一文读懂最近流行的CNN架构(附学习资料)

来源: 机器学习算法全栈工程师
本文长度为4259字,建议阅读6分钟
本文为你介绍CNN架构,包括ResNet, AlexNet, VGG, Inception。
本文翻译自ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks,原作者保留版权。
http://cv-tricks.com/cnn/understand-resnet-alexnet-vgg-inception/
卷积神经网络(CNN)在视觉识别任务上的表现令人称奇。好的CNN网络是带有上百万参数和许多隐含层的“庞然怪物”。事实上,一个不好的经验规则是:网络越深,效果越好。
AlexNet,VGG,Inception和ResNet是最近一些流行的CNN网络。
为什么这些网络表现如此之好?它们是如何设计出来的?为什么它们设计成那样的结构?回答这些问题并不简单,但是这里我们试着去探讨上面的一些问题。
网络结构设计是一个复杂的过程,需要花点时间去学习,甚至更长时间去自己动手实验。首先,我们先来讨论一个基本问题。
1. 为什么CNN模型战胜了传统的计算机视觉方法?

图像分类指的是给定一个图片将其分类成预先定义好的几个类别之一。图像分类的传统流程涉及两个模块:特征提取和分类
特征提取指的是从原始像素点中提取更高级的特征,这些特征能捕捉到各个类别间的区别。这种特征提取是使用无监督方式,从像素点中提取信息时没有用到图像的类别标签。
常用的传统特征包括GIST, HOG, SIFT, LBP等。特征提取之后,使用图像的这些特征与其对应的类别标签训练一个分类模型。常用的分类模型有SVM,LR,随机森林及决策树等。
上面流程的一大问题是:特征提取不能根据图像和其标签进行调整。如果选择的特征缺乏一定的代表性来区分各个类别,模型的准确性就大打折扣,无论你采用什么样的分类策略。
采用传统的流程,目前的一个比较好的方法是使用多种特征提取器,然后组合它们得到一种更好的特征。
但是这需要很多启发式规则和人力来根据领域不同来调整参数使得达到一个很好的准确度,这里说的是要接近人类水平。
这也就是为什么采用传统的计算机视觉技术需要花费多年时间才能打造一个好的计算机视觉系统(如OCR,人脸验证,图像识别,物体检测等),这些系统在实际应用中可以处理各种各样的数据。
有一次,我们用了6周时间为一家公司打造了一个CNN模型,其效果更好,采用传统的计算机视觉技术要达到这样的效果要花费一年时间。
传统流程的另外一个问题是:它与人类学习识别物体的过程是完全不一样的。自从出生之初,一个孩子就可以感知周围环境,随着他的成长,他接触更多的数据,从而学会了识别物体。
这是深度学习背后的哲学,其中并没有建立硬编码的特征提取器。它将特征提取和分类两个模块集成一个系统,通过识别图像的特征来进行提取并基于有标签数据进行分类。
这样的集成系统就是多层感知机,即有多层神经元密集连接而成的神经网络。
一个经典的深度网络包含很多参数,由于缺乏足够的训练样本,基本不可能训练出一个不过拟合的模型。
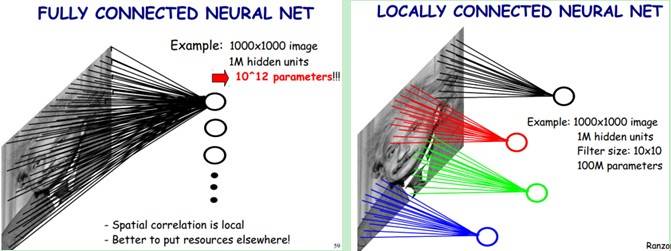
但是对于CNN模型,从头开始训练一个网络时你可以使用一个很大的数据集如ImageNet。这背后的原因是CNN模型的两个特点:神经元间的权重共享和卷积层之间的稀疏连接。
这可以从下图中看到。在卷积层,某一个层的神经元只是和输入层中的神经元局部连接,而且卷积核的参数是在整个2-D特征图上是共享的
2. 为了理解CNN背后的设计哲学,你可能会问:其目标是什么?
准确度
如果你在搭建一个智能系统,最重要的当然是要尽可能地准确。公平地来说,准确度不仅取决于网路,也取决于训练样本数量。因此,CNN模型一般在一个标准数据集ImageNet上做对比。
ImageNet项目仍然在继续改进,目前已经有包含21841类的14,197,122个图片。自从2010年,每年都会举行ImageNet图像识别竞赛,比赛会提供从ImageNet数据集中抽取的属于1000类的120万张图片。
每个网络架构都是在这120万张图片上测试其在1000类上的准确度。
计算量
大部分的CNN模型都需要很大的内存和计算量,特别是在训练过程。因此,计算量会成为一个重要的关注点。同样地,如果你想部署在移动端,训练得到的最终模型大小也需要特别考虑。
你可以想象到,为了得到更好的准确度你需要一个计算更密集的网络。因此,准确度和计算量需要折中考虑。
除了上面两个因素,还有其他需要考虑的因素,如训练的容易度,模型的泛化能力等。下面按照提出时间介绍一些最流行的CNN架构,可以看到它们准确度越来越高。
3. AlexNet
AlexNet
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
是一个较早应用在ImageNet上的深度网络,其准确度相比传统方法有一个很大的提升。它首先是5个卷积层,然后紧跟着是3个全连接层,如下图所示:

Alex Krizhevs提出的AlexNet采用了ReLU激活函数,而不像传统神经网络早期所采用的Tanh或Sigmoid激活函数,ReLU数学表达为:
f(x)=max(0, x)
ReLU相比Sigmoid的优势是其训练速度更快,因为Sigmoid的导数在稳定区会非常小,从而权重基本上不再更新。这就是梯度消失问题。因此AlexNet在卷积层和全连接层后面都使用了ReLU。

AlexNet的另外一个特点是其通过在每个全连接层后面加上Dropout层减少了模型的过拟合问题。Dropout层以一定的概率随机地关闭当前层中神经元激活值,如下图所示:

为什么Dropout有效?
Dropout背后理念和集成模型很相似。在Drpout层,不同的神经元组合被关闭,这代表了一种不同的结构,所有这些不同的结构使用一个的子数据集并行地带权重训练,而权重总和为1。
如果Dropout层有 n 个神经元,那么会形成2^n个不同的子结构。在预测时,相当于集成这些模型并取均值。这种结构化的模型正则化技术有利于避免过拟合。
Dropout有效的另外一个视点是:由于神经元是随机选择的,所以可以减少神经元之间的相互依赖,从而确保提取出相互独立的重要特征。
4. VGG16
VGG16
https://arxiv.org/abs/1409.1556
是牛津大学VGG组提出的。VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,5x5)。
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
比如,3个步长为1的 3x3 卷积核连续作用在一个大小为7的感受野,其参数总量为 3*(9C^2), 如果直接使用7x7卷积核,其参数总量为 49C^2,这里 C 指的是输入和输出的通道数。
而且3x3卷积核有利于更好地保持图像性质。VGG网络的架构如下表所示:

可以看到VGG-D,其使用了一种块结构:多次重复使用同一大小的卷积核来提取更复杂和更具有表达性的特征。这种块结构( blocks/modules)在VGG之后被广泛采用。
VGG卷积层之后是3个全连接层。网络的通道数从较小的64开始,然后每经过一个下采样或者池化层成倍地增加,当然特征图大小成倍地减小。最终其在ImageNet上的Top-5准确度为92.3%。
5. GoogLeNet / Inception
尽管VGG可以在ImageNet上表现很好,但是将其部署在一个适度大小的GPU上是困难的,因为需要VGG在内存和时间上的计算要求很高。由于卷积层的通道数过大,VGG并不高效。
比如,一个3x3的卷积核,如果其输入和输出的通道数均为512,那么需要的计算量为9x512x512。
在卷积操作中,输出特征图上某一个位置,其是与所有的输入特征图是相连的,这是一种密集连接结构。
GoogLeNet
https://arxiv.org/pdf/1409.4842v1.pdf
基于这样的理念:在深度网路中大部分的激活值是不必要的(为0),或者由于相关性是冗余。因此,最高效的深度网路架构应该是激活值之间是稀疏连接的,这意味着512个输出特征图是没有必要与所有的512输入特征图相连。
存在一些技术可以对网络进行剪枝来得到稀疏权重或者连接。但是稀疏卷积核的乘法在BLAS和CuBlas中并没有优化,这反而造成稀疏连接结构比密集结构更慢。
据此,GoogLeNet设计了一种称为inception的模块,这个模块使用密集结构来近似一个稀疏的CNN,如下图所示。
前面说过,只有很少一部分神经元是真正有效的,所以一种特定大小的卷积核数量设置得非常小。同时,GoogLeNet使用了不同大小的卷积核来抓取不同大小的感受野。
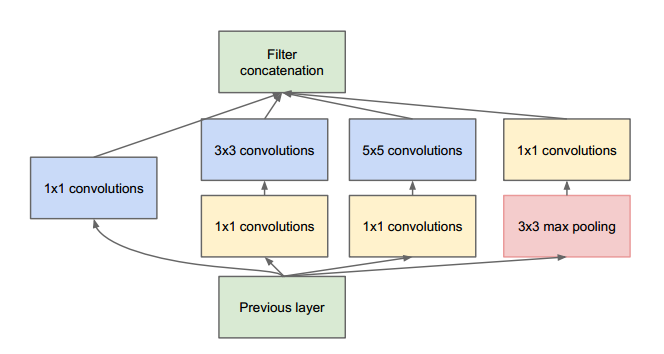
Inception模块的另外一个特点是使用了一中瓶颈层(实际上就是1x1卷积)来降低计算量:
这里假定Inception模块的输入为192个通道,它使用128个3x3卷积核和32个5x5卷积核。5x5卷积的计算量为25x32x192,但是随着网络变深,网络的通道数和卷积核数会增加,此时计算量就暴涨了。为了避免这个问题,在使用较大卷积核之前,先去降低输入的通道数。
所以,Inception模块中,输入首先送入只有16个卷积核的1x1层卷积层,然后再送给5x5卷积层。这样整体计算量会减少为16x192+25x32x16。这种设计允许网络可以使用更大的通道数。
(译者注:之所以称1x1卷积层为瓶颈层,你可以想象一下一个1x1卷积层拥有最少的通道数,这在Inception模块中就像一个瓶子的最窄处)
GoogLeNet的另外一个特殊设计是最后的卷积层后使用全局均值池化层替换了全连接层,所谓全局池化就是在整个2D特征图上取均值。
这大大减少了模型的总参数量。要知道在AlexNet中,全连接层参数占整个网络总参数的90%。使用一个更深更大的网络使得GoogLeNet移除全连接层之后还不影响准确度。其在ImageNet上的top-5准确度为93.3%,但是速度还比VGG还快。
6. ResNet
从前面可以看到,随着网络深度增加,网络的准确度应该同步增加,当然要注意过拟合问题。但是网络深度增加的一个问题在于这些增加的层是参数更新的信号,因为梯度是从后向前传播的,增加网络深度后,比较靠前的层梯度会很小。
这意味着这些层基本上学习停滞了,这就是梯度消失问题。深度网络的第二个问题在于训练,当网络更深时意味着参数空间更大,优化问题变得更难,因此简单地去增加网络深度反而出现更高的训练误差。
残差网络 [ResNet]
https://arxiv.org/abs/1512.03385
设计一种残差模块让我们可以训练更深的网络
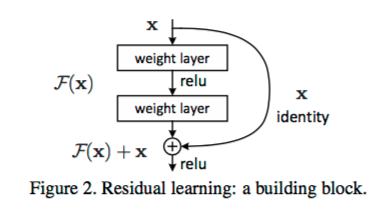
深度网络的训练问题称为退化问题,残差单元可以解决退化问题的背后逻辑在于此:想象一个网络A,其训练误差为x。
现在通过在A上面堆积更多的层来构建网络B,这些新增的层什么也不做,仅仅复制前面A的输出。这些新增的层称为C。
这意味着网络B应该和A的训练误差一样。那么,如果训练网络B其训练误差应该不会差于A。但是实际上却是更差,唯一的原因是让增加的层C学习恒等映射并不容易。
为了解决这个退化问题,残差模块在输入和输出之间建立了一个直接连接,这样新增的层C仅仅需要在原来的输入层基础上学习新的特征,即学习残差,会比较容易。
与GoogLeNet类似,ResNet也最后使用了全局均值池化层。利用残差模块,可以训练152层的残差网络。其准确度比VGG和GoogLeNet要高,但是计算效率也比VGG高。152层的ResNet其top-5准确度为95.51%。
ResNet主要使用3x3卷积,这点与VGG类似。在VGG基础上,短路连接插入进入形成残差网络。如下图所示:

残差网络实验结果表明:34层的普通网络比18层网路训练误差还打,这就是前面所说的退化问题。但是34层的残差网络比18层残差网络训练误差要好。
7. 总结
随着越来越复杂的架构的提出,一些网络可能就流行几年就走下神坛,但是其背后的设计哲学却是值得学习的。这篇文章对近几年比较流行的CNN架构的设计原则做了一个总结。
(译者注:可以看到,网络的深度越来越大,以保证得到更好的准确度。网络结构倾向采用较少的卷积核,如1x1和3x3卷积核,这说明CNN设计要考虑计算效率了。)
一个明显的趋势是采用模块结构,这在GoogLeNet和ResNet中可以看到,这是一种很好的设计典范,采用模块化结构可以减少我们网络的设计空间,另外一个点是模块里面使用瓶颈层可以降低计算量,这也是一个优势。
这篇文章没有提到的是最近的一些移动端的轻量级CNN模型,如MobileNet,SqueezeNet,ShuffleNet等,这些网络大小非常小,而且计算很高效,可以满足移动端需求,是在准确度和速度之间做了平衡。
8. 参考文献
http://cv-tricks.com/cnn/understand-resnet-alexnet-vgg-inception/
编辑:文婧



