ICCV 2019 | 递归级联网络:基于无监督学习的医学图像配准

编者按:目前,深度学习正广泛应用于医学图像配准领域。无监督机器学习方法能够广泛利用临床中产生的大量原始、无标注医学图像,然而现有算法对于变形大、变化复杂的图像配准的学习效果较差。微软亚洲研究院在 ICCV 2019 发表的论文中,提出一种深度递归级联的神经网络结构,可以显著提高无监督配准算法的准确率。
医学图像配准是医学图像处理任务中的关键步骤,具有重要的临床意义。医学图像配准即分别给定一张运动的和固定的 3D 医学图像,希望将运动图像(moving image)配准到固定图像(fixed image),如图1所示。图像可能来自相同或不同个体的三维脑 MRI 的二维切片。通过预测非线性变形场,我们可以将运动图像变形为变形图像(warped image)。在理想情况下,变形图像应该与固定图像非常相似,即便它源自运动图像。

图1:医学图像配准
近年来,深度学习技术在医学图像配准中已经获得了广泛的应用。有监督学习方法的主要问题是流场真值(ground truth)很难获得,即便对于医学专家来说,医学图像配准的成对相关像素点也难以标注;而无监督学习方法能够利用可导的 STN(spatial transformer),以在变形图像和固定图像之间测得的图像相似性为优化目标,能够利用临床中广泛的原始数据且无需标注。然而现有算法只能学习将运动图像一次性对齐到固定图像,对于变形大、变化复杂的配准效果较差。
本文提出了一种深度递归级联的神经网络结构,可以显著提高无监督配准算法的准确率。图2是用于肝脏配准的递归级联网络效果图。运动图像通过一次次微小的递归配准,最后与固定图像对齐。每个子网络的输入都是变形后的图像和固定图像,预测一个流场Φ。通过深度的递归迭代,最终的流场可以被分解为简单、轻微的渐进变化,大大降低了每个子网络的学习难度。
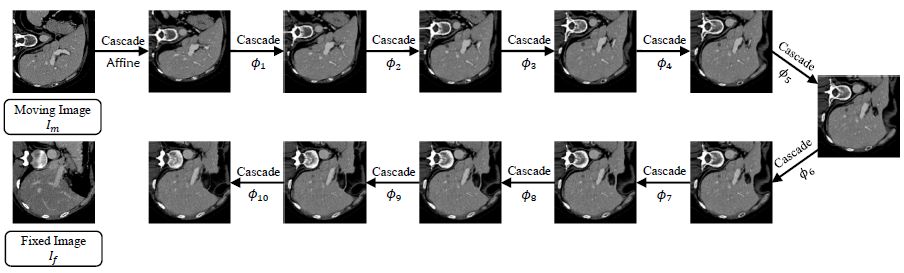
图2:用于肝脏配准的递归级联网络效果图
递归级联网络可以构建于任何已有的基础网络之上,通过无监督、端到端的方式学习到深度递归的渐进配准。除此之外,我们还提出了一种 shared-weight 级联技术,可以在测试中直接增加递归深度并提高准确率。
