干货 | 港科大博士生侯璐:基于损失函数的神经网络量化方法

AI科技评论按:神经网络功能强大,但是其巨大的存储和计算代价也使得它的使用特性,特别是在一些计算能力相对较弱的移动设备上受到了很大的限制。为了解决这个问题, 最近有许多针对于神经网络压缩和加速的工作被提出, 例如神经网络剪枝, 权重矩阵低秩分解,权重量化等。这次分享主要是针对于权重量化这一类方法。
近期,在 GAIR 大讲堂上,来自香港科技大学的博士生侯璐同学分享了深度学习网络的权重量化的一些最新进展以及几篇 ICLR 的论文解读。
嘉宾介绍:
侯璐,香港科技大学在读博士,主要研究方向为机器学习。
分享主题:
基于损失函数的神经网络量化方法
分享提纲
1.概述近期神经网络压缩和加速的工作, 例如神经网络剪枝, 权重矩阵低秩分解,权重量化等。
2.回顾近两年来的权重量化方法,并分析这些方法的优缺点。
3.介绍基于减小最终目标函数的量化方法, 并分析这种方法和其他量化方法的关系和优势。
分享内容
深度学习在我们的的生活中已经得到了非常广泛的应用,包括自动驾驶、机器翻译、医疗、游戏竞技等方面。

先介绍一下深度学习模型的建立。深度学习一般分为训练和测试两个模块。在训练部分,训练模型、数据集以及耗费的 GPU 资源一般都很大,但测试时我们往往要把这些模型应用到如手机等计算能力较弱的平台。这是就会遇到两个问题,一是计算资源不足,二是内存不足。
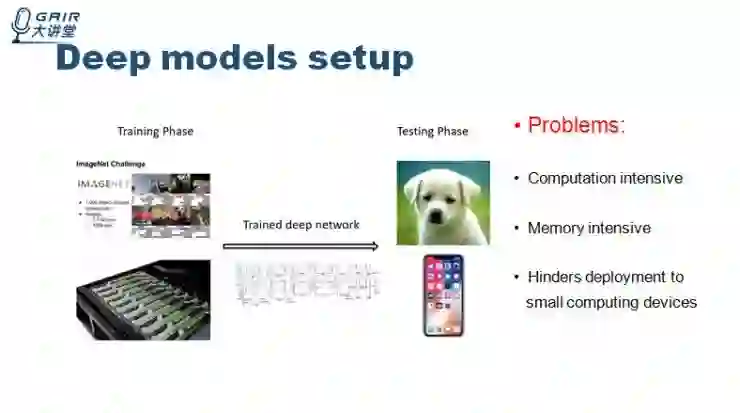
目前也有很多研究工作在试图解决这个问题。方法包括使用更加先进的硬件,迁移学习,优化算法,但今天的分享内容着重讲模型的压缩和加速。

模型压缩这个领域当前比较火的有这几个方向。一是权重的剪枝与共享,二是使用一些更加紧凑又有效的模块,三是使用一些低秩的矩阵,最后就是今天分享的重点——权重量化。

先介绍一下权重剪枝。这是 2015 在 NIPS 上提出来的,这个方法分为三步,先训练一个全连接的网络,然后去掉一些不太重要的连接,最再训练剪枝后的网络。

在介绍一下权重共享,这个方法是 2016 年 NIPS 的 bestpaper 中提出的。该方法同样分为三步,第一步就是剪枝的过程,第二步是量化和权重共享,最后使用哈弗曼编码处理达到更高的压缩率。但这种方法对计算量的减少并不明显。

第二部分就是使用更加紧凑有效的模型,如 SqueezeNet,MobileNet,ShuffleNet 等。

SqueezeNet 在较小的网络上效率提升并不显著。


其实这两种方法和别的方法相比实施起来并不容易。第三部分我想介绍一下低秩矩阵的方法,这种方法可以减少计算中乘法和加法的次数也减少了。但问题也很明显,即安插到原模型后训练量会增加。

