悉尼大学陶大程:遗传对抗生成网络有效解决GAN两大痛点

新智元 AI World 2018 世界人工智能峰会
全程回顾
新智元于9月20日在北京国家会议中心举办AI WORLD 2018世界人工智能峰会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
爱奇艺
上午:https://www.iqiyi.com/v_19rr54cusk.html
下午:https://www.iqiyi.com/v_19rr54hels.html
新浪:http://video.sina.com.cn/l/p/1724373.html
新智元 AI WORLD 2018
演讲:陶大程(悉尼大学教授、澳大利亚科学院院士、优必选AI首席科学家)
编辑:大明
新智元 AI World 2018 世界人工智能峰会
全程回顾
新智元于9月20日在北京国家会议中心举办AI WORLD 2018世界人工智能峰会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
爱奇艺
上午:https://www.iqiyi.com/v_19rr54cusk.html
下午:https://www.iqiyi.com/v_19rr54hels.html
新浪:http://video.sina.com.cn/l/p/1724373.html
新智元 AI WORLD 2018
演讲:陶大程(悉尼大学教授、澳大利亚科学院院士、优必选AI首席科学家)
编辑:大明
【新智元导读】悉尼大学教授、澳大利亚科学院院士、优必选首席科学家陶大成博士指出,人类具有感知、推理、学习和行为四个方面的智能,AI的终极目标就是让机器具备和人类一样的智能。在9月20日的AI WORLD 2018 世界人工智能峰会上,陶大程博士介绍了他的团队在这四个方向上取得的重大进展。
震撼!AI WORLD 2018世界人工智能峰会开场视频
悉尼大学教授、澳大利亚科学院院士、优必选人工智能首席科学家陶大程博士在9月20日的AI WORLD 2018世界人工智能峰会上发表《AI破晓:机遇与挑战》的主题演讲。
陶大程表示,人工智能的目标是在机器上实现类似人的智能。人有四个方面的智能:Perceiving、Learning、Reasoning和Behaving。他的演讲围绕这四个方面展开。

Perceiving包含了很多方面:物体检测、目标跟踪、场景分割、关键点检测、人脸图像分析等等。但是高性能perceiving还依赖于高质量的数据输入。如果输入图像或者视频受到噪声、湍流、模糊、雾、低分辨率等因素的影响,就需要提升数据质量。
在learning方面,陶大程博士介绍了多视角学习、多标签学习、adversarial domain generalisation、tag disentangled GAN等等。尤其是遗传对抗生成网络(Evolutionary GAN)有效的解决了传统GAN网络学习的两个痛点:
(1)训练不稳定性。
(2)模型塌缩。这个工作也被麻省理工学院技术评论(MIT Technology Review)评选为热点论文(The Best of the Physics arXiv)。
另外受到信息论中数据处理不等式的启发,陶博士和他的学生们在理论上解释了深度学习中两个备受关注的问题:(1)为什么模型复杂度非常高的深度神经网络,不会发生过拟合?(2)深度神经网络是越深越好吗?
最后,陶大程博士介绍了优必选悉尼大学人工智能研究院在reasoning和behaving方面的一些进展。他的团队最近在visual question answering(VQA,看图回答问题)和visual dialog(看图对话)的国际比赛中都取得了非常不错的成绩。
目前陶大程博士的团队努力在人形机器人上实现示教学习(imitation learning),希望不久的将来能够实现:机器人通过摄像机来理解人的行为,模仿人的行为,并且最终有效的和人进行互动。
以下是新智元整理的陶大成教授的演讲内容:
非常感谢新智元邀请我来跟大家分享一下,过去这两年我们在人工智能领域里做的一些工作。

首先请大家看这张照片。我这里想问大家一个问题,这张照片中有多少人?回答这个问题不难,但是要花很多时间。我们如果一个个人的去数,那么大约用一个小时的时间,我们可以知道这里有差不多900多个人。

如果用我们的人脸检测技术,在有GPU显卡的台式机上,只用三秒钟就可以得到差不多的结果。这看起来是个很简单的任务,但对于计算机来说并不总是那么一帆风顺。2017年,我们的算法大概能检测七百多张人脸,然后到八百多个,到现在九百多,接近人的效果。另外我们发现,用计算机检测到的人脸实际上还有助于人去发现一些人刚开始没有看到的人脸。这也从一特别的角度说明了,人工智能能够扩展人的智能。