我们在肝脏 CT 图像和脑 MRI 图像上都做了算法评测,使用了多样的评价指标(包括 Dice 和关键点)。我们的实验证明递归级联的结构对于两种基础网络(VTN 和 VoxelMorph)的作用都非常显著,并且在所有数据集上都超过了包括 SyN 和 B-Spline 在内的传统算法。
我们的核心思想是通过深度递归级联结构实现渐进式对齐的无监督端到端学习。在图2所示情况下,运动图像与固定图像有很大的不同,这表明流场真值应该非常复杂并且可能很难预测。但是,我们的递归级联网络可以将这一困难的学习过程分解为渐进的部分,使每对之间的流场变得简单易学。
另一方面,从模型的流场合成效果图(图3)中可以看出,前面的子网络主要学习到了全局的配准,而后面的子网络起到了完善细节的作用。最终的流场确实可以分解为相当简单的部分。
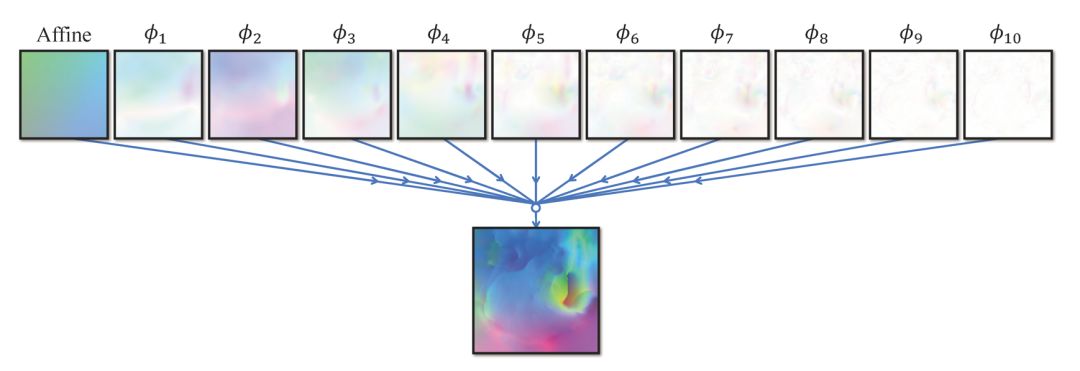
图3:流场合成效果图
深度递归级联的网络结构如图4所示。运动图像通过每个子网络的预测流场依次变形,最后与固定图像对齐,此过程是递归的,每个子网络都学习对当前的变形图像的渐进式配准。
我们与其它算法的主要区别在于,递归级联网络的优化目标只有最后两张图像的相似度,从而赋予了所有子网络共同学习渐进式配准的能力。可导的变形操作使得整个端到端系统在无监督的情况下共同训练成为可能。在递归结构的基础上,我们提出一种附加的 shared-weight 级联技术,可以在测试中直接增加递归深度并提高准确率。
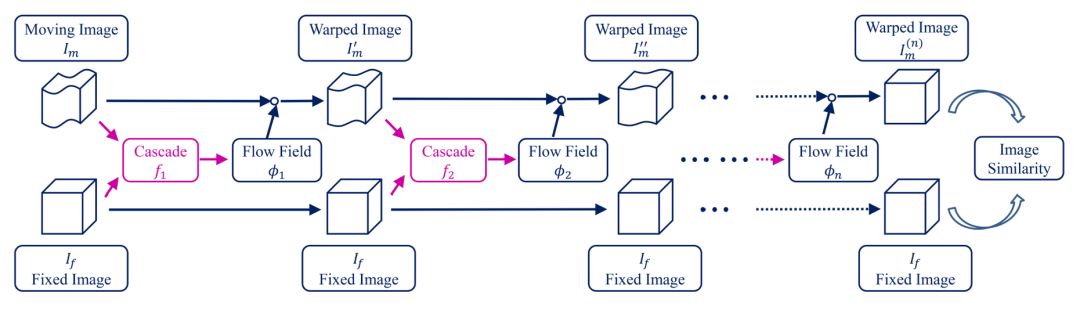
图4:递归级联网络
我们使用 Dice 和关键点距离(Landmark Dist.)两种评估指标进行了广泛的实验,并在多个数据集上进行了算法评测,包括肝脏 CT 图像和脑 MRI 图像。
我们基于两种基础网络 VTN 和 VoxelMorph 构建了递归级联网络(递归级联网络可以构建于任何基础网络之上,并不局限于 VTN 和 VoxelMorph)。表1总结了我们与传统算法以及与基础网络相比的总体性能。可以看到,递归级联网络在所有数据集中的 Dice 和关键点距离均显著优于现有方法。
