验结果
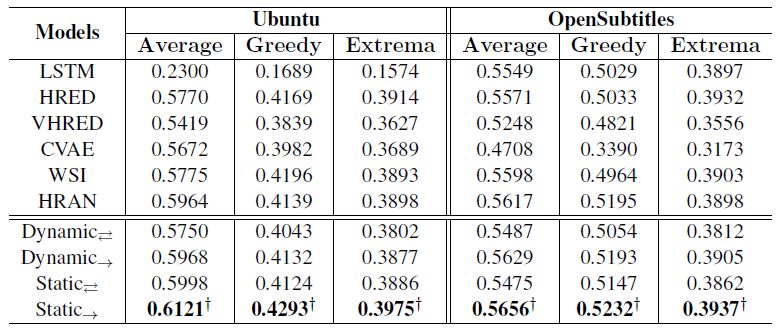
实验结果如表格3所示,其中单向和双向箭头表示使用单向/双向GRU单元,最优的静态单向实验结果经过了p<0.05的统计显著性检验。
从实验结果可以看出,我们提出的使用静态注意力机制的上下文敏感回复生成模型在两个数据集上优于其他所有基线模型,它验证了句子级注意力机制在回复生成的上下文建模过程中的有效性。比较静态和动态注意力实验结果,我们发现,动态估计每个语句的重要性的效果要稍逊于静态方法,原因可能在于动态注意力模型的上下文编码向量在每步解码过程中都是变化的,导致解码出了连贯性稍差的回复。
3.2 主观指标
在主观指标上,我们设立了连贯度、自然度和多样性三个指标,如表格4所示。连贯性指标侧重于评价生成语句与上文之间的连贯程度,设置0,1,2,分别代表上下文和生成回复的不连贯、中立、连贯三个评价等级;自然度用于评价生成语句是否与人类回复相似,设置0,1两个评价等级;多样性指标表示生成回复中不同的词语占全部对话内容的比例,数值越高代表生成的回复越多样。
表格4 主观指标实验结果
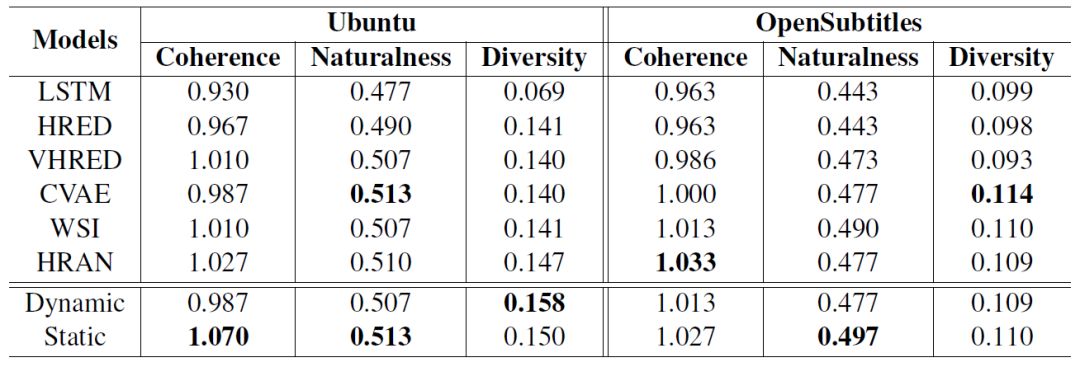
我们从Ubuntu和OpenSubtitles数据集中各随机采样500组测试样例,由三名打分人员对全部模型的实验结果进行打分,最终每个模型的分数为三个打分人员所打分数的平均值。从实验结果可以看出,我们提出的静态注意力机制模型在Ubuntu数据集的连贯性上优于其他模型。在多样性方面,动态注意力机制模型在Ubuntu数据集上同样优于其他模型。而在自然度上,静态注意力机制模型在两个数据集上均取得了最优效果。
3.3 上下文长度分析
为了验证不同上下文长度对于提出模型的影响,我们使用不同的上下文长度重新训练模型,图3展示了实验结果,可以看出,我们提出的方法对于上下文处于敏感状态,受到编码上文语句数量的影响。
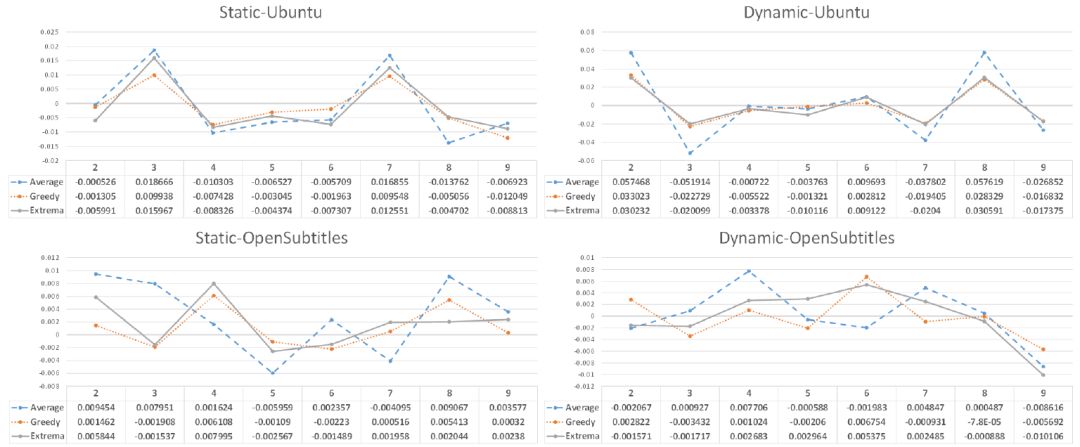
图3 上下文长度2~9对于生成语句客观指标的影响曲线
图4展示了从静态注意力机制模型测试结果中取样的两个对话样例,可以从注意力模型的分数权重上看出,我们的方法能够有效的为上文语句划分重要程度,并侧重于依赖重要语句来生成相关性、连贯性较高的回复。

图4 静态注意力网络测试样例
4 总结
本文提出了新的开放域对话回复生成的上下文敏感建模方法,该模型从静态、动态注意力两个角度学习上下文信息和句间表示。实验结果表明,提出的方法在客观、主观的大多数指标上均超过了目前几种最好的方法。本文同时验证了不同上下文长度对于提出模型生成效果的影响。未来的工作中,我们会继续探索联合建模静态、动态注意力机制用于解码的方法,提升现有方法论的效果。
点击文末“阅读原文”查看往期精彩原创推送。
本期责任编辑: 丁 效
本期编辑: 赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