什么是人工智能?人工智能就是机器所展示出来的智能,所以可以叫做“机器智能”,以区别人所展现出来的智能。人有四个方面的智能:Perceiving、Learning、Reasoning、以及Behaving。人工智能的目标就是让机器实现、模拟人的智能。我们期待有一天,机器也能够像人一样去感知世界,去学习、推理,去做出相应的一些反应。因此,我们需要让人工智能具有这四个方面的能力。

这个视频展示了我们在人工智能领域里面的一些核心技术,包括目标检测、(单、多)目标跟踪、目标分割、特征点检测、人体姿态估计、表情分析、年龄估计、单摄像机深度估计等。

为什么今天大家都在谈人工智能?因为我们有大数据,有超强的计算服务器,因此相对于很久之前,我们现在有能力有效地去训练超大规模的模型。虽然很久之前,多层神经网络已经出现,但是受制于数据和计算能力,一直没有能够得到很好的推广。更重要的是,我们目前有大量的来自产业界、学术界、以及政府部门的实际需求。这些真正促成了今天的人工智能的再一次爆发。产业界的迫切需求也极大地推动了学术界对人工智能的投入。
今天,我讲介绍一下我们在perceiving(感知)、learning(学习)、reasoning(推理)和 behaving(行为)四个方面的进展。

物体检测是perceiving中的一项基本任务。现有的两阶段目标检测器取得了非常好的效果。首先生成区域候选框,然后对这些候选框进行调整。调整过程会更新后续框的坐标并预测物体的类别。但是,不准确的候选框有可能会导致不正确的检测结果。
为了解决这个问题,我们提出了基于上下文的调整算法。具体的讲,我们发现对于一个检测框,它周围的检测框常常提供了对于要检测物体的补充性信息。
因此,我们尝试从周围检测框提取有用的上下文信息用来改进现有的调整算法。在我们提出的方法里,我们会基于一个加权过程来融合提取出来的上下文信息。最后,利用融合后的上下文信息以及相应的视觉特征,我们提出的基于上下文的候选框调整算法能实质性地改进现有的调整算法。
举个例子,如图所示,其中一个鹤的候选框都不是很理想:蓝色、黄色、红色三个框,每一个框都只包含了鹤的一部分信息。通过我们提出的基于上下文的候选框调整算法能有效的把包含鹤的不同的部分的候选框的信息整合起来,形成一个完整的候选框。
有了完整的候选框,可以有效的提升检测率。

目标跟踪是perceiving中的另一个非常基本的任务。单目标跟踪的困难来自于物体在运动过程中,形态由于geometry/photometry、camera viewpoint和illumination的变化、以及部分遮挡会发生强烈的变化。多目标跟踪更为困难,除了单目标跟踪遇到的困难,还需要区分物体的数量,以及不同的id。
因此在非受控的环境中做长序列的跟踪非常困难。由于深度学习在目标跟踪中的使用,目前tracker的性能已经得到了很大的提升。这主要是由于深度学习能够有效的给出被跟踪物体的本源表征,因此对于各种变化、遮挡都有很好的对抗能力。这个篮球球场中的多球员跟踪就是很好的例子。

单目深度估计是一个病态问题,因此极具挑战性。这个任务期望从单张场景图中还原出像素级的深度值,且在3D场景几何理解中扮演着关键角色。为什么这是一个病态问题呢?举个例子,假设三维空间中有一条线,然后我们可以把它投射到一个平面上。在投射的平面上,我们可以看到一条直线,但是我们无法确认,在原始的三维空间中,这条线是直线还是曲线?可是实际中,我们却可以根据图像的信息来估计深度信息。
比如这张图中,人的身高在原始图像中,大约是三厘米,但是你绝对不会认为这个人的身高在三维实际空间中就是三里面。根据常识,我们都知道,成年男子身高大概在175到180厘米左右。
根据简单的几何变换,我们就能够估计到这个人到摄像机的距离。图像中还有很多的信息能够帮助我们估计像素的深度信息,比如阴影、色彩的变化、layout、地面等等。关键的问题是,我们应该如何设计特征,然后用合理的统计模型来估计每一个像素的深度。
很久之前,研究人员用handcrafted特征结合MRF(马尔科夫随机场)来完成这个任务。虽然传统的MRF模型的预测效果不令人满意,但是已经存在的结果告诉大家这个问题不是完全不可解决的。
最近的方法通过探索深度神经网络(DCNN)的多层次情景语义信息在这个问题上取得了显著的进步。然而,这些方法预测出的深度值任然是非常不准确的。
几个可能的原因是:(1)由于深度分布的极端复杂性,在标准的回归范例下学习深度分布是很困难的。(2)之前的工作在建模时都忽略了深度值之间的有序关系。(3)图像级和多尺度信息目前还没有被充分发掘。
受这些现象的启发,我们首先将深度估计问题转化到离散范例上来解决,其次通过提出一个顺序回归约束以此为深度预测引入排序机制,最后设计一个有效的多尺度深度网络来实现更好的情景语义信息学习。我们的模型(DORN)不仅在四个非常有挑战的数据集(KITTI, ScanNet, Make3D 和 NYU Depth v2)上的效果远超同行,并且赢得了 Robust Vision Challenge 2018深度估计项目的第一名。

预测一组语义关键点,例如人类身体关节或鸟类部位,是图像理解领域中重要的一项技术 。物体的关键点助于对齐对象并揭示它们之间的细微差别,同时也是计算机领会人类姿态的一项关键技术。尽管这项技术近年来取得了重大进展,但由于物体外观差异大,姿势变化和遮挡等情况,关键点预测仍然是一项重大挑战。
目前基于CNN的关键点定位方法使用置信度图监督关键点检测器, 但由于不同图片中关键点的检测难易程度不同,使用同等程度置信度图可能会不利于关键点检测器的学习。
为了解决关键点定位的鲁棒性问题,我们提出了一个粗细监督网络(CFN)深层卷积网络的方法。该方法使用全卷积网络,利用几个不同深度的分支来获得分层特征表示。并根据其感受野不同,使用粗细不同的监督信息。最后联合所有分层特征信息来实现目标关键点的精确定位。我们通过鸟类部位定位和人体姿态估计的不同任务实验证明了该方法的有效性和通用性。

要想成功的完成刚才说的这些perceiving的任务,我们都需要假设我们所获取到的图像都是高质量的。但是在实际问题中,我们获取到的图象有可能会受到一些影响,导致数据质量比较差。因此我们要解决图像质量评估,根据图像质量评估的结果,我们还要有有效的模型对图像的质量进行提升,比如denoise、deblur、去除介质湍流的影响、提升低分辨率图像的分辨率、去雾,等等。
最近很多人都有一种感觉:深度学习一统天下。要解决实际问题,就是想办法把不同的网络层堆积起来、把网络不断加深,然后调参就好了。事实上,没有这么简单。要有效的解决实际问题,不仅我们要理解深度学习、知道该如何有效的调参,还有熟悉传统的统计机器学习、经典的计算机视觉,更要对问题有深刻的理解,知道如何构建有效的学习模型,当然是深度的学习模型。
在learning这个方向上,我们也做了很多工作:快速矩阵分解、多视角学习、多任务学习、多标签学习、迁移学习、有标签噪声的学习、生成对抗网络、深度学习理论,等等。时间原因,我简单的介绍一下,我们最近在多视角学习、生成对抗网络和深度学习理论上的一些工作。
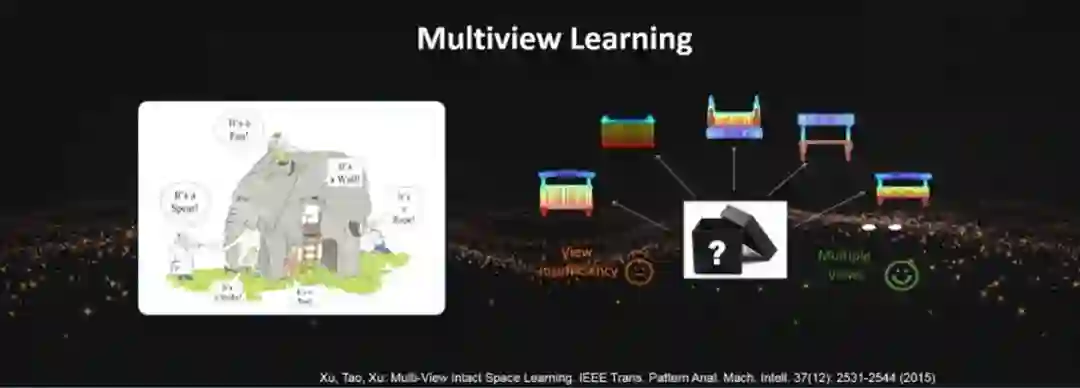
大家都知道盲人摸象的故事,实际上我们做决策的时候,跟盲人是一样的,因为我们所获取到的信息也是不完整的。那么我们在做觉得时候,也就是根据已有的信息作出的最优策略。因此,对于同样的事情,每一个人所作出的决定可能也不相同。
多视角学习对于现今的智能系统非常重要,这是因为智能系统中都安装了大量的传感器,比如,现在的无人车安装了激光雷达、毫米波雷达、摄像机、IMU等等。每个传感器都只能够感知环境中的部分信息,那么我们就需要把不同的传感的信息融合起来,帮助我们做最后的决策。
假设存在一个oracle space,那么每个传感器就可以被建模成对oracle space的一个线性或者非线形投影。如果我们有大量的传感器,那么我们就能够获取大量的投影信息。我们可以证明,如果说我们有足够多的不同的投影信息,我们就能够以非常高的概率去重构这个oracle space。有了这个oracle space,我们就可以有效的做决策了。

