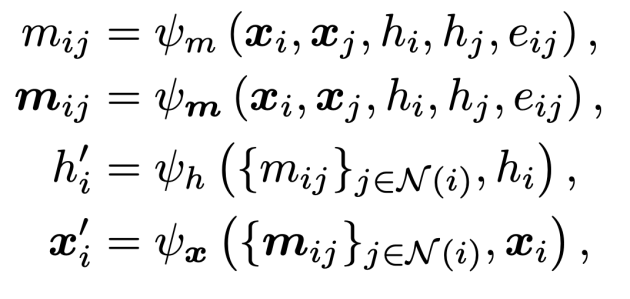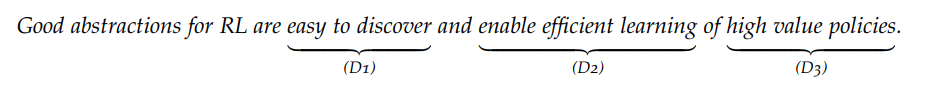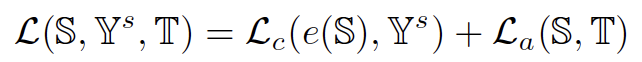机器之心 & ArXiv Weekly Radiostation
本周论文包括腾讯 AI Lab、清华共同发文综述等变图神经网络;美图 & 北航分布感知式单阶段模型入选 CVPR 2022 等研究。
Geometrically Equivariant Graph Neural Networks: A Survey
ViKiNG: Vision-Based Kilometer-Scale Navigation with Geographic Hints
Distribution-Aware Single-Stage Models for Multi-Person 3D Pose Estimation
A Theory of Abstraction in Reinforcement Learning
Weakly Supervised Object Localization as Domain Adaption
Spelling interface using intracortical signals in a completely locked-in patient enabled via auditory neurofeedback training
Survey on Large Scale Neural Network Training
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Geometrically Equivariant Graph Neural Networks: A Survey
摘要:
腾讯 AI Lab, 清华 AIR & 计算机系在综述:《Geometrically Equivariant Graph Neural Networks: A Survey》中,对等变图神经网络的结构和相关任务进行了一个系统梳理。
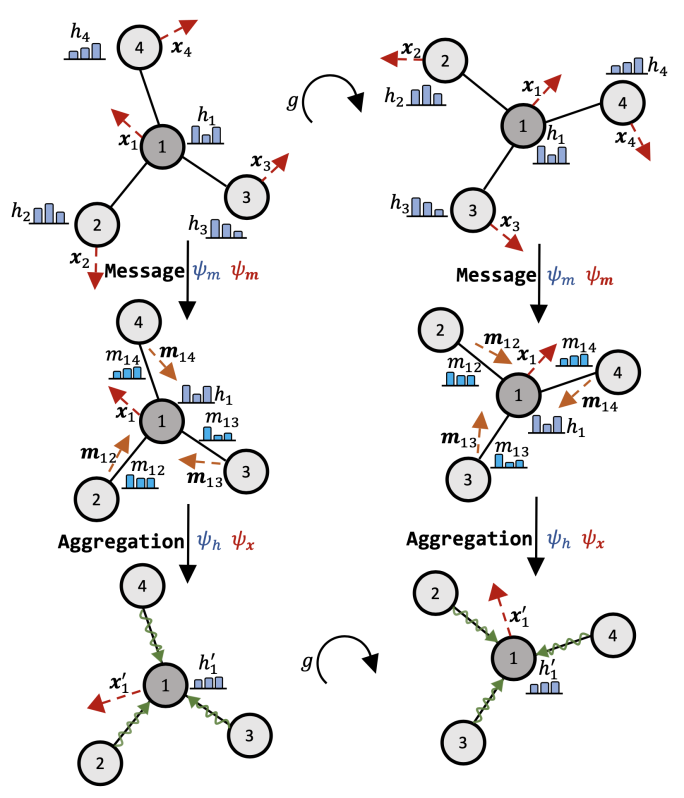
在这篇综述里面,该研究系统性的梳理了近年等变图神经网络的发展脉络,并且提供了一个简洁的视角帮助读者能够很快的理解这类网络的内涵。基于消息传播和聚合函数的不同,该研究将现有的等变图神经网络分为三类。与此同时,他们还详尽阐释了当前的挑战和未来的可能方向。
在实际应用中,我们需要处理的图不仅包含拓扑连接和节点特征,同时也会包含一些几何特征。在使用图神经网络处理这些数据的时候,不同的特征需要满足不同的性质。例如,在预测分子的能量时,我们需要这个预测对于输入的几何特征是不变的,而在分子动力学应用中,我们则需要预测的结果和输入的几何特征是等变的。为了达到这样的目的,我们提出了一个等变图神经网络的通用框架:
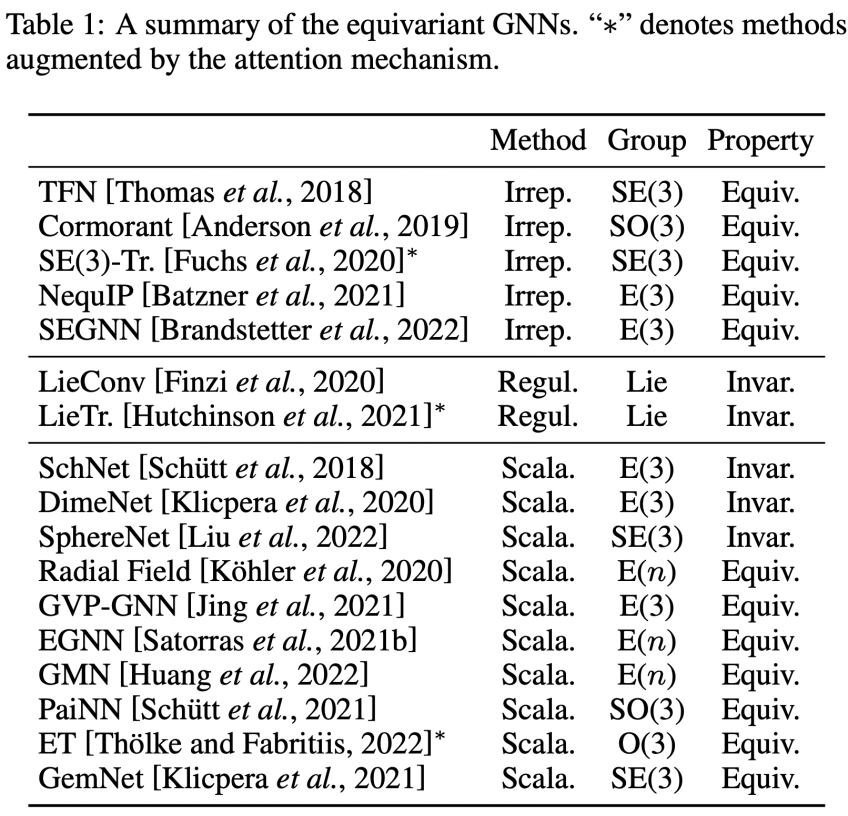
基于以上的通用框架,该研究在下表总结了当前主流的等变图神经网络模型。与此同时,基于消息表示的类别不同,该研究将现有的等变图神经网络模型分为三大类:不可约表示 (Irreducible Representation),正则表示 (Regular Representation) 和标量化 (Scalarization )。
推荐:
GNN for Science: 腾讯 AI Lab、清华共同发文综述等变图神经网络。
论文 2:ViKiNG: Vision-Based Kilometer-Scale Navigation with Geographic Hints
摘要:
在近期一篇论文《ViKiNG: Vision-Based Kilometer-Scale Navigation with Geographic Hints》中,UC 伯克利分校的人工智能博士生 Dhruv Shah 及其导师 Sergey Levine 探索了一种不同的机器人导航方式。他们主张机器人导航中消除高端耗能的组件,只需要一个单目相机、一些神经网络、一个基础的 GPU 系统以及一些以人类可读的非常基础的俯视图形式的简单提示就足够了。这样的提示听起来可能没有那么有影响力,但它们使一个非常简单的机器人能够高效、智能地穿越陌生环境,到达遥远的目的地。
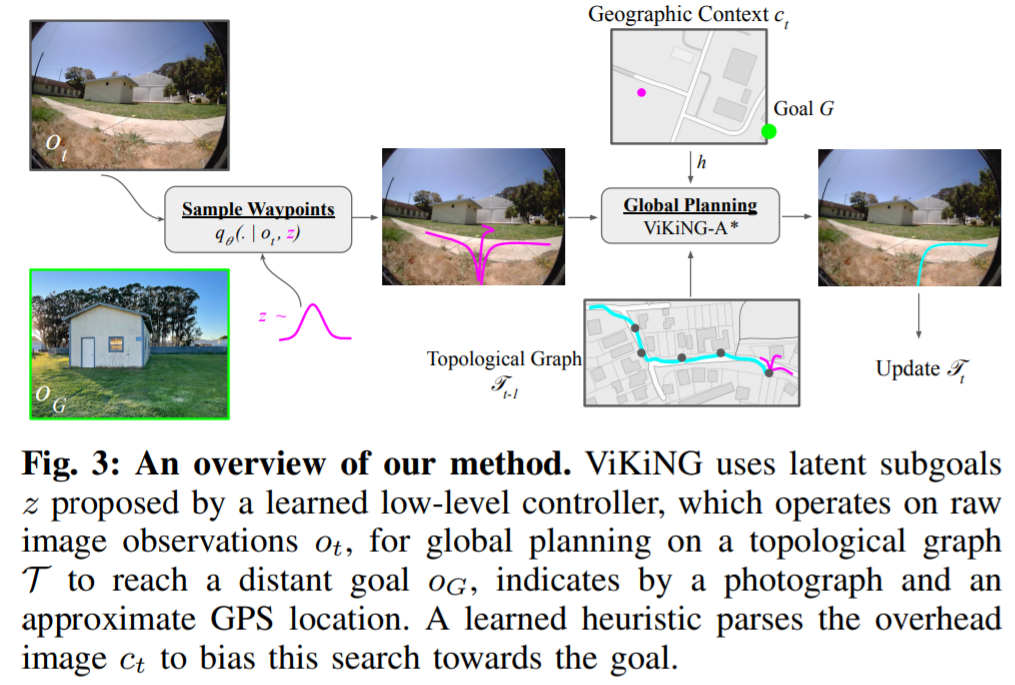
具体而言,该研究提出了一种基于学习的方法,即将学习和规划集成起来,并且可以利用诸如示意路线图、卫星地图和 GPS 坐标等辅助信息作为规划启发式。ViKiNG 结合了一个局部可遍历性模型,该模型可以查看机器人当前基于相机的观察结果和一个潜在子目标,以推断到达子目标难易程度。
此外,ViKiNG 还包括一个启发式模型,该模型查看俯视图并尝试估计各种子目标到目的地的距离。ViKiNG 不执行显式几何重建,只利用环境的拓扑表示。尽管在 ViKiNG 训练数据集中从未见过超过 80 米的轨迹,但其可以利用基于图像的学习控制器和目标导向启发式(goal-directed heuristic),在以前没见过的环境中导航到最远 3 公里以外的目标,并表现出复杂的行为。ViKiNG 对不可靠的地图和 GPS 也有很强的鲁棒性,因为底层控制器最终基于自身图像观察做出决策,而地图仅作为规划的启发式。ViKiNG 机器人的导航是这样的:
![]()
![]()
推荐:
地图、GPS 不靠谱也无妨,UC 伯克利机器人陌生环境导航超 3 公里。
论文 3:Distribution-Aware Single-Stage Models for Multi-Person 3D Pose Estimation
摘要:
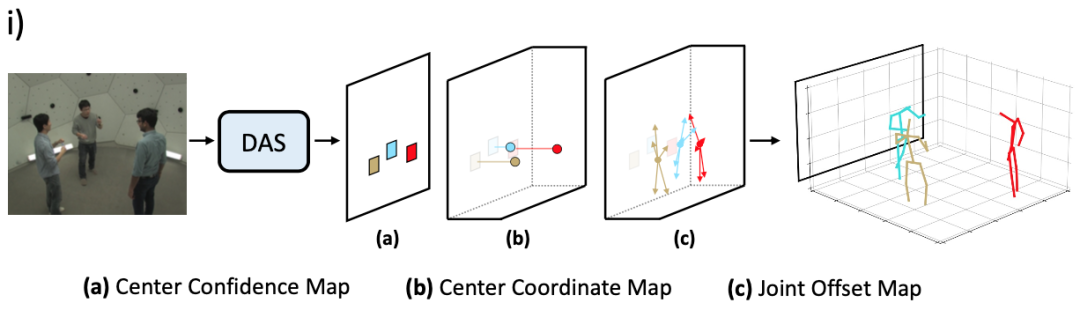
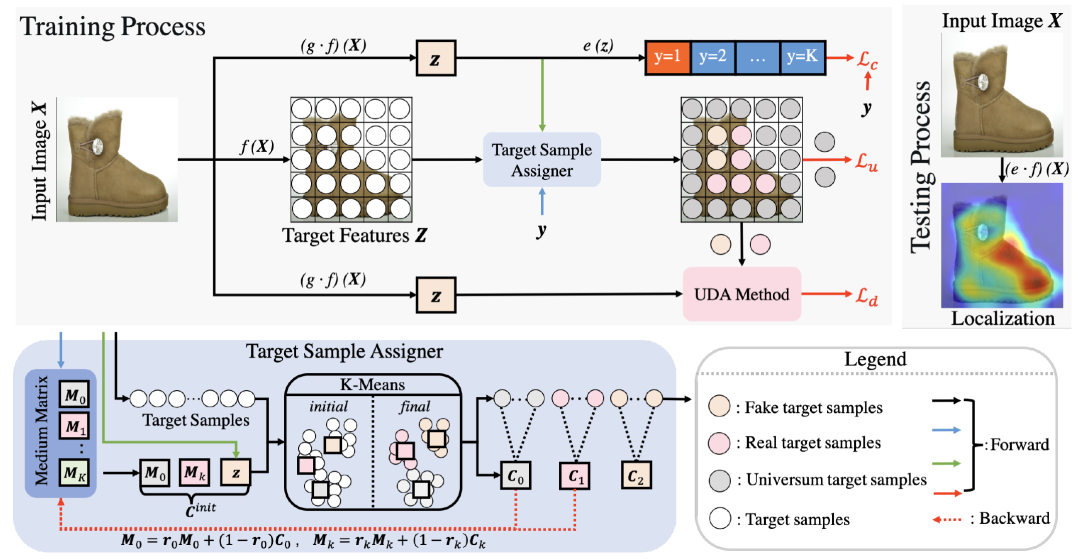
美图影像研究院(MT Lab)与北京航空航天大学可乐实验室(CoLab)在 CVPR 2022 发表的论文,提出一种分布感知式单阶段模型,并利用这一模型从单张 RGB 图片中估计多个人在 3D 相机空间中的人体姿态。该方法将 3D 人体姿态表示为 2.5D 人体中心点和 3D 关键点偏移量,以适配图片空间的深度估计,同时这一表示将人体位置信息和对应的关键点信息进行了统一,从而使得单阶段多人 3D 姿态估计成为可能。
此外,该方法在模型优化过程中对人体关键点的分布进行了学习,这为关键点位置的回归预测提供了重要的指导信息,进而提升了基于回归框架的精度。这一分布学习模块可以与姿态估计模块在训练过程中通过最大似然估计一起学习,在测试过程中该模块被移除,不会带来模型推理计算量的增加。为了降低人体关键点分布学习的难度,该方法创新性地提出了一种迭代更新的策略以逐渐逼近目标分布。
该模型以全卷积的方式来实现,可以进行端到端的训练和测试。通过这样一种方式,该算法可以有效且精准地解决多人 3D 人体姿态估计问题,在取得和两阶段方法接近的精度的同时,也大大提升了速度。
图 1:用于多人 3D 人体姿态估计的分布感知式单阶段模型流程图。
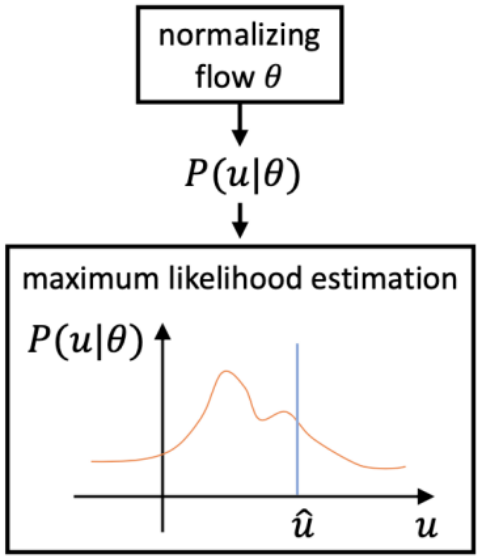
与现有方法不同,DAS 模型在优化过程中学习 3D 人体关键点分布的真实分布,指导关键点回归预测的过程。考虑到真实分布不可追踪的问题,DAS 模型利用标准化流(Normalizing Flow)来达到对于模型预测结果概率估计的目标,以生成适合模型输出的分布,如图 2 所示。
推荐:
精准高效估计多人 3D 姿态,美图 & 北航分布感知式单阶段模型入选 CVPR 2022。
论文 4:A Theory of Abstraction in Reinforcement Learning
摘要:
在前段时间结束的第 36 届 AAAI 人工智能会议上,大会官方公布了新一届的 AAAI/ACM SIGAI 博士论文奖,其中一篇专门分析强化学习抽象理论的论文《A Theory of Abstraction in Reinforcement Learning》获得了该奖项提名。论文作者 David Abel 博士毕业于布朗大学,他于近日将这篇博士论文上传到了 arXiv 上,共有 295 页。
在这篇论文中,作者提出了强化学习中蕴含的抽象理论。他首先指出执行抽象过程的函数所必备的三要素:
维护近似最优行为的表示;
它们应该被有效地学习和构建;
计划或学习时间不应该太长。
然后提出了一套新的算法和分析方案,阐明智能体如何根据这些要素学会抽象。总的来说,这些研究结果为发现和使用抽象提供了一些途径,从而把有效强化学习的复杂性降至最低。
