![]()
【导读】本教程由著名NLP团队、Transformers开发者Huggingface深度学习和计算语言学–科学负责人Thom Wolf出品。几年前创建聊天机器人可能需要花几个月的时间,编写成千上万的答案以涵盖某些对话主题。随着NLP深度学习的最新进展,我们现在可以摆脱这项琐碎的工作,并在短短几个小时之内构建功能更强大的会话式AI,本文详细介绍了如何实现这一目标。
了解NLP的读者应该对Hugging Face这个名字非常熟悉了。他们制作了Transformers(GitHub超1.5万星)、neuralcoref、pytorch-pretrained-BigGAN等非常流行的模型。
即便你不是做人工智能的,也可能对这个名字有所耳闻,Hugging Face App在国外青少年中也有不小的影响力。
今天我们带来的是由Hugging Face团队深度学习和计算语言学–科学负责人Thomas Wolf教授撰写的利用迁移学习打造最前进的会话AI。本教程在非常受欢迎,今天新智元为大家译成中文。
https://convai.huggingface.co/
如何使用“迁移学习”功能基于OpenAI GPT和GPT-2 Transformer语言模型构建最先进的会话智能体
如何重现在NeurIPS 2018对话竞赛ConvAI2中使用的模型
如何在少于250行、带注释的训练代码(具有分布式和FP16选项)中提取3k+行竞争代码
如何在云实例上以不到20美元的价格训练该模型,或者仅使用教程提供的开源预训练模型
https://github.com/huggingface/transfer-learning-conv-ai
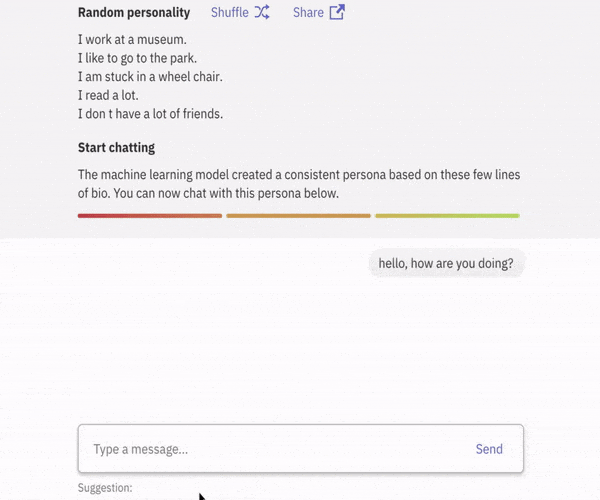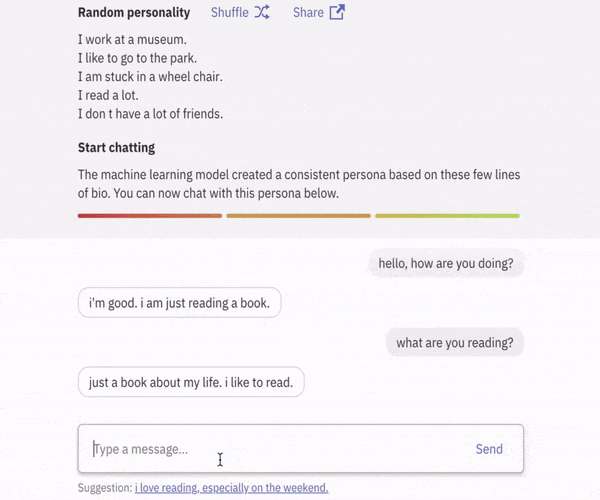