请大家看一下最左边的这张图像。你第一眼看到了什么?大多说人一定会说是船。然后你还会注意到船上有人。对不对?这个现象提示我们,这样的顺序信息对于我们进行多标签学习会非常有帮助。通过增强学习,我们可以有效的学习这个顺序,来提升增强学习的效率。
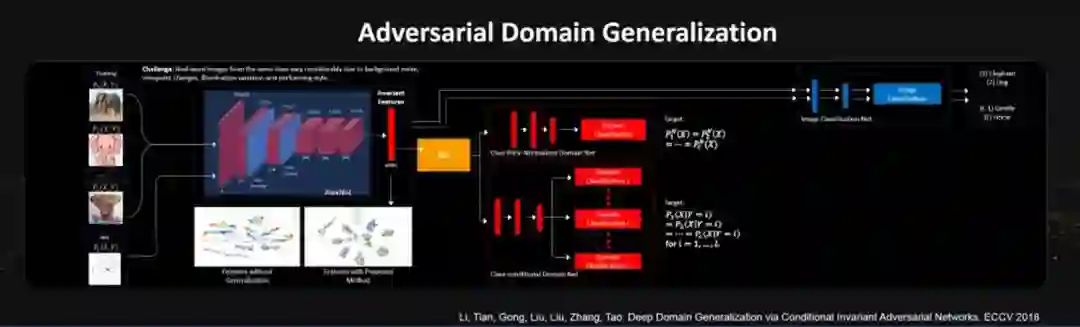
我们今天所面临的学习问题可能是这样的一个情况:训练数据和测试数据来自不同的传感器或者信息域。这就是domain generalization要解决的问题。因为训练数据和测试数据来自不同的域,我们就需要找寻一些特征:这些特征在训练数据上和测试数据上,对于完成我们的规定任务来说都是有效的。
人可以很轻松的做到这一点:我儿子3岁的时候,我给他看过长颈鹿的卡通画片。当我带他去动物园的时候,他可能很轻松的认出真正的长颈鹿。可是在这之前,他从来没有见过实际场景中的长颈鹿。我们当然希望计算机也具备类似的能力。这里我们利用GAN网络(对抗生成网络)能够有效地学习这样的不变特征。
我们提出了一个端到端的条件对抗域自适应深度学习模型来学习域不变的特征,该模型同时衡量分布P(Y)和条件概率分布P(X|Y)的不变性。该网络框架包括了四个部分。第一部分AlexNet用来学习域不变的特征。第二部分是图像分类网络,用来保证学习的特征具有良好的类别区分性。
特征的域不变性质利用类别先验归一化域分类网络和类别条件域分类网络保证。其中类别先验归一化域分类网络用来匹配不同域的类别先验归一化分布,该网络的主要目的是消除不同域之间的变化。其次,类别条件域分类网络用来保证对于每一类的分布匹配。这样就能够保证不同域的联合概率分布是匹配的。在不同标准数据集上得到的实验结果证明了我们方法的有效性,并且要比现有方法有显著的提高。