为了论证本论文的思想,作者从三个方面阐述了哪些抽象在 RL 中有用,并将其研究成果高度概括为如下内容:
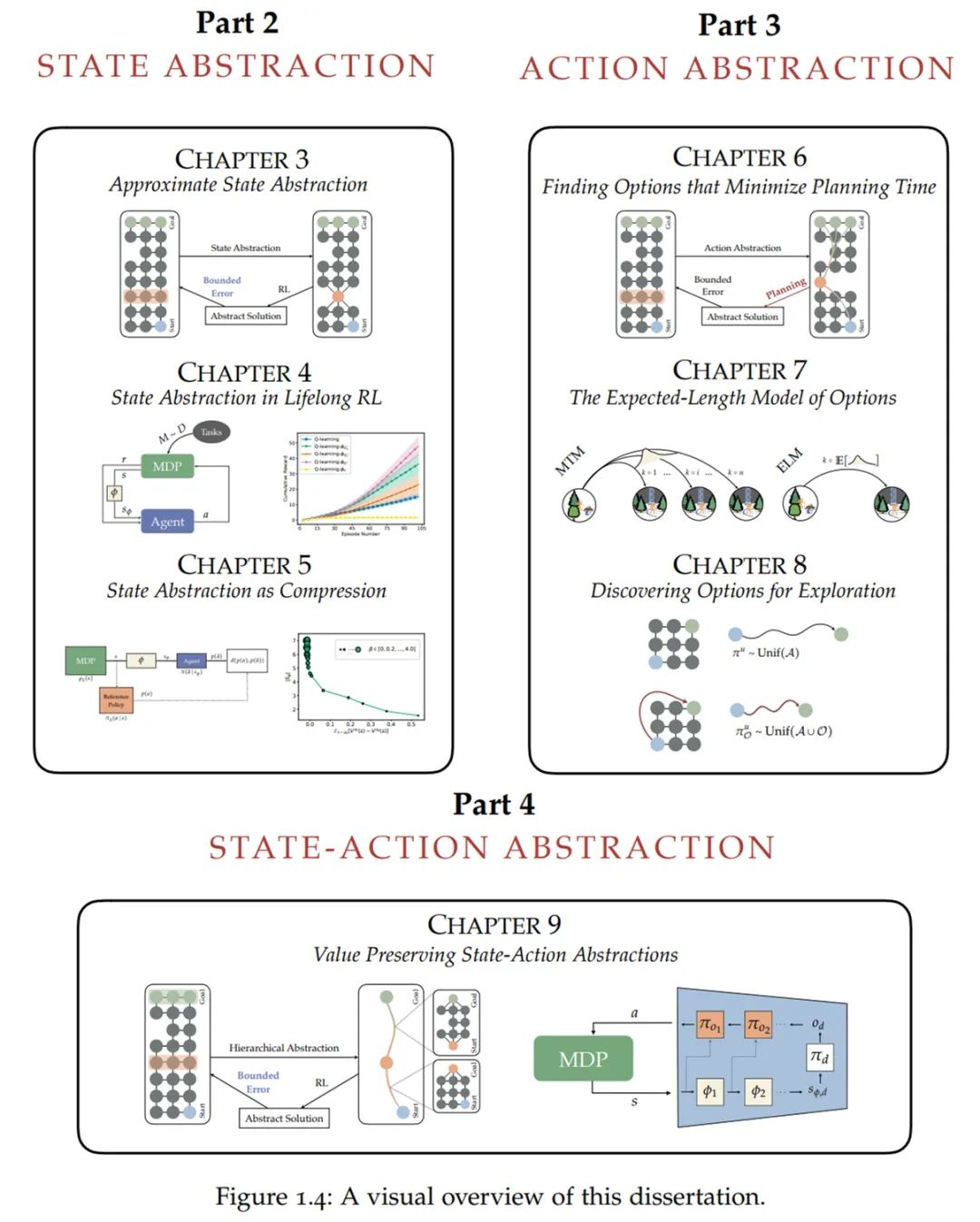
更具体地,作者通过以下四个部分对强化学习的抽象理论展开了探讨。下图为论文结构的可视化呈现。
推荐:
295 页博士论文探索强化学习抽象理论,获 AAAI/ACM SIGAI 博士论文奖提名。
论文 5:Weakly Supervised Object Localization as Domain Adaption
摘要:
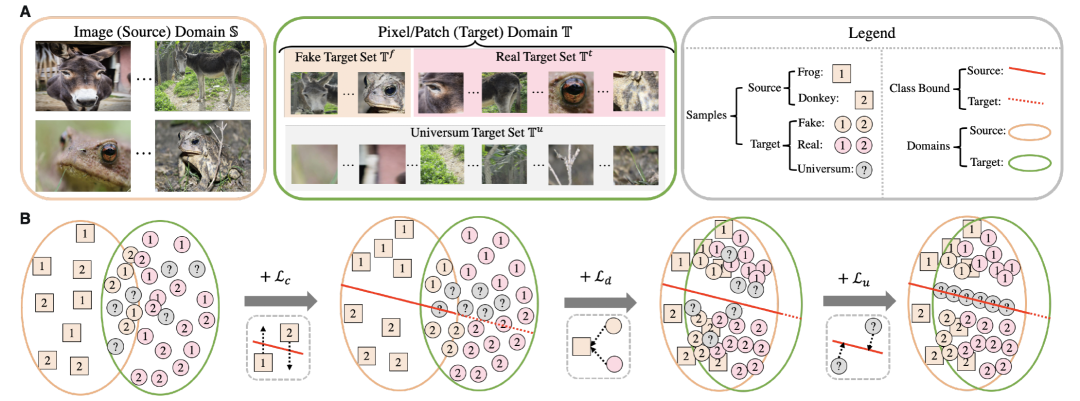
本文将基于 CAM 的弱监督物体定位过程看作是一个特殊的域自适应任务,即在保证在源图像级特征域上训练的分类器应用在目标像素域时仍具有良好的分类表现,从而使其更好的在测试过程中进行目标定位。从这一视角来看,我们可以很自然的将域自适应方法迁移到弱监督物体定位任务中,使得仅依据图像标签训练的模型可以更为精准的定位目标物体。
目前,这项研究已被 CVPR2022 接收,完整训练代码及模型均已开源。主要由北大分子影像 / 医学智能实验室朱磊和字节跳动佘琪参与讨论和开发,北大分子影像 / 医学智能实验室卢闫晔老师给予指导。
弱监督物体定位实际上可以看作是在图像特征域(源域 S)中依据图像级标签(源域金标 Y^s)完全监督地训练模型 e(∙),并在测试过程中将该模型作用于像素特征域(目标域 T)以获取物体定位热力图。总的来看,我们的方法希望在此过程中引入域自适应方法进行辅助,以拉近源域 S 与目标域 T 的特征分布,从而增强在模型 e(∙) 对于目标域 T 的分类效果,因此我们的损失函数可以表示为:
其中 L_c 为源域分类损失,而 L_a 则为域自适应损失。
由于弱监督定位中源域和目标域分别为图像域和像素域,我们所面临的域自适应任务具有一些独有的性质:①目标域样本与源域样本的数量并不平衡(目标域样本是源域的 N 倍,N 为图像像素数);②目标域中存在与源域标签不同的样本(背景像素不属于任何物体类别);③目标域样本与源域样本存在一定联系(图像特征由像素特征聚合而得到)。为了更好地考虑这三个特性,我们进而提出了一种域自适应定位损失(DAL Loss)作为 L_a (S,T) 以拉近图像域 S 与像素域 T 的特征分布。
图 2 - 弱监督定位中源域目标域的划分以及其在弱监督定位中的作用
推荐:
CVPR2022 | 利用域自适应思想,北大、字节跳动提出新型弱监督物体定位框架。
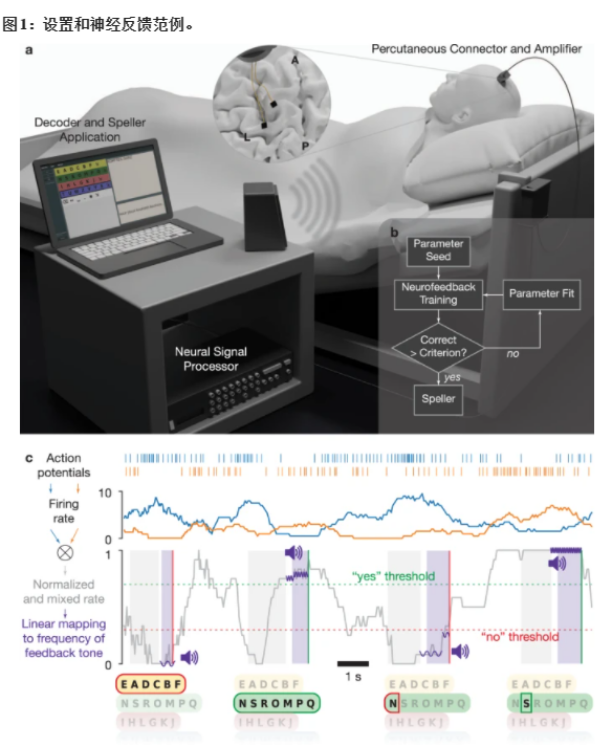
论文 6:Spelling interface using intracortical signals in a completely locked-in patient enabled via auditory neurofeedback training
摘要:
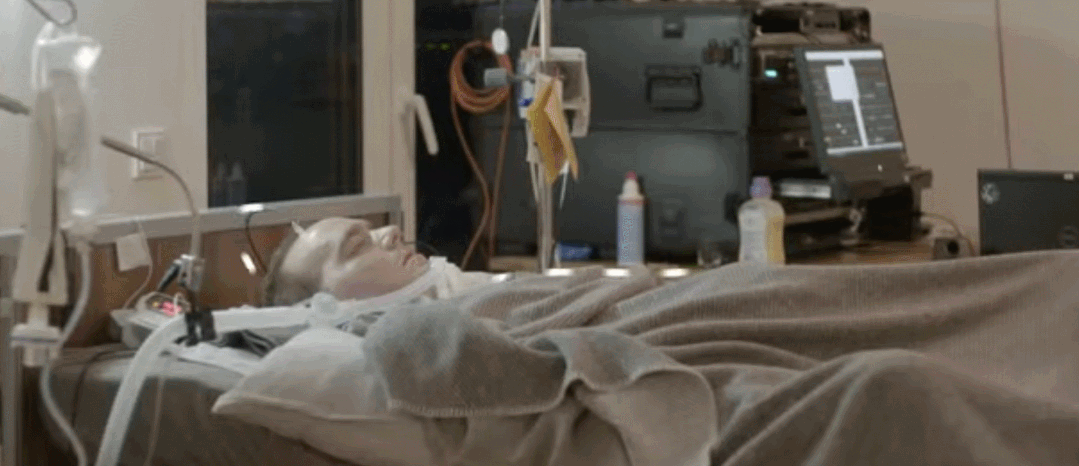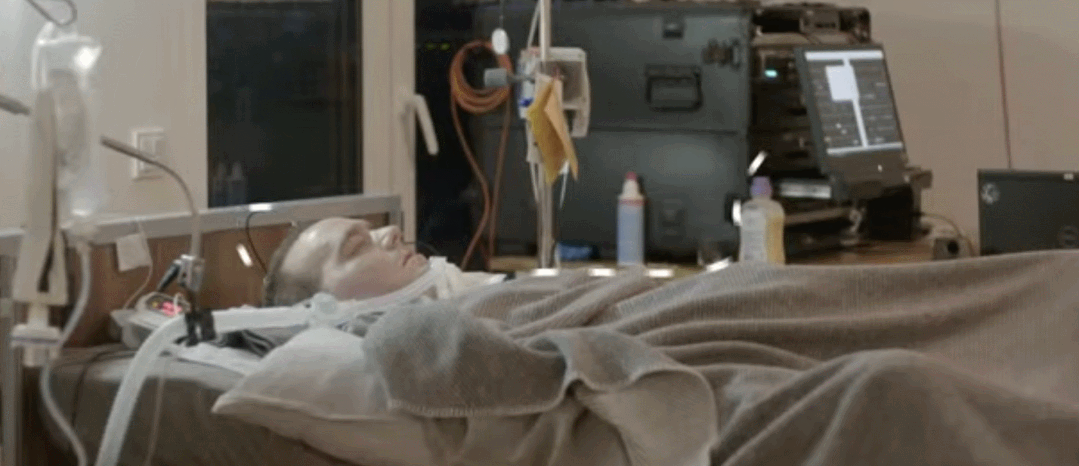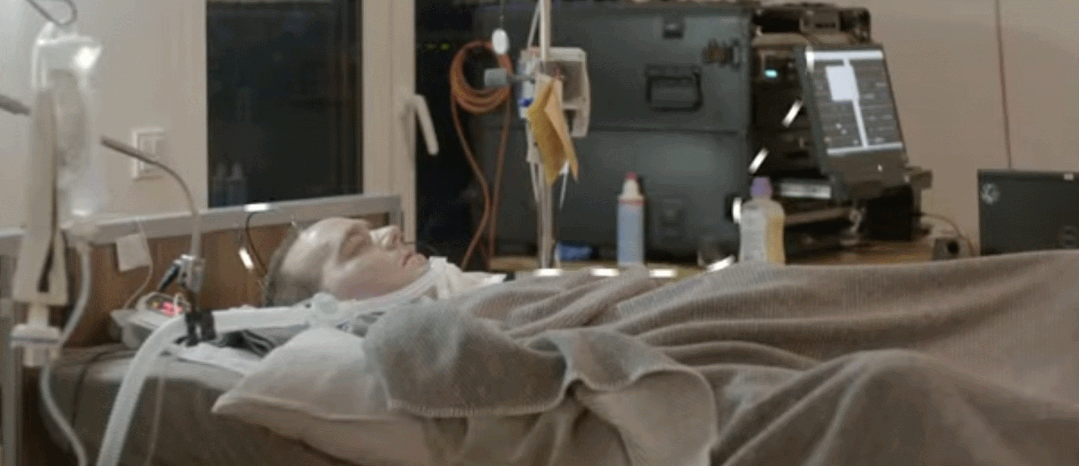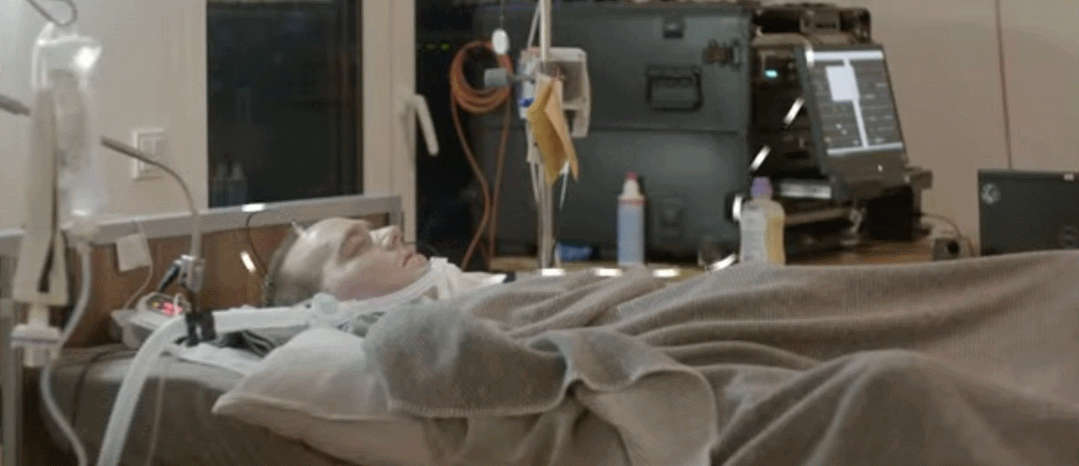
通常渐冻症患者可以使用眼动追踪摄像头来选择屏幕上的字母进行交流。当疾病发展到后期,患者可以通过细微的眼球运动来回答是或否的问题。但是完全失去肌肉控制能力的 ALS 患者,甚至无法控制他们的眼球运动和呼吸能力,也就无法用这种方式实现交流。图宾根大学的研究团队构建了一种可以读取大脑信号的植入设备,ALS 患者能够使用这种设备来进行交流。这项研究发表在《自然 - 通讯》上。
该研究通过手术将两个 3.2 毫米宽的方形「皮质内微电极阵列」植入负责运动的大脑皮层,即运动皮层。每个微电极阵列上带有数十根用于记录神经信号的微针,然后电线将信号馈送到一个与患者颅骨相连的连接器上。在外部,连接器上设有放大器,能够将信息数字化并将其发送到计算机。
当患者无法移动时,这种植入设备能够读取患者的大脑信号并记录其移动冲动。这些大脑信号被实时发送给计算机,计算机学会将这些运动尝试分类为「是」或「否」的响应,使得患者能够回答其他人询问的问题。此外,这套设备还可向患者大声朗读字母,患者可以对每个字母回答「是」或「否」以拼写出单词。
![]()
起初,这项研究经历了一些失败的实验,例如当研究者指导参与者尝试想象手、舌头或脚的运动时,设备无法检测到一致的反应。然后研究团队尝试采用下图所示的基于神经反馈的模式。这种模式通过将一个或多个通道的脉冲率度量 ( spike rate metric,SRM) 映射到听觉反馈音的频率,向患者提供神经活动的听觉反馈。参与者在实验开始后第 86 天第一次尝试调节音调,随后在第 98 天成功调节神经信号发射率,并首次将反馈频率与目标匹配。采用神经反馈策略,从第 106 天起,参与者能够调节神经激活率(firing rate),并且能够使用这种方法来选择和拼写字母。研究团队搜索反应最灵敏的神经元,然后探究每个神经元如何随着参与者的努力而发生变化,依此调整系统。
使用该系统大约 3 周后,他说出了一个可以理解的句子——请求护理人员调整他的位置。
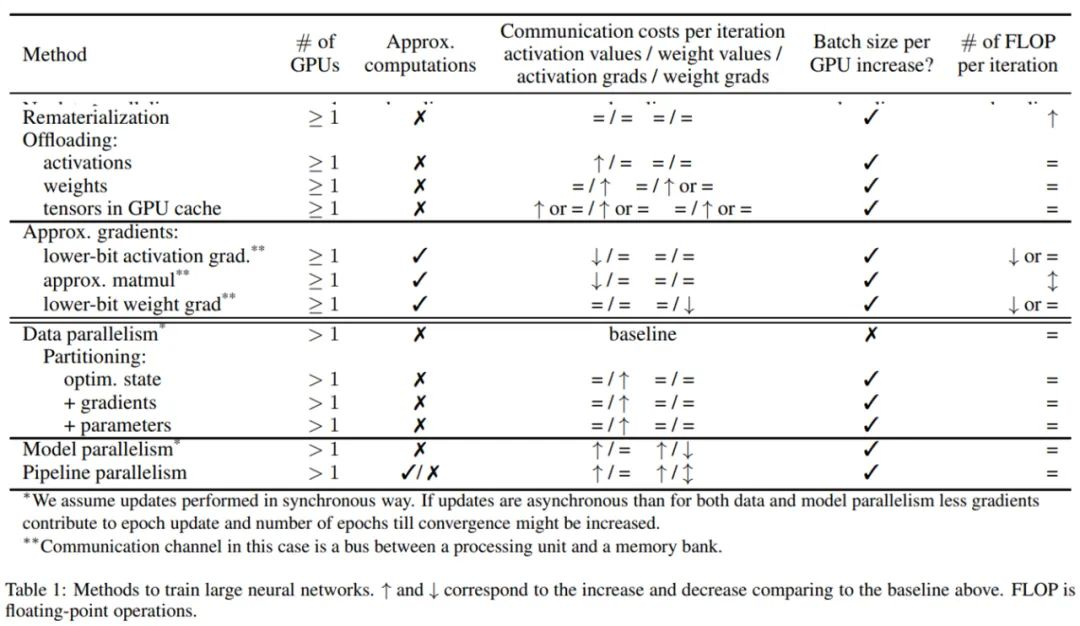
论文 7:Survey on Large Scale Neural Network Training
摘要:
俄罗斯斯科尔科沃科学技术研究所、法国里尔大学、波尔多大学、Inria 等科研机构联合发表了一篇论文《Survey on Large Scale Neural Network Training》,它试图解决的问题是:若给定模型和计算平台的情形下,如何训练才是最有效率的。为了使训练高效,其必须可行,最大程度地利用资源的计算能力,在并行情况下,它不能让信息传输成为瓶颈。训练的效率从根本上取决于计算内核在计算资源(CPU、TPU、GPU)上的有效实现以及 GPU 之间和不同内存之间通信的有效实现。
在这两种情况下,人们为优化计算内核的算术强度,及有效实现硬件网络上的通信做了很多工作。对于使用者来说,已存在强大的分析工具来识别硬件瓶颈,并可用于判定本调查中描述哪些策略可用于解决算术强度、内存和控制交换数据量的问题。
该综述研究涵盖了应对这些限制的通用技术。如果由于模型、优化器状态和激活不适合内存而无法先验执行计算,则可以使用内存交换计算(重新实现)或数据转移(激活和权重卸载)。我们还可以通过近似优化器状态和梯度(压缩、修剪、量化)来压缩内存使用。
并行方法(数据并行、模型并行、流水线模型并行)也可以将内存需求分布到多个算力资源上。如果计算的算力强度不足以充分利用 GPU 和 TPU,一般是因为 mini-batch 太小,那么上述技术也可以增加 mini-batch 的大小。最后,如果使用数据并行引起的通信开销昂贵到拖累计算速度,则可以使用其他形式的并行(模型并行、流水线模型并行),梯度压缩也可以限制数据交换的数量。在本次调查中,研究者解释了这些不同技术是如何工作的,其中描述了评估和比较所提出方法的文献,还分析了一些实施这些技术的框架。
下表 1 为文章讨论的不同技术及其对通信、内存和计算效率的影响。
研究者根据目的区分了以下方法:首先讨论减少 GPU 内存使用,随后考虑对不适合 GPU 的模型使用并行训练,最后讨论为训练存储在多个设备上的模型而开发的优化器的设计。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Improving Meta-learning for Low-resource Text Classification and Generation via Memory Imitation. (from Jian Sun)
2. Converse - A Tree-Based Modular Task-Oriented Dialogue System. (from Michael Jones, Richard Socher)
3. Text Transformations in Contrastive Self-Supervised Learning: A Review. (from Huan Liu)
4. IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks. (from Yan Zhang)
