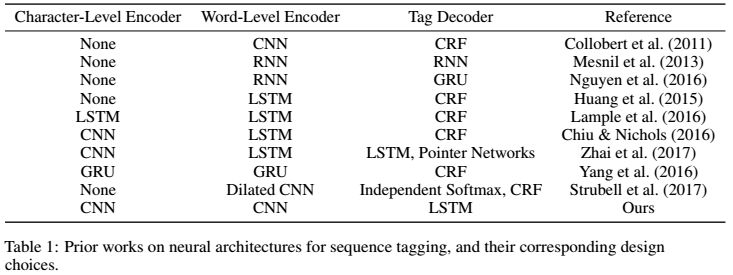
笔记 | Deep active learning for named entity recognition

本文来自知乎专栏:西土城的搬砖日常
深度学习(deep learning)的方法在命名实体识别(NER)任务中已广泛应用,并取得了state-of-art性能,但是想得到优秀的结果通常依赖于大量的标记数据。本文证明当深度学习与主动学习(active learning)相结合时,标记的训练数据的量可以大大减少。为了加速主动学习这一过程,本文为NER引入了一种轻量级架构,即CNN-CNN-LSTM模型,由CNN字符编码器和CNN词编码器以及一个长期短期记忆(LSTM)标签解码器组成。
实验证明,结合主动学习时仅使用25%的训练语料就可接近使用完整数据的效果。
1、标注策略

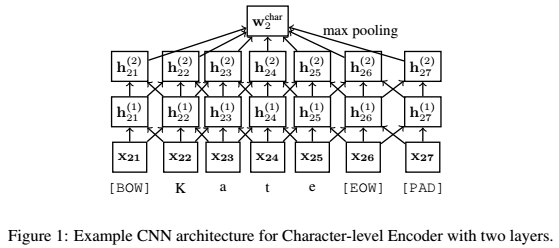
2、Character-Level Encoder
使用CNN进行字符级编码,虽然效果略逊于LSTM,但优点在于计算成本低。在两层CNN之间应用ReLU和dropout,在最后添加max-pooling层,得到character特征。
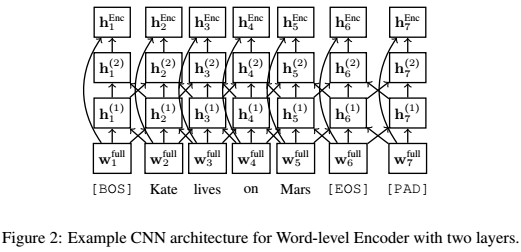
3、Word-Level Encoder
将character特征与word embedding拼接起来作为word encoder的输入:
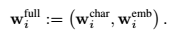
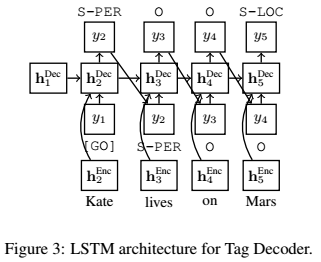
4、Tag Decoder
使用LSTM作为decoder,在第一个时间步,将[GO] - 符号作为 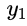
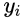
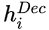
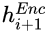
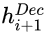
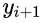
数据集的大小严重影响训练效果,本文使用主动学习来改善这个问题,通过有策略的选择部分示例进行注释,以求获得更高的性能。 本文使用交互式方法,学习过程由多个回合组成:在每个回合开始时,主动学习算法选择句子进行注释,对扩充数据集进行训练来更新模型参数,然后进入下一轮。
三种选择策略:
1、Least Confidence (LC)
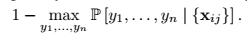
这个式子的意思是寻找未标注数据集中,最难判别类别的数据,也就是说,对于这个,现有的分类器没有足够的自信心。这样的数据应该被人工标注,因为它的信息量很大。
2、Maximum Normalized Log-Probability (MNLP)
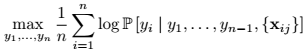
使用LC会倾向于选择长句子,本文提出了归一化对数概率的方法
3、Bayesian Active Learning by Disagreement (BALD)
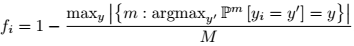
fi表示第i个词的不确定性,M = 100 independent dropout masks,P1, P2, . . . Pm: models,最后经过normalize,即
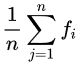
另外,为避免抽样带来的偏差性,得到更具有代表性的抽样,本文提出使用效用函数fw的方法,其定义为所有未标记点的边际效用增益的总和,进行不确定加权:(这一方法在本文实验中未使用)
1、模型的表现
实验证明CNN-CNN-LSTM的表现不逊色于其他架构,但使用CNN作为编码器和使用LSTM作为解码器比使用LSTM和CRF节省大量时间开销。

