利用LSTM思想来做CNN剪枝,北大提出Gate Decorator
选自arXiv
作者:Zhonghui You等
机器之心编译
参与:思源、一鸣
利用LSTM基本思想门控机制进行剪枝?让模型自己决定哪些卷积核可以扔。
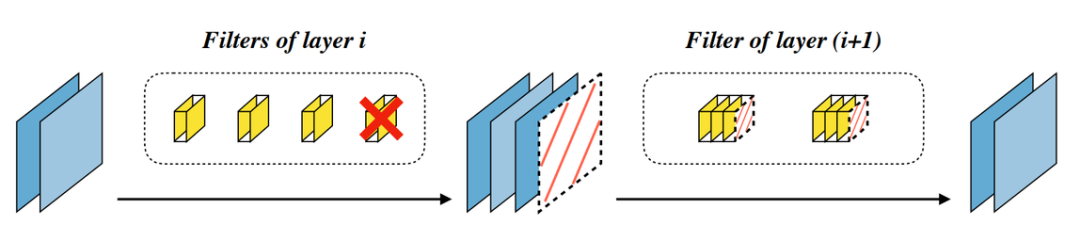

论文地址:https://arxiv.org/abs/1909.08174
实现地址:https://github.com/youzhonghui/gate-decorator-pruning
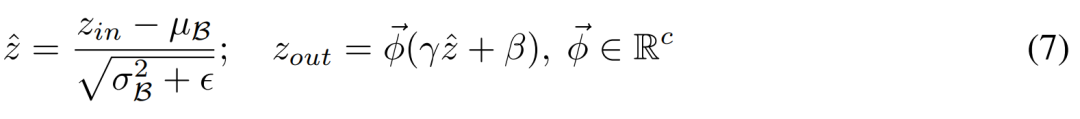
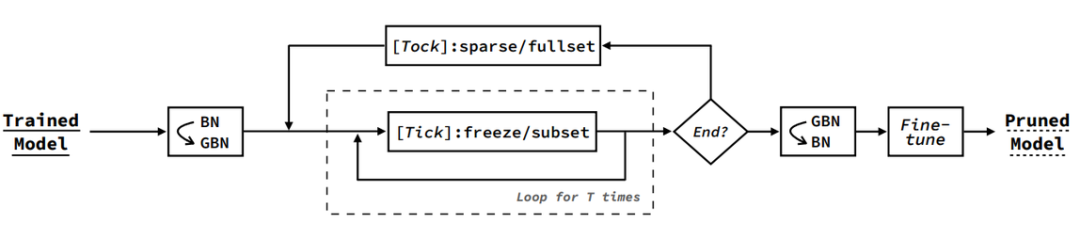
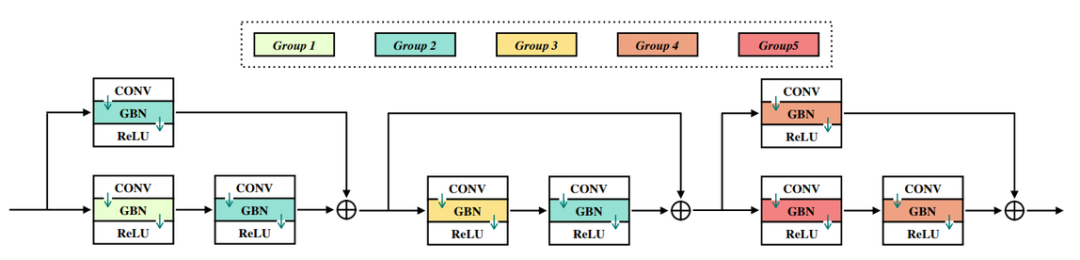

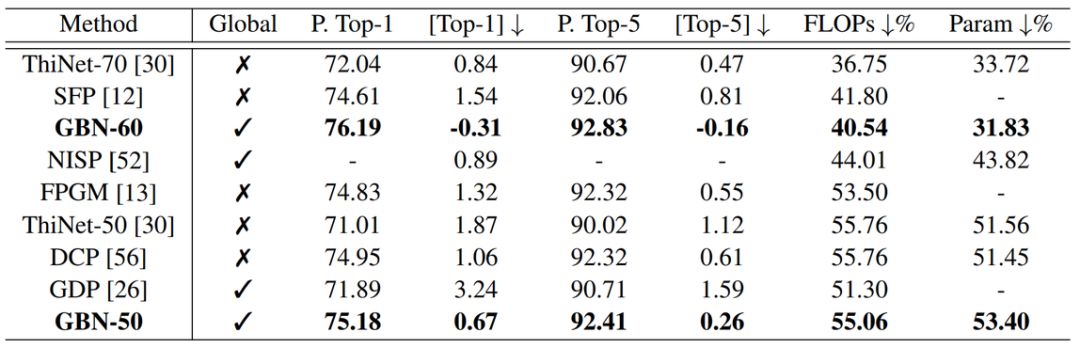
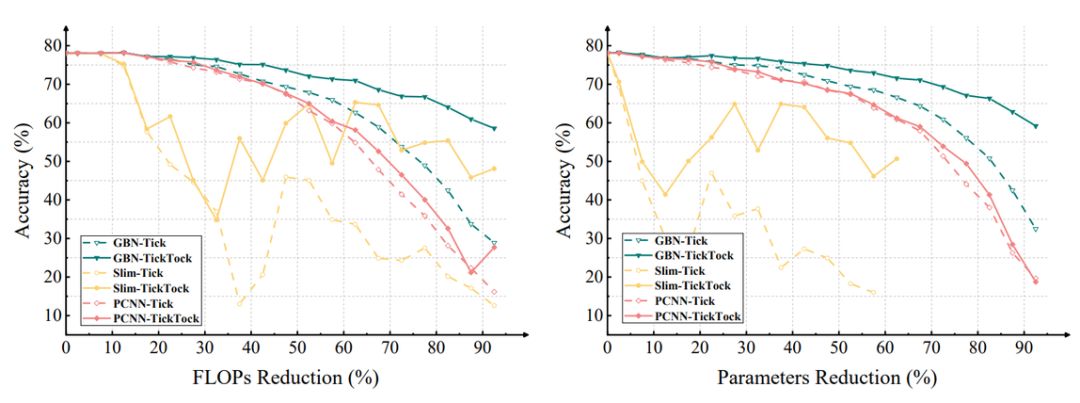
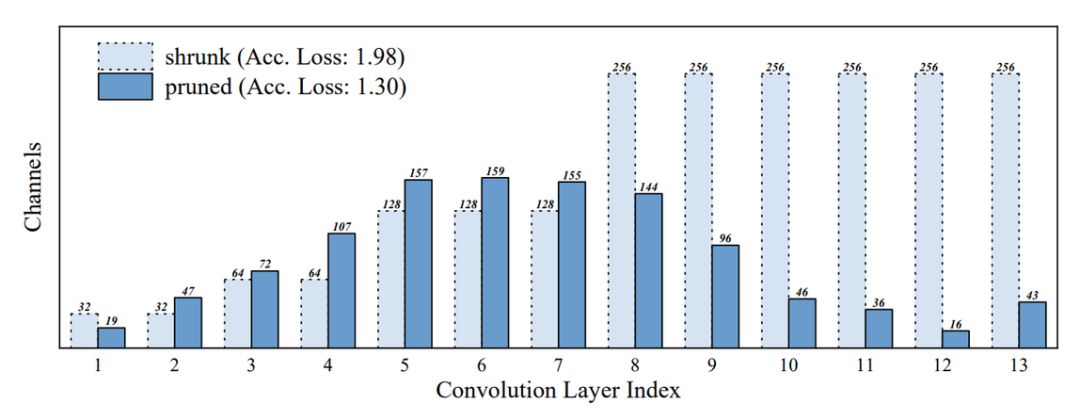
登录查看更多
相关内容
专知会员服务
44+阅读 · 2020年3月26日
专知会员服务
26+阅读 · 2019年11月23日
专知会员服务
17+阅读 · 2019年11月17日
Arxiv
4+阅读 · 2018年12月28日
Arxiv
16+阅读 · 2018年1月31日
Arxiv
16+阅读 · 2017年11月20日


相关VIP内容
专知会员服务
44+阅读 · 2020年3月26日
专知会员服务
26+阅读 · 2019年11月23日
专知会员服务
17+阅读 · 2019年11月17日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年12月28日
Arxiv
16+阅读 · 2018年1月31日
Arxiv
16+阅读 · 2017年11月20日