5. Domain Representative Keywords Selection: A Probabilistic Approach. (from Kevin Chen-Chuan Chang, ChengXiang Zhai)
6. Learning Relation-Specific Representations for Few-shot Knowledge Graph Completion. (from Xindong Wu)
7. Chat-Capsule: A Hierarchical Capsule for Dialog-level Emotion Analysis. (from Yao Wang, Minlie Huang)
8. DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization. (from Dan Roth)
9. Linearizing Transformer with Key-Value Memory Bank. (from Deng Cai)
10. Read Top News First: A Document Reordering Approach for Multi-Document News Summarization. (from Kathleen McKeown)
1. Rebalanced Siamese Contrastive Mining for Long-Tailed Recognition. (from Jian Sun, Jiaya Jia)
2. Real-time Object Detection for Streaming Perception. (from Jian Sun)
3. Subjective and Objective Analysis of Streamed Gaming Videos. (from Alan C. Bovik)
4. Vision Transformer with Convolutions Architecture Search. (from Witold Pedrycz)
5. Dataset Distillation by Matching Training Trajectories. (from Antonio Torralba, Alexei A. Efros, Jun-Yan Zhu)
6. Self-supervised Learning of Adversarial Example: Towards Good Generalizations for Deepfake Detection. (from Liang Chen)
7. Open-set Recognition via Augmentation-based Similarity Learning. (from Bing Liu)
8. Visual Prompt Tuning. (from Claire Cardie, Serge Belongie)