最近大家开始关注学习的可解释性。我们用GAN网络可以学到特征来生成我们需要的数据。可是这些特征的含义是什么?我们并不清楚。
通过模仿人类理解世界的方式,我们希望计算机能够从这个复杂的世界中学习到抽象的概念,并根据这些概念创造新的东西。因此,我们需要计算机能够从真实世界图像中提取到可分解的特征,例如照片中人物的身份,拍摄角度,光照条件等等。这个就是tag disentanglement。有了可分解的特征,我们也能很好的解释我们学习到的特征到底是什么物理含义。
我们提出了一个新的框架(TD-GAN),用于从单个输入图像中提取可分解的特征,并通过调整所学特征来重新渲染图像。从某种程度上说,TD-GAN提供了一个可以理解现实世界中图像的深度学习框架。
网络所学习到的可分解的特征,实际上对应于图像中所描述主体的不同属性。与人类理解世界的方式相似,学习可分解的特征有助于机器解释并重构现实世界的图像。因此,TD-GAN能够根据用户指定的信息合成高质量的输出图像。
TD-GAN可应用于(1)数据增强,即通过合成新的图像以用于其他深度学习算法的训练与测试,(2)生成给定对象连续姿态的图像,以用于三维模型重建,以及(3)通过解析,概括来增强现有创作,并创造充满想象力的新绘画。

学习和操控现实世界数据(如图像)的概率分布是统计和机器学习的主要目标之一。而近些年提出的深度生成对抗网络(GAN)就是学习复杂数据概率概率分布的常用方法。
生成对抗网络在许多生成相关的任务上取得了令人信服的表现,例如图像生成,图像“翻译”和风格变换。但是,现有算法仍面临许多训练困难。例如,大多数GAN需要仔细平衡生成器和判别器之间的能力。不适合的参数设置会降低GAN的性能,甚至难以产生任何合理的输出。
在过去相当长的一段时间内,很多研究人员都在研究不同的损失函数对于GAN的影响,(并且大家认为不同的损失函数具有不同的优势和劣势,并可能导致不同的训练问题)。因此很多不同的损失函数被引入到了GAN的训练学习中,比如minimax、least squares等等,来提升GAN的性能。
对于不同的任务、不同的数据,不同的损失函数都取得了一定的效果。后来Google的研究人员通过大量实验发现,虽然不同的损失函数在不同的任务上或数据上或许会有不同的表现,但是总体平均的效果却相差不多。
这就告诉我们:现有生成对抗网络的损失函数具有不同的优点和缺点,其预定义的对抗优化策略可能导致生成对抗网络训练时的不稳定。受自然演化启发,我们设计了一个用于训练生成对抗网络的演化框架。在每次迭代期间,生成器经历不同的突变以产生多种后代。然后,给定当前学习到的判别器,我们评估由更新的后代产生样本的质量和多样性。最后,根据“适者生存”的原则,去除表现不佳的后代,保留剩余的表现良好的发生器并用于进一步对抗训练。
基于的进化模型的生成对抗网络克服了个体对抗训练方法所存在的固有局限性,极大的稳定了生成对抗网络的训练过程病提升了生成效果。实验证明,所提出的E-GAN实现了令人信服的图像生成性能,并减少了现有GAN固有的训练问题。
这个工作,被MIT Technology Review评为热点论文(one of “The Best of the PhysicsarXiv”)。

我们都知道,深度神经网络有一个特点,就是参数空间大,模型复杂度高。传统的统计学习理论认为,参数空间越大,模型复杂度越高,那么它对训练数据的拟合能力就越强,但是泛化能力会变得越差。
Universal approximation theorem已经证明了传统的、有一个隐层的,多层感知机能够拟合任何数据。举个例子,这样的模型完全可以拟合ImageNet这样的数据。如果这样,为什么我们还要不断的增加网络的深度,从最初的六层的AlexNet,到后来的152层的ResNet,甚至还有人用几百层的网络?因为我们都知道,这个单隐层的模型只有机会取得很小的训练误差,但是泛化能力却非常差。也就是说,测试效果并不好。
对于一个机器学习模型,如果它的训练误差远小于测试误差,那么它就发生了过拟合。在现有的统计学习理论框架下,对于神经网络,有两个尚未解决的问题:首先,为什么模型复杂度非常高的深度神经网络,不会发生过拟合?其次,深度神经网络是越深越好吗?
利用信息论中的信息处理不等式,我们最近的工作得到了这样一个有趣的结论:深度神经网络的泛化误差会随着层数的增加而指数衰减。这样的结论告诉我们,在保证训练误差足够小的前提下,原则上网络是越深越好。
关于reasoning和behaving,我们也做了一些工作。这里我提一下模仿学习、视觉问题回答和视觉对话。
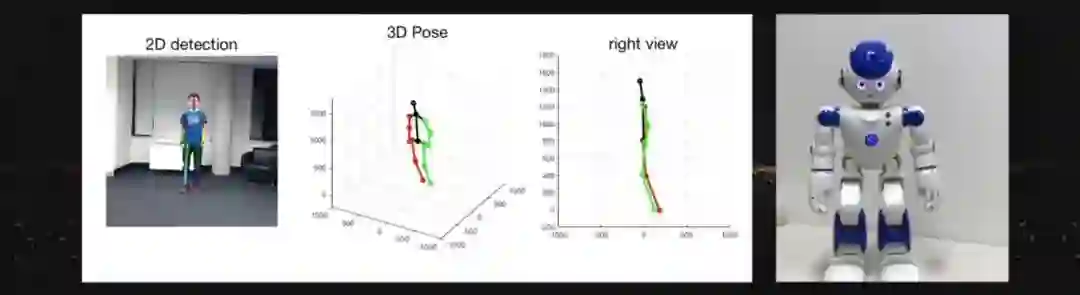
目前任何机器人主要的交互方式是通过设定的程序和参数。但是目前的机器人已经安装了摄像机,那么我们希望不愿的将来,机器人可以通过观察人的动作、模仿人的动作,来达到学习的效果。

看图问答旨在以问答的交互方式解决视觉内容细粒度内容理解。给定任意图片,用户针对图像内容使用自然语言进行提问,算法提供准确的自然语言的答案。一个典型的视觉问答框架主要包含视觉特征细粒度表达、视觉注意力学习、多模态特征细粒度融合三个模块。
针对三个关键模块,我们都提出了更为有效的方式。这样的模型对于机器人和人的交互,也是非常重要的。在视觉问答的标准数据集VQA v2的实时排行榜,我们的方法取得了目前业界最好水平。

比看图问答更为复杂的一个相关任务是visual dialog(看图对话)。与看图问答任务相比,看图对话有两个挑战:第一是对话历史问题,也就是上下文指代关系。第二是如何区分相似的答案。我们在最近的比赛中有效的考虑了这两个问题,并且取得了很好的效果。
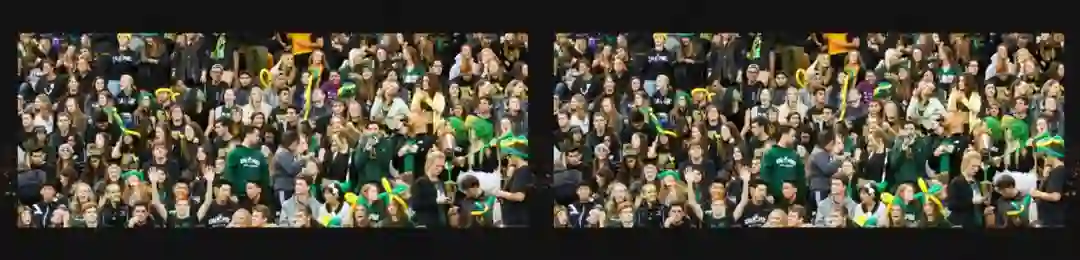
最后,我请大家看一下这张照片。现在,我不问你这里有多少人了,而是问你这些人在干什么。我想,你瞬间就可以告诉我,这些人在看比赛。这张照片和演讲一开始的那张照片的内容是完全不一样的。那张照片就是大家在照集体照。可是对于计算机来说,要回答出这两张照片有什么不同还很困难,至少需要堆积大量的数据进行训练,才能够去回答这样非常简单的问题。

这样的智能是我们需要的人工智能吗?显然不是,我们希望未来我们的计算机能够在很多方面跟人具有共同的特性。因此,我们要让计算机有更好的推理和行为能力。
谢谢大家!
新智元AI WORLD 2018
世界人工智能峰会全程回顾
新智元于9月20日在北京国家会议中心举办AI WORLD 2018世界人工智能峰会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
全程回顾新智元 AI World 2018 世界人工智能峰会盛况:
爱奇艺
上午:https://www.iqiyi.com/v_19rr54cusk.html
下午:https://www.iqiyi.com/v_19rr54hels.html
新浪:http://video.sina.com.cn/l/p/1724373.html