接下来是今天的重点,即权重量化的内容。最简单的是二值化,用 1 个比特来表示原来 32 比特表示的权重。更精确的是三值化,最常见的是 m-bit。

先介绍一下权重量化与之前方法相比较下的优势,包括训练与量化同时进行等。

然后再说一下量化的流程。简单介绍就是先用量化之后的权重做正向传播,再做反向传播得到量化权重的梯度,然后更新权重进入下一次迭代。

接下来介绍一下二值化网络的主要工作,第一个是 BinaryConnect,这种方法虽然可以量化,却无法知晓量化后的效果优劣。

第二是 Binary Weight Network,这种方法任然无法保证对降低损失函数有正面效果。

然后是三值化的工作,包括 Ternary-connect 和 Ternary Weight Networks (TWN)以及 Trained Ternary Quantization(TTQ)。


前两种方法的问题与二值化工作的问题是一样的,但权重的精度提高了。

这种方法任然存在与前两种方法类似的问题。目前更常见的方法是 m-bit 的方法。包括 DoReFa-Net 和 Low-Bit Neural Network (LBNN)两种方法。


如上图所示,这两种方法各自存在自己的问题。接下来介绍我们团队在 ICLR2017 和 2018 发表的方法。先将 Loss-aware Weight Quantization 的框架。

然后求解算法用的是 Proximal Newton Algorithm。

再将这个算法应用到之前的 formulation。

我分析一下上面两步的具体含义,如下:

然后在看一下具体的算法。

这个算法的一些证明如下:

以上是框架介绍,接下来具体介绍 Loss-aware Binarization,

以及 Loss-aware Ternarization (LAT)。

针对 Ternarization,我们提出了精确求解的方法即 LATe。

但因为精确解涉及到排序算法,耗费增大。然后我们提出 LATa 去求近似解。

之后我们还提出 Loss-aware Ternarization 的两个变种。


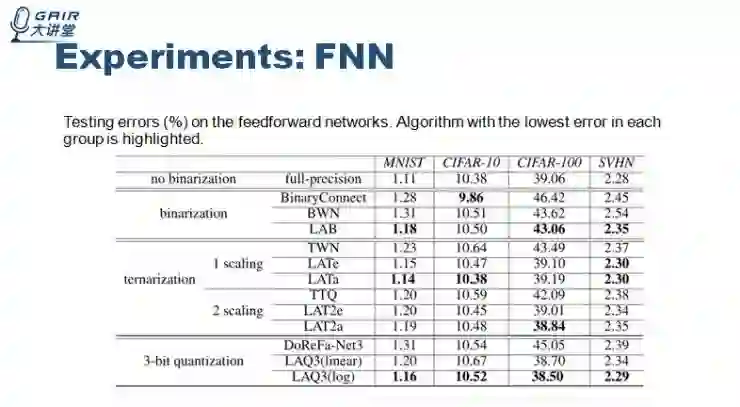
接着介绍一下实验部分,FNN 实验我们使用了 MNIST、CIFAR-10、CIFAR-100、SVHN 这四个数据集。最终模型的实验效果如下
RNN 实验我们使用 WAR andPeace、Linux Kernel、Penn Treebank 这三个数据集,实验结果如下
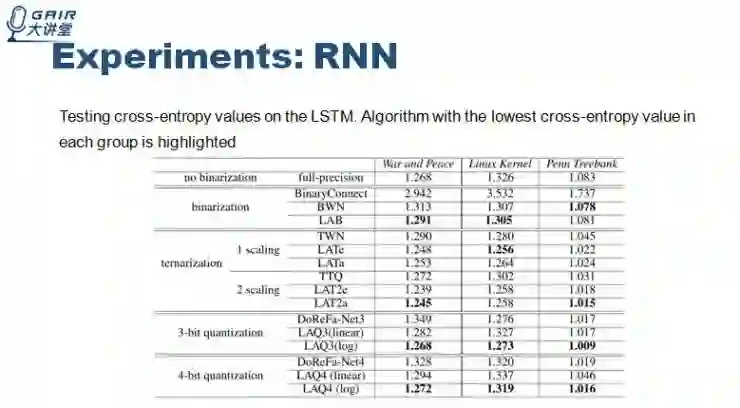
这两个实验我们的算法的表现都是比较好的。这就是我今天全部的分享内容。
以上就是 AI 科技评论对侯璐博士直播全部内容的整理,大家如果感兴趣可以点击阅读原文观看完整视频回放。
对了,我们招人了,了解一下?

CCF-GAIR(CCF 全球人工智能与机器人峰会)
将在 6 月底再次席卷鹏城
连续 3 天 11 场 分享盛宴
6.29 - 7.1,我们准时相约!

┏(^0^)┛欢迎分享,明天见!