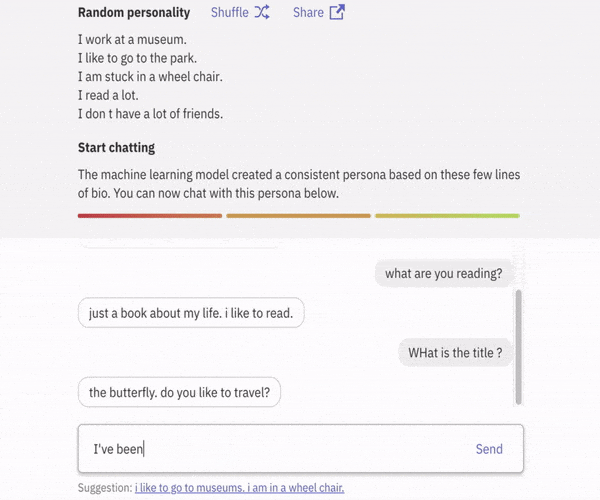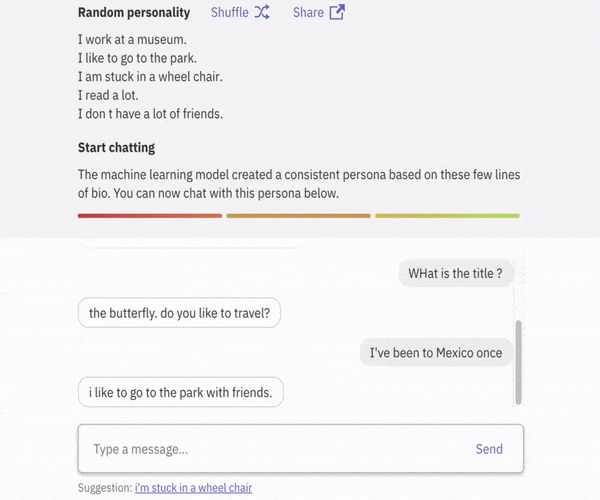
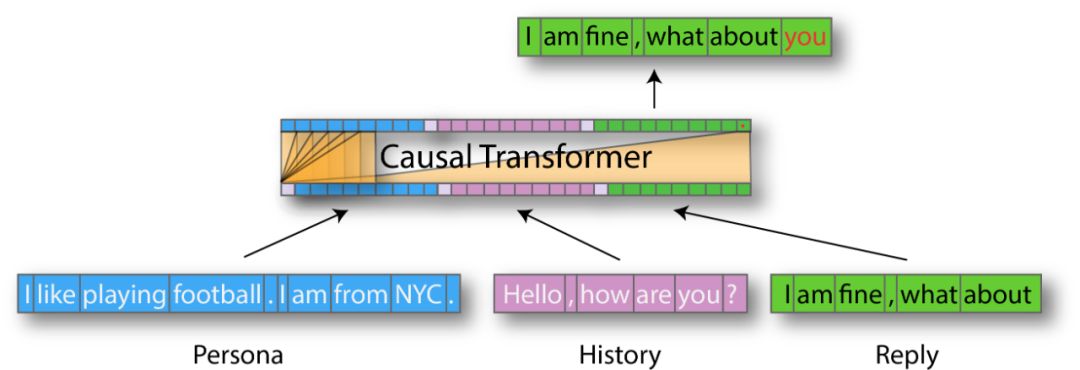
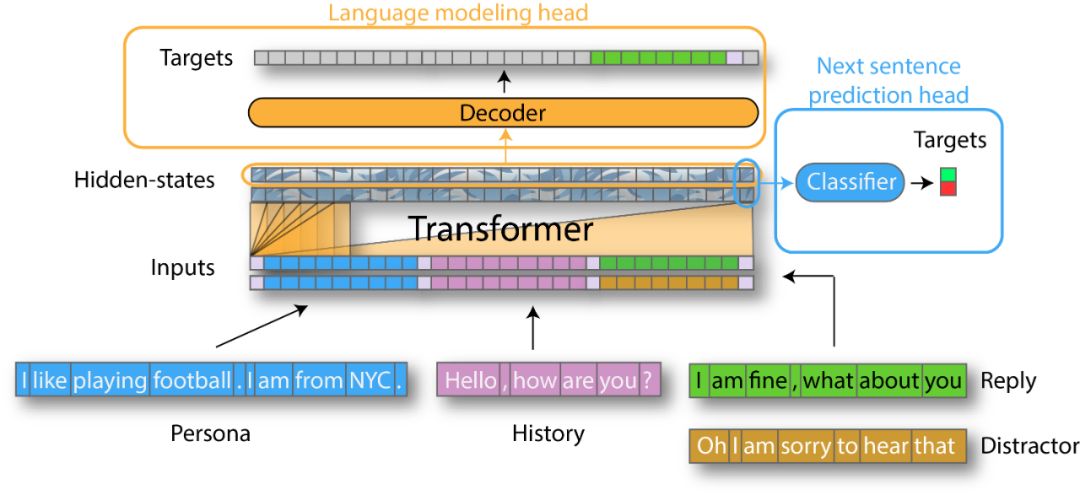
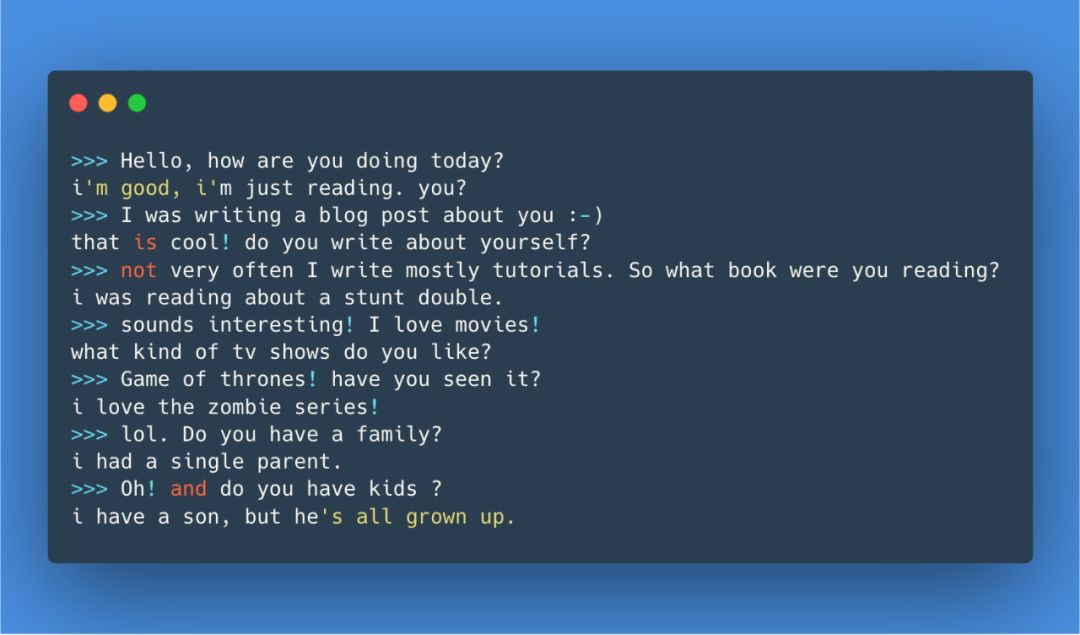
首先会话智能体具有知识库,用来存储描述其身份(角色)和对话历史的句子。当从用户处接收到新的语音时,智能体将该知识库的内容与新接收的语音相结合,即可生成答复。
以端到端的方式训练基于深度学习的会话智能体,面临一个主要问题:对话数据集很小,很难从中学习语言和常识,从而无法进行流利的响应。
预训练模型自然是越大越好。本文使用GPT和GPT-2。GPT和GPT-2是两个非常类似的、基于Transformer的语言模型。这些模型称为解码器或因果模型,这意味着它们使用上下文来预测下一个单词。
在大型语料库上对这些模型进行预训练是一项昂贵的操作,因此,我们将从OpenAI预训练的模型和令牌生成器开始。令牌生成器负责将输入的字符串拆分为令牌(单词/子单词),并将这些令牌转换为模型词汇表的正确数字索引。
在对话设置中,模型将必须使用几种类型的上下文来生成输出序列:
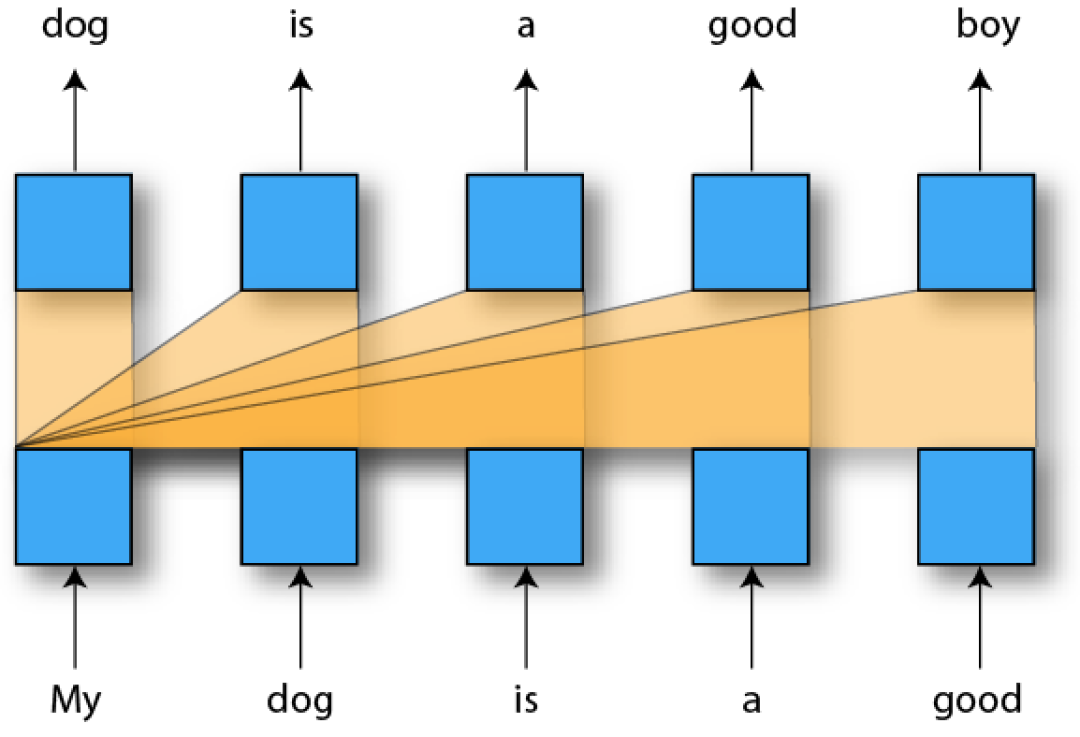
简单的方法之一就是将上下文段按单个顺序连接起来,然后将答案放在最后。然后可以通过继续执行序列来逐个令牌地生成答复令牌:
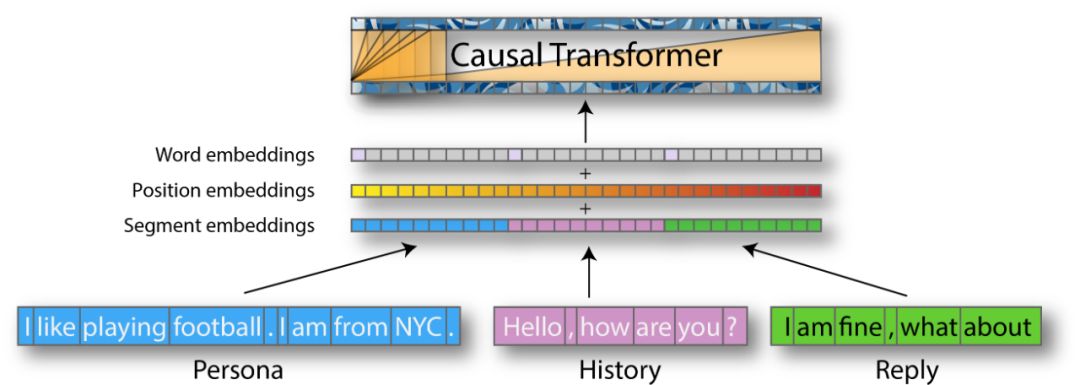
这个简单的设置有两个问题:transformer不能区分颜色也不能区分位置。添加以上信息的一种简单方法是为单词,位置和句段构建三个并行的输入序列,并将它们融合为一个序列,对三种类型的嵌入进行求和:单词,位置和句段的嵌入:
这些特殊令牌方法分别将我们的五个特殊令牌添加到令牌生成器的词汇表中,并在模型中创建五个附加嵌入。
现在,从角色,历史记录和回复上下文开始构建输入序列所需的一切都有了。一个简单的示例:
现在,我们已经初始化了预训练模型并建立了训练输入,剩下的就是选择在优化过程中要优化的损失。
下一句预测目标是BERT预训练的一部分。它包括从数据集中随机抽取干扰因素并训练模型,以区分输入序列是以满意回复或者胡乱回复结束。它训练模型以查看全局片段,而不只是局部上下文。
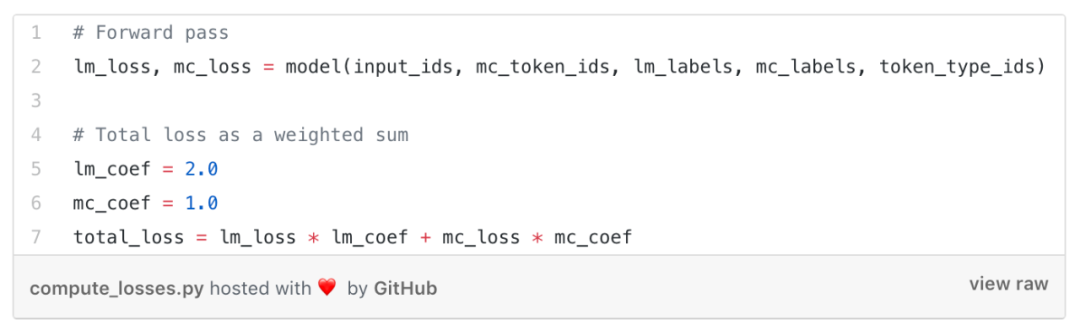
所以需要加载“双头”模型:一个负责将计算语言建模预测,而另一个负责将预测的下一句分类标签。让我们看一下如何计算损失:
总损失将是语言建模损失和下一句预测损失的加权总和,计算方式如下:
现在,我们有了模型所需的所有输入,并且可以对模型进行正向传递以获取两个损失和总损失(作为加权总和):
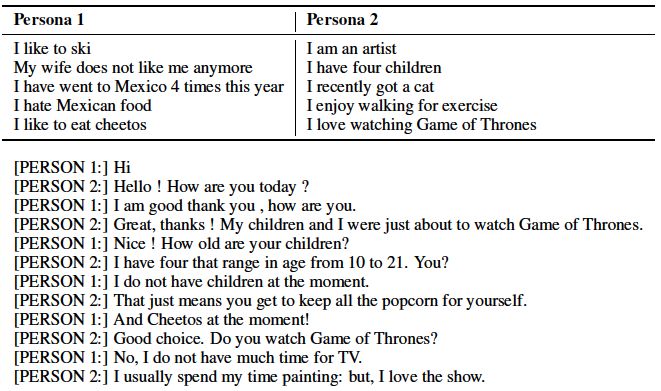
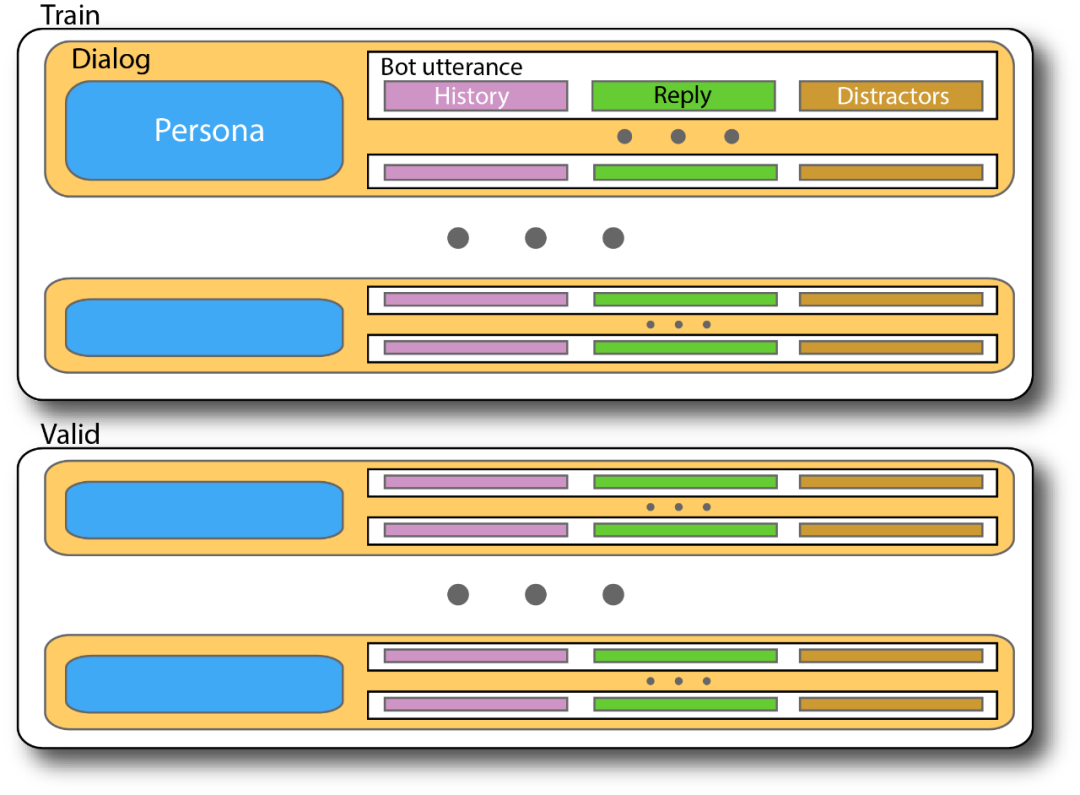
ConvAI2竞赛使用了Facebook去年发布的一个有趣的数据集:PERSONA-CHAT。
这是一个相当大的对话数据集(一万个对话),该数据集可在Facebook的ParlAI库中以原始标记化文本格式使用。本教程还上传了JSON格式的版本,可以使用GPT的令牌生成器下载和令牌化,如下所示:
PERSONA-CHAT的JSON版本可快速访问所有相关输入,可以将我们的模型训练为嵌套的列表字典:
借助令人敬畏的PyTorch ignite框架和NVIDIA apex提供的新的自动混合精度API(FP16 / 32),我们能够在少于250行的训练代码中使用分布和FP16选项提取+ 3k竞争代码!
