英特尔戴金权:AI的训练与部署需要统一的基础设施架构来加速|GTIC2019
看点:戴金权指出,AI在训练与部署中存在着数据存储与多类数据流处理割裂的情况降低了工作效率,需要统一的基础设施架构进行加速。


3月15日,由智东西主办,AWE和极果联合主办的GTIC 2019全球AI芯片创新峰会在上海成功举办!本次峰会报名参会的观众覆盖了近4500家企业,到会观众极为专业,其中总监以上级别占比超过62%,现场实际到会人数超过1800位。
大会现场来自学术、投资、安防、芯片等多个领域的21位重磅嘉宾共聚一堂,系统的探讨了AI芯片在架构创新、生态构建、场景落地等方面的技术前景和产业趋势。

▲英特尔高级首席工程师、大数据技术全球CTO 戴金权
作为半导体行业巨头的英特尔,在今天的峰会上,英特尔高级首席工程师、大数据技术全球CTO戴金权进行了主题为《Analytics Zoo:统一人工智能与大数据》的演讲。在演讲中,他指出人工智能训练、部署中存在的数据存储与多类数据流处理割裂的情况降低了工作效率,需要一个统一的基础设施架构来加速AI的训练与部署。
戴金权表示,针对上述现象,英特尔基于至强计算平台、傲腾数据存储器,结合英特尔的云服务推出了大数据分析与人工智能统一平台Analytics Zoo。它可以将分布在Tensorflow、Keras、Apache Spark等不同深度学习框架上的数据整合到同一个工作流中进行处理,再将训练结果无缝部署到云端,统一的流程简化了人工智能算法训练与部署的流程,提高了效率。目前,英特尔的Analytics Zoo已经被美的、世界银行等企业和机构的应用于相关项目。
附英特尔高级首席工程师、大数据技术全球CTO戴金权演讲实录
戴金权:谢谢大家,我是来自英特尔公司的戴金权。今天和大家分享一下英特尔是如何构建像Analytics Zoo这样的大数据分析和AI平台,从而支持各种软硬件的技术,以及与客户、合作伙伴一起将这些创新应用到实际的应用场景中。

为什么要这么做?刚才我说到,我们在英特尔做了很多工作,包括像Analytics Zoo这样能够将大数据分析和人工智能统一起来的平台,我们为什么要这么做呢?其实我们也看到了,在大数据分析,在人工智能中,其实有一个很重要的点就是没有一种解决方案是能够解决所有问题的。

在英特尔我们一直致力于提供从端到端,包括设备端、边缘、网络到数据中心的一个端到端完整的解决方案或者计算架构,比如像Movidius、我们的至强处理器、NNP这样的神经网络处理器,构成了端到端的一个完整计算架构。其中我特别要提到,今天我们的至强服务器作为通用处理器仍然是大数据分析和人工智能的一个基础架构,它包括了Cascade Lake、下一代的至强可扩展处理器、以及支持一些新的功能,包括了像傲腾这样的数据中心级的持久内存,它们构成了一个非常基础的、应用非常广泛的大数据的人工智能+大数据分析的技术平台。

在这个前提下面,我们如何在像至强这样的一个基础的人工智能、大数据分析基础的计算平台上面,利用Apache Spark等为代表的大数据分析框架在平台上构建人工智能的能力呢?在这里,我们在英特尔做了几件事情。
第一,BigDL,这是我们英特尔开发并且开源的一款基于Apache Spark的分布式深度学习的框架。大家知道在业界,今天以Apache Spark等开源项目为中心的大数据处理分析的平台,从某种意义上已经成为业界标准。我们在这些大数据的平台上直接提供了一个原生的深度学习库,能够让用户直接在现有大数据框架如Spark等上面,可以运行深度学习的应用,同时对底层大规模分布式至强服务器等硬件集群做了大量的优化。
在这个上面,对很多用户来说,一个关键的痛点或者需求也好是如何能快速地从数据出发,最终将人工智能+大数据分析应用构建出来。在这个基础之上,去年我们开源了Analytics Zoo,这是我们基于Apache Spark上统一的大数据分析+人工智能平台。它能够无缝将TensorFlow、BigDL等一些深度学习的框架无缝地集成到端到端的大数据处理的一个工作流当中。
这个工作流或者流水线能够分布式进行,这样做对用户的好处有几个方面:
第一,对于大多数用户来说,尤其在生产系统当中,基于Apache Spark这样的大数据集群仍然是所有的生产数据以及包括大量硬件资源的聚集地,如何更高效利用这些生产数据以及这些硬件资源,能够将新的人工智能的应用支持起来。
第二,要构建一个工业级端到端的大数据分析+人工智能应用,并不是说训练一个模型就可以完成的事情,它是一个非常复杂的流水线或者工作流。从数据的收集、导入、处理、特征的提取、各种模型的构建训练,到最后的部署、推理等等,是一个非常复杂的工作流。我们能够帮助用户可以将这一个样端到端的大数据处理分析加上机器学习的工作流能够非常方便地构建出来,从而大大能够提高了用户的开发效率、部署效率和运维效率。
说了那么多,下面用一个简短的视频,让大家感性地认识一下我们在Analytics Zoo上面做的工作,以及它给用户提供的好处。

大家看了这些视频后,对Analytics Zoo会有一个感性上面的认识,下面来看一下它里面一些具体技术上面的细节。刚才我提到了Analytics Zoo可以运行在一个大规模的分布式的集群上,底层会使用像TensorFlow,MKL-DNN等这样的深度学习框架,上层给用户提供一些高级的流水线的API用以构建端到端的应用,以及一些通用的或者常用的支持,包括对图片、文本、时间序列数据等等。在这之上我们发现有很多应用场景有其共性,因此我们提供了非常多的内置深度学习模型,用户可以将内嵌的模型嵌入到解决方案当中。
我们的目的是希望通过Analytics Zoo构建一个统一的大数据+人工智能大数据分析平台,能够帮助用户开发部署深度学习、人工智能和大数据分析的应用。举一个例子,我们可以将TensorFlow和Apache Spark无缝地整合到端到端的流水线当中,让TensorFlow无缝地接受Apache Spark处理的数据,同时对用户透明,分布式地运行在大数据集群上。
此外,我们也提供了像基于标准的JAVA 、Python、Web Server、深度学习特别是视觉方面的神经网络加速,帮助用户更方便地部署到Web Server等上面,帮助用户更好地做模型和服务。此外,刚才我也提到,我们在里面提供了一些神经网络,包括用户参考案例,可以很方便地集成到最终的终端中去。
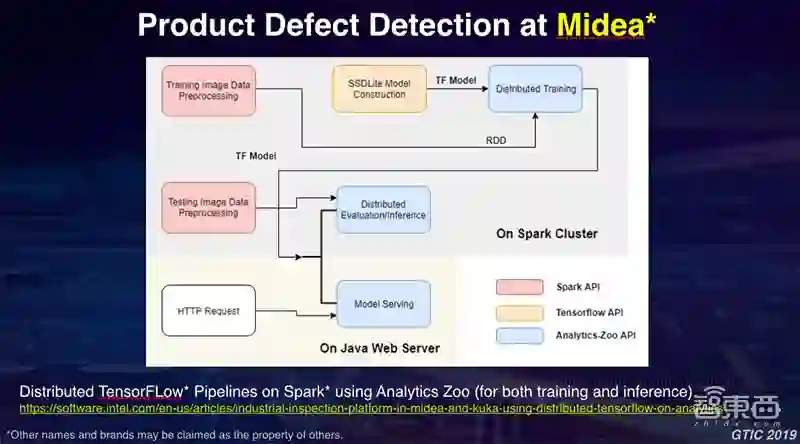
让我们看一下实际的案例,看一下如何应用Analytics Zoo平台。这是我们和美的的一个合作,美的是一个非常大的电器生产商,它们利用工业机器人做非常多的工作。我们跟美的的合作方式是,使用英特尔的至强服务器、边缘设备构建一个对美的工业机器人生产流水线上的产品进行自动检测的系统。
比如说,在我们的生产流水线上有非常多的微波炉或者空调正要下线,我们需要检测这些产品是否合格,比如说有没有贴标签,螺丝有没有拧上等等。我们希望通过深度学习神经网络能够自动来做这件事情。比如工业机器人可以戴上相机进行拍照,照片可以通过数据处理,利用我们的神经网络检测照片中的产品是否有问题。具体的技术细节我在这里不展开了,在我们英特尔以及美的的网站上有一些具体的技术细节解释,大家感兴趣的话可以访问下面的链接。
利用像Analytics Zoo这样的端到端平台,可以用Apache Spark大规模对图片进行处理,当流水线有非常多的图片数据进来,我们用Spark进行大规模分布式处理。上面粉红色的框代表了我们使用TensorFlow直接构建了一个深度神经网络的模型,我直接将Spark处理的大规模图片数据接入到TensorFlow的模型当中进行分布式的训练,当有了训练好的模型以后,蓝色的框代表Apache Spark里面的一些模块,这里是在JAVA Web Server里面,直接将模型部署在其上,可以实时发布到Web Server上,对它进行推理和判断。在这个过程中,我们将Spark、TensorFlow这样端到端的工作流直接在Apache Spark的平台上能够整合在一个统一的流水线当中,从而大大提高了开发效率和生产效率。
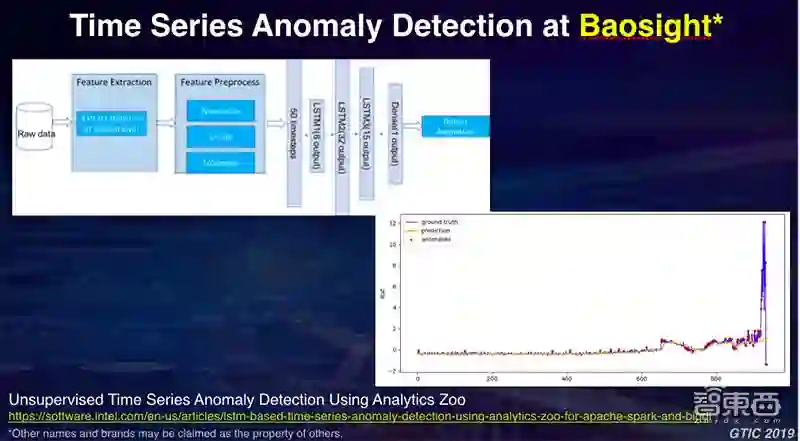
另外一个例子是我们和宝信的一个合作,大家知道宝信是一个非常大的制造商,因此他们有很多的设备,我需要对这个设备进行维护或者要预测它是不是会有问题。这里我们收集的数据是设备的一些震动频率的数据,从某种意义上是一个时间序列数据,在每一个时间点上收集到它的振动频率,我希望通过一些无监督的方式,在时间序列上能够自动检测出这个设备是否快要出问题,技术细节我不展开了。在时间序列上构建起一个相应模型,到最后的训练,我们通过Apache Spark能够很好地对其震动曲线同时进行报警。
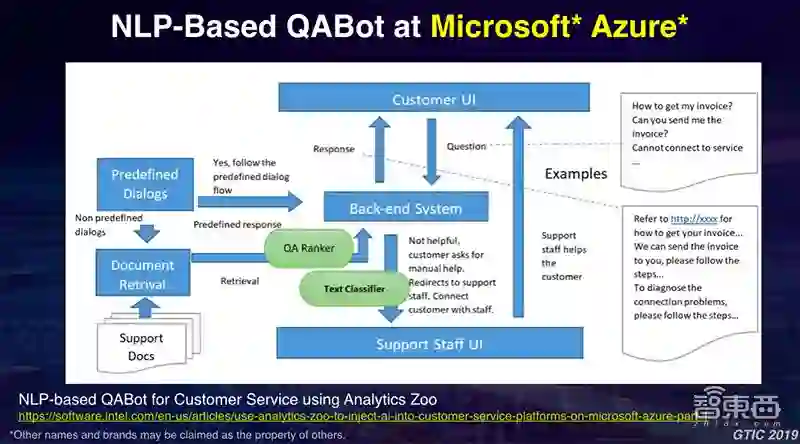
后面还有一些例子,比如说像我们跟Microsoft Azure的合作,如何使用基于NLP的自然语言处理技术,对其客服系统进行优化。通过NLP界面,包括对文本进行分类,或者对问题和回答进行匹配,来提高客服机器人回答问题的能力。

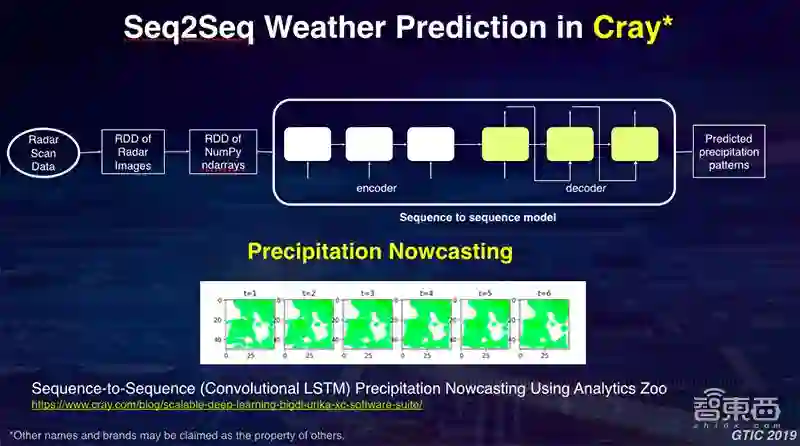
下面还有更多的例子,时间关系不具体讲了。这是我们跟世界银行的合作,在AWS上面做的一些对世界银行在各地拍摄的图片进行分类和统计的工作,以及我们和Cray公司,通过Seq2Seq模型,把过去一小时的卫星云图做一个序列,输入到模型里面,从而对天气进行短期预测。
我们有非常多的用户和客户在Analytics Zoo大数据分析+人工智能统一平台上构建起他们的各种场景应用,能够非常方便、高效运行在其现有的大数据集群上。这也是英特尔希望做的事情,我们希望通过能够构建一个统一的大数据分析+AI平台,能够将各种不同的技术,包括像大数据的技术,以及像TensorFlow、BigDL等技术整合到端到端的平台上,从而大大提高客户开发部署和运行的效率。
Analytics Zoo是一个开源的项目,欢迎大家了解使用,并且给我们更多的反馈。谢谢大家!
本账号系网易新闻·网易号“各有态度”签约帐号
作媒体和会议合作伙伴,车东西将于4月19日在车展期间主办年度峰会GTIC 2019全球智能汽车供应链创新峰会。来自滴滴出行、腾讯、博世、小马智行、伟世通、法雷奥、恩智浦、小鹏汽车等9家企业的大咖已经确定参会。扫码免费报名。