9. Adaptive Transformers for Robust Few-shot Cross-domain Face Anti-spoofing. (from Ming-Hsuan Yang)
10. CP2: Copy-Paste Contrastive Pretraining for Semantic Segmentation. (from Alan Yuille)
1. Deep Reinforcement Learning Guided Graph Neural Networks for Brain Network Analysis. (from Philip S. Yu)
2. Teachable Reinforcement Learning via Advice Distillation. (from Trevor Darrell, Pieter Abbeel)
3. MetaMorph: Learning Universal Controllers with Transformers. (from Li Fei-Fei)
4. AI Poincar\'{e} 2.0: Machine Learning Conservation Laws from Differential Equations. (from Max Tegmark)
5. AI system for fetal ultrasound in low-resource settings. (from Greg Corrado)
6. TCN Mapping Optimization for Ultra-Low Power Time-Series Edge Inference. (from Luca Benini)
7. Training Quantised Neural Networks with STE Variants: the Additive Noise Annealing Algorithm. (from Luca Benini)
8. Knowledge Removal in Sampling-based Bayesian Inference. (from Dacheng Tao)
9. On Supervised Feature Selection from High Dimensional Feature Spaces. (from C.-C. Jay Kuo)
10. Bellman Residual Orthogonalization for Offline Reinforcement Learning. (from Martin J. Wainwright)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com