https://github.com/huggingface/transfer-learning-conv-ai
在具有8个V100 GPU的AWS实例上训练该模型需要不到一个小时的时间(目前在最大的p3.16xlarge AWS实例上,该费用还不到25美元),其结果接近在ConvAI2比赛中获得SOTA的Hits@1(超过79), perplexity(20.5)furthermore1(16.5)。
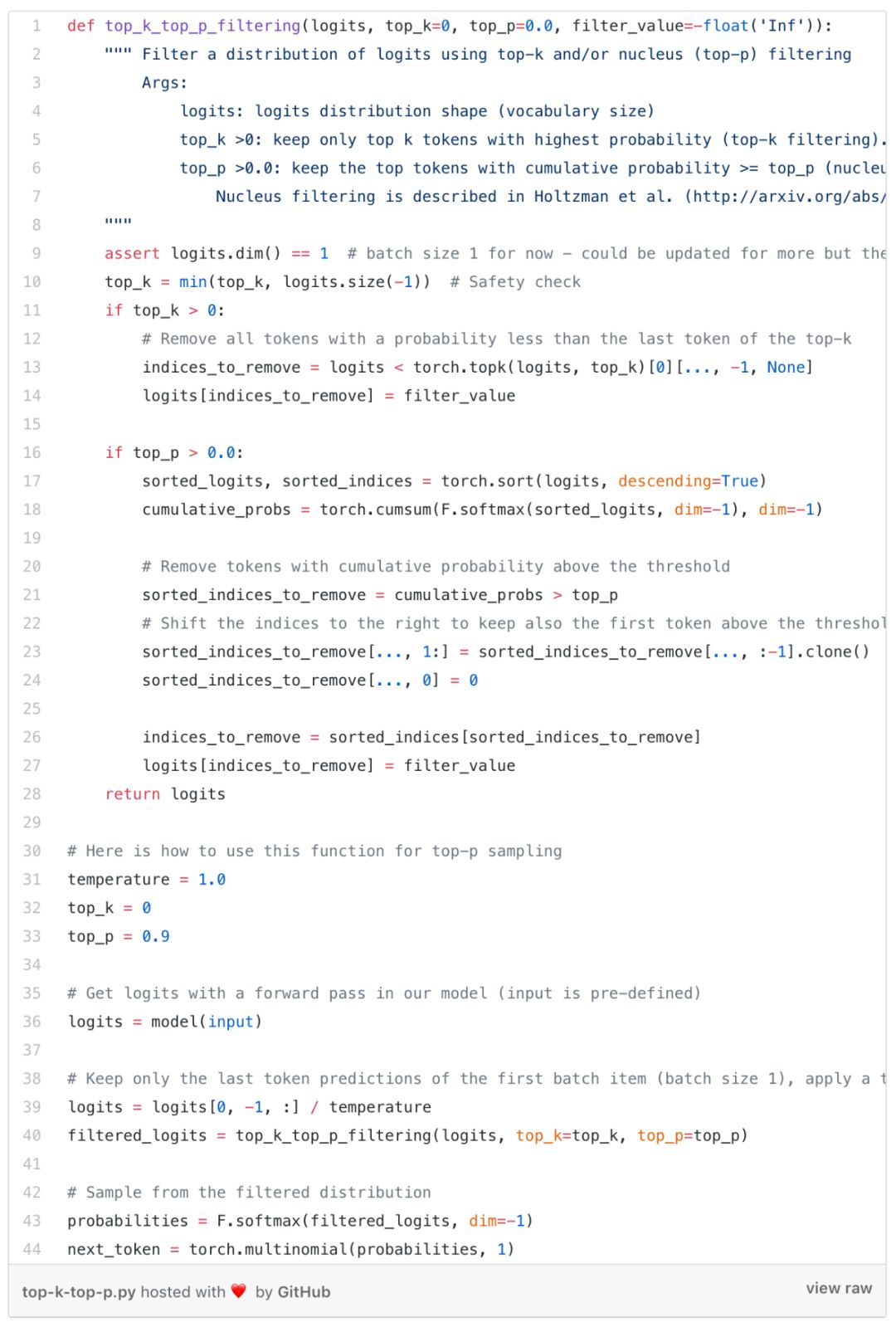
为了与我们的模型进行交互,我们需要添加一个解码器,它将根据我们模型的下一个令牌预测来构建完整序列。
当前,成功进行beam-search/贪婪解码的两个最佳选择是top-k和nucleus (或top-p) 采样。这是我们如何使用top-k或nucleus/top-p)采样进行解码的方法:
https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313
广告 & 商务合作请加微信:kellyhyw
投稿请发送至:mary.hu@aisdk.com
年度重磅AI活动来袭
北京智源大会将于2019年10月31日至11月1日在国家会议中心召开。强大嘉宾阵容,汇聚国内外人工智能各领域的知名学者,进行独家经验分享和领域案例剖析。两天时间,超过15场尖峰论坛及对话,你最关心的那些问题,答案都在这里!
扫描海报二维码进行注册和报名,学生票仅99元。购票使用优惠码 BAAIQQRGZN,享受7折优惠!
![]()