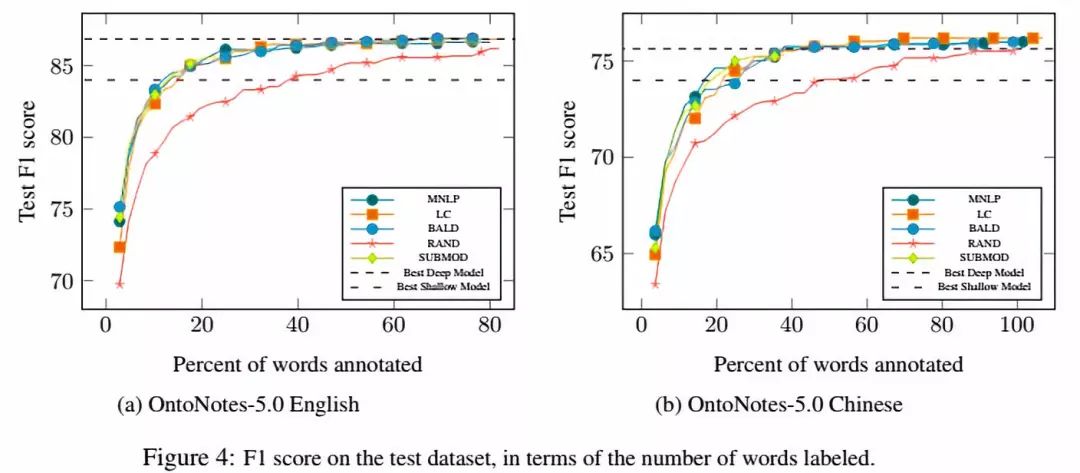
2、主动学习的表现
使用三种选择策略进行主动学习,所有算法都以相同的原始训练数据的1%作为初始数据集,随即初始化模型。 在每一轮中,每个算法都会从剩余的训练数据中选择句子,直到选择了20,000个单词为止。
所有的主动学习算法都比random baseline表现得更好,其中MNLP和BALD略优于LC。
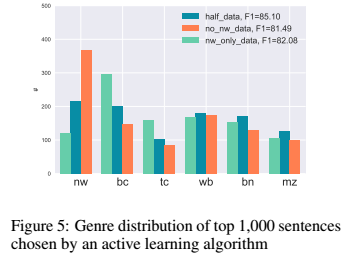
3、关于主动学习中类别选择的探索
本文使用了三个训练数据集:包含原始训练数据的随机50%的half-data,仅包含来自newswire语料的nw数据,以及no-nw-data。在half-data的实验中,f1达到了85.10,明显优于其他有偏倚数据集,说明类别无偏差的重要性。
其次,本文分析了主动学习为这三个数据集选择的数据类别分布,对于no-nw-data,该算法选择的newswire(nw)句子多于无偏差的half-data(367 vs 217),证明主动学习算法可自动发现现有数据中缺失的数据类型,选择并添加到原有数据集中。
本文将深度学习与主动学习结合起来,在少量的训练数据下实现了state-of-art的性能。


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Highway Networks For Sentence Classification
 欢迎关注交流
欢迎关注交流