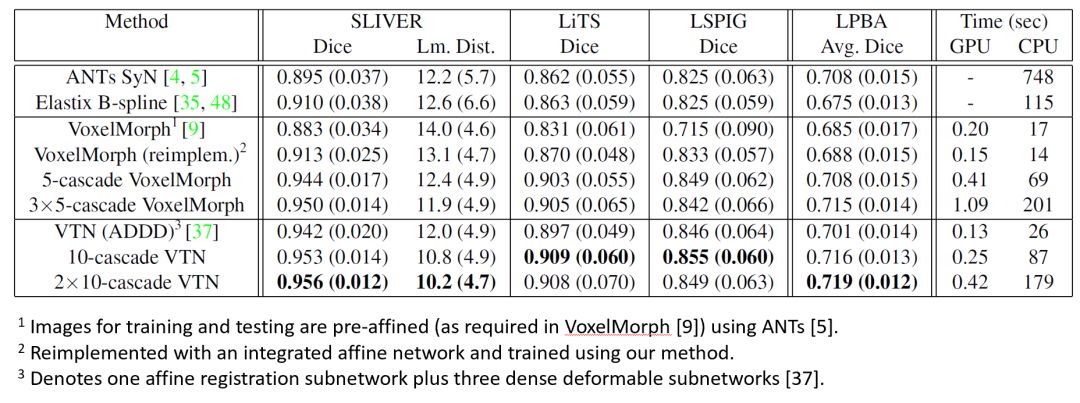
表1:实验结果
图5的三个子图说明了关于不同数量级联的实验结果。随着级联数量的增加,模型的表现呈上升趋势。
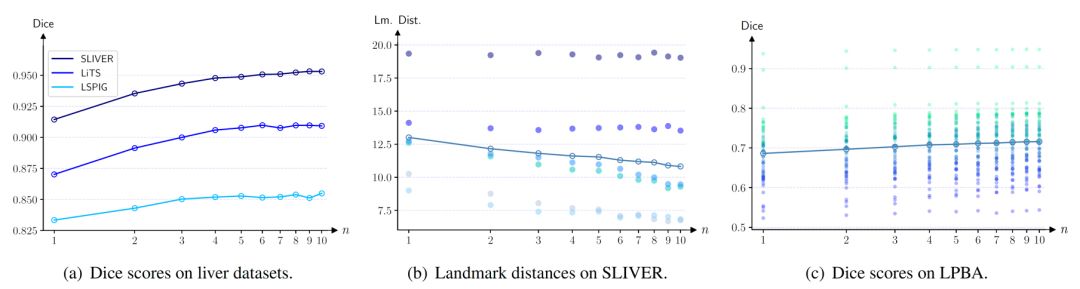
图5:不同级联数量下 Dice 和关键点距离的变化趋势
那么,直接增加通道数或者卷积深度能否起到和网络级联一样的效果呢?例如,VoxelMorph(VM)提出将卷积层中的通道数加倍(VM x2)可以获得更好的性能。作为对比,我们通过将卷积层的深度加倍来构造 VM-double,还构造了一种同样将深度加倍的编码器-解码器-编码器-解码器的网络结构(VM xx2),VM xx2 与 2-cascade VM 的结构除了变形操作之外都是相似的。这些 VM 变种相比于 2-cascade VM 都具有相同或更多的参数数量。从表2中可以看出,VM 变种的表现都不如 2-cascade VM,甚至还不如直接 shared-weight 的 2x1-cascade VM。该实验表明,我们的改进本质上是基于所提出的递归级联结构,而不是简单地引入更多参数。
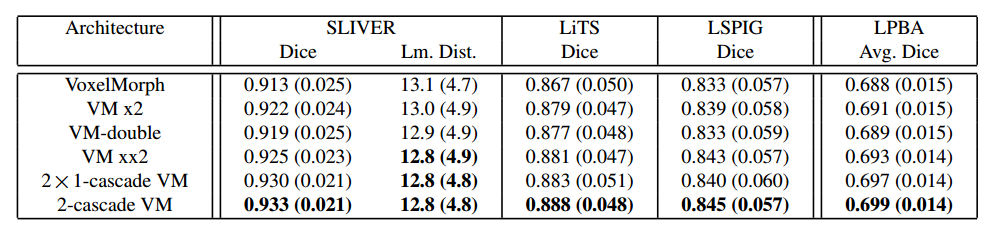
表2:递归级联网络与其它 VoxelMorph 网络变种的对比
图6中显示了使用不同方法预测的流场。可以看出,我们预测的流场与其它算法相比具有更精细的细节,从而产生了更准确的变形图像。
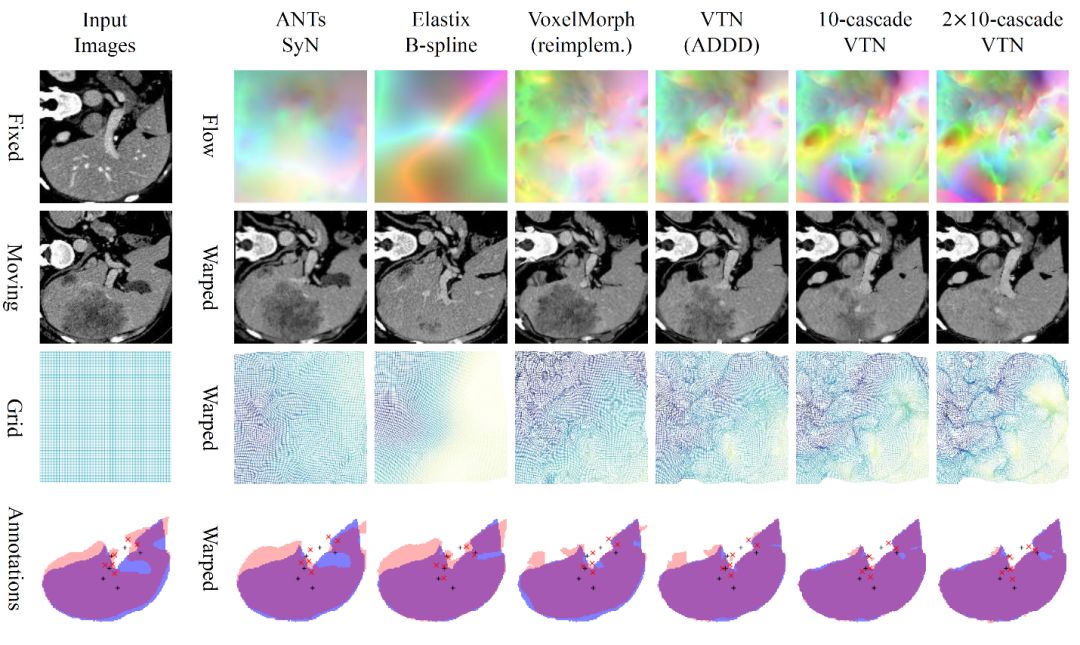
图6:预测流场可视化
我们提出了一种深度递归级联的网络结构,应用于无监督端到端的医学图像配准。该网络结构简单且易于训练,功能强大且易于推广。与其它方法相比,递归级联网络带来了显著的性能提升。凭借良好的性能优势、无监督方法的普遍适用性、以及独立于基础网络的一般性,我们期望递归级联网络可以在医学图像配准任务中得到更广泛地应用。
了解更多技术细节,请点击阅读原文访问 GitHub 主页。
你也许还想看: