学界 | DeepMind 在多智能体强化学习方面又有了新进展,最新成果登上 Science 杂志!

智能体与 AI 或人类队友协作打游戏,表现媲美人类玩家。
AI 科技评论按:集体智能(collective intelligence)是人工智能研究浪潮中不可被忽视的重要课题。然而,智能体如何在边界开放、约束动态的环境下学习到知识,并且进行团队协作仍然是极具挑战的难题。DeepMind 近年来针对基于种群的多智能体强化学习进行了大量的研究,其最新研究成果近日发表在了国际权威杂志「Science」上。DeepMind 发博客将这一成果进行了介绍,AI 科技评论编译如下。
智能体在多玩家电子游戏中掌握策略、理解战术以及进行团队协作是人工智能研究领域的重大挑战。我们发表在「科学」杂志上的最新论文「Human-level performance in 3D multiplayer games with population-based reinforcement learning」中,展示了智能体在强化学习领域的最新进展,在「Quake III Arena」夺旗赛(CTF)中取得了与人类水平相当的性能。这是一个复杂的多智能体环境,也是第一人称多玩家的经典三维游戏之一。这些智能体成功地与 AI 队友和人类队友协作,表现出了很高的性能,即使在训练时其反应时间,表现也与人类相当。此外,我们还展示了如何能够成功地将这些方法从研究 CTF 环境中扩展到完整的「Quake III Arena」游戏中。
论文地址(Science):
https://science.sciencemag.org/cgi/doi/10.1126/science.aau6249

玩CTF游戏的智能体,以其中一个红色玩家为第一人称视角展现的室内环境(左图)和室外环境(右图)。
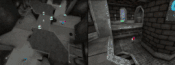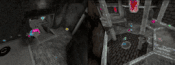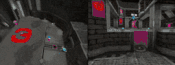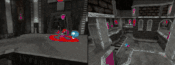
智能体在完整的锦标赛地图上的另外两个「Quake III Arena」多人游戏模式下进行游戏:在「Future Crossings」地图上进行收割者模式的游戏(左图),在「ironwood」地图上进行单旗夺旗模式的游戏(右图),在游戏中可以拾取并使用完整版游戏的所有的道具。
目前,有数十亿人居住在地球上,每个人都有自己独特的目标和行为。但人们仍然能够通过团队、组织和社会团结在一起,展示出非凡的集体智能。我们将这种情况称为多智能体学习:许多独立的智能体必须各自单独行动,但同时也要学会与其它的智能体进行交互和协作。这是一个非常困难的问题,因为需要协同适应其他的智能体,它们所处的世界环境就会不断变化。
为了研究这个问题,我们着眼于第一人称的多人三维电子游戏。这些游戏也代表着目前最流行的一类电子游戏,由于能够为用户提供沉浸式的游戏体验,这类游戏充分开发了数百万玩家的想象力,同时也对玩家在策略、战术、手眼协调以及团队协作等方面提出了挑战。我们的智能体所面临的挑战便是直接利用原始像素来生成决策行为。这种复杂性也使得第一人称多人游戏在人工智能研究领域中成为了一个硕果累累、朝气蓬勃的研究领域。
夺旗赛:根据像素做出动作决策
在这项研究中,我们聚焦于「Quake III Arena」游戏(在保证所有的游戏机制维持不变的情况下,我们对美工进行了微调)。「Quake III Arena」是许多现代第一人称电子游戏的奠基者,曾经在电子竞技舞台上风靡一时。我们训练智能体像人类玩家一样学习和行动,但是它们必须能够以团队协作的方式与其它智能体(无论是 AI 玩家还是人类玩家)合作或对抗。
CTF 的规则很简单,但是其动态变化则非常复杂。两队独立的玩家比赛的方式是:在给定的地图上以夺取对方队伍的旗帜为目标,同时保护他们自己的旗帜。为了获得战术上的优势,玩家可以攻击对方战队的玩家,将其送回复活点。在 5 分钟的游戏时间结束后,获得旗帜数量最多的队伍将获得胜利。
从多智能体的视角来说,CTF 要求玩家同时做到与他们的队友通力合作以及与对手的队伍进行对抗,并且还要对它们可能遇到的任何比赛方式都要保持鲁棒性。
为了让这个工作变得更有趣,我们还考虑了一个 CTF 的变体形式,其中的地图布局每经过一场比赛就会变化。结果,我们的智能体被迫获取通用的策略,而不是记住地图的布局。此外,为了竞争的公平性,我们的智能体在学习过程中以与人类相似的方式对 CTF 的世界进行探索:他们会观察一组图像的像素流,然后通过模拟的游戏控制器采取行动。

在程序生成的环境中进行CTF,这样一来智能体的能力必须能够泛化到没有见过的地图上。
我们的智能体必须从头开始学会如何观察环境、执行动作、协作以及在未见过的环境中竞争,而所有这些都学习自每场比赛的单个强化信号:它们的团队是否获胜。这是一个极具挑战的学习问题,其解决方案是以如下强化学习的三种通用思想为基础的:
我们训练的是一个智能体种群,而不是训练单个智能体。种群中的智能体通过与其它智能体进行游戏来学习。在游戏中,智能体彼此之间的关系是多种多样的,可能是队友也可能是对手。
种群中的每个智能体都需要学习他们自己的内部奖励信号,这使得智能体可以生成他们自己的内部目标(例如夺取旗帜)。我们使用双层优化处理的方式来优化智能体的内部奖励,从而直接获胜,并且运用基于内部奖励的强化学习技术来学习智能体的游戏策略。
智能体分别以快速和慢速两种游戏时标进行操作,这有助于提升它们使用内存和生成一致的动作序列的能力。
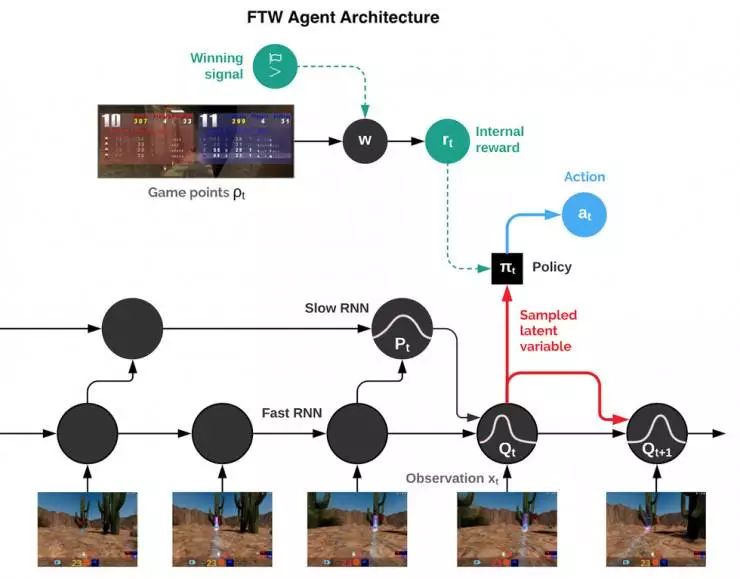
「为了胜利」(FTW)智能体的架构示意图。该智能体融合了快速和慢速两种时标的循环神经网络(RNN),包括一个共享的内存模块,并且学习了从游戏点到内部奖励的转换。
最终得到的智能体被称为 FTW 智能体,他们学着以非常高的水平外 CTF 游戏。非常重要的一点是,学习到的智能体策略对于地图的尺寸、队友的数量、以及队伍中的其他成员等参数变化需要具备鲁棒性。下面,你可以探索一些户外程序环境的游戏(其中 FTW 智能体相互对抗),也可以探索一些人类和智能体在室内程序环境中一起玩的游戏。
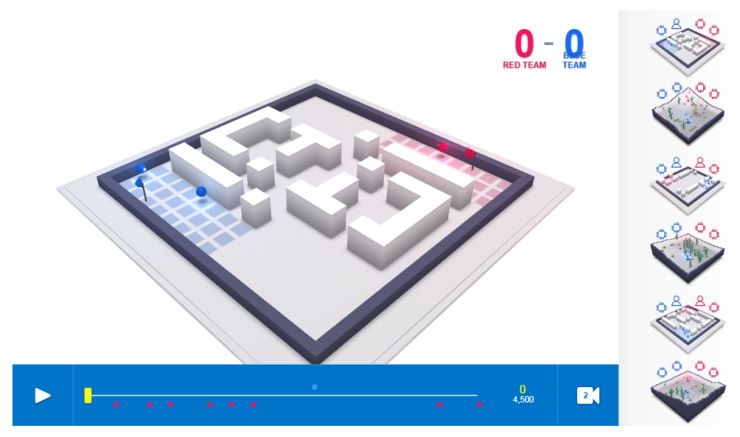
交互式的 CTF 游戏探索器,具有程序生成的室内和室外两种环境。室外地图上的游戏在 FTW 智能体之间开展,而室内地图上的游戏则是人类和 FTW 智能体玩家的混合游戏。
我们进行了一场包括 40 名人类玩家的游戏比赛,在比赛中人类玩家和智能体随机配对,既有可能成为对手,也可能成为队友。

早先的一场测试比赛,对战双方是人类 CTF 玩家和受过训练的其他人类玩家和智能体。
FTW 智能体通过学习变得比强基线方法强大得多,并且超过了人类玩家的胜率。事实上,在一份针对游戏参与者的调查中,它们比人类参与者表现出了更高的协作性。
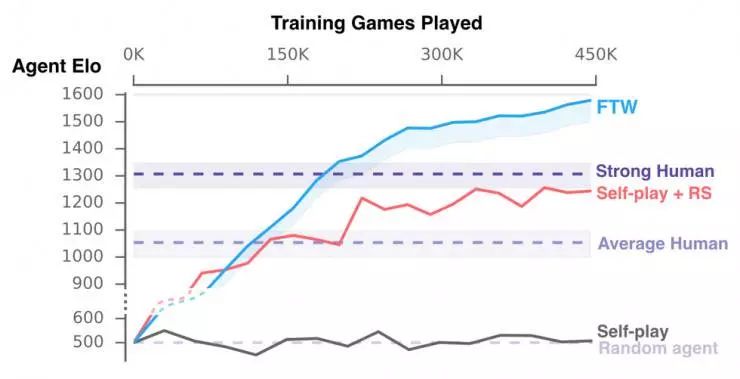
我们的智能体在训练时的性能。我们的新 FTW 智能体,获得了比人类玩家和基线方法(Self-play + RS 和 Self-play)高得多的 Elo 等级分(对应获胜概率)。
除了对模型性能进行评估,理解这些智能体的行为及内部表征的复杂度也非常重要。
为了理解智能体如何表示游戏状态,我们对智能体神经网络的激活模式进行了研究,并且将其绘制在一个平面上。在下图中,一群群的点代表在游戏中的各种情景,相邻的点则代表相似的激活模式。我们根据高水平的 CTF 游戏状态来对这些点进行着色,这些状态包括:智能体在哪个房间中?旗帜的状态如何?可以看到哪些队友和对手?我们观察到的颜色相同的点簇,这代表的是智能体以相似的方式表示相似的高水平游戏状态。
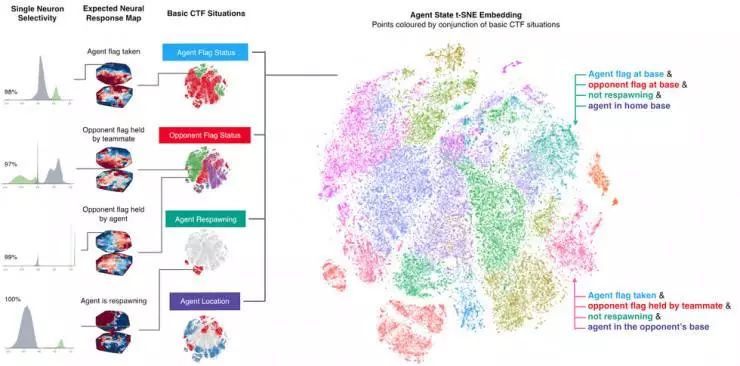
我们的智能体是如何表征游戏世界的?在上图中,我们根据每个代表神经激活模式的点与其它点的相似程度绘制出了某时刻的神经激活模式示意图:在空间中距离越近的两个点的激活模式越相似。接着,我们会根据它们在该时刻的情景对其进行着色——相同的颜色代表相同的情景。我们可以看到,这些神经元激活模式被组织了起来,形成了不同颜色的簇,这意味着智能体确实以一种有规则的、有组织的方式表示游戏玩法的某些有意义的因素。这些训练后的智能体甚至展示出了一些直接对特定情况编码的人工神经元。
智能体从未被告知任何有关游戏规则的信息,它们需要学习 CTF 的基本游戏概念并发展出自己有效的直觉。事实上,我们可以发现,某些特定的神经元会直接对最重要的游戏状态进行编码(例如,当智能体的旗帜被夺走时或智能体的队友夺到旗帜时,某个神经元就会被激活)。我们的论文针对智能体对内存的利用和视觉注意力机制的使用进行了进一步的分析。
表现与人类相媲美的智能体
我们的智能体在游戏中的表现如何,又是如何采取行动的呢?
首先,我们注意到智能体的反应时间非常短,并且攻击十分精准,这或许就解释了他们为什么会有如此出色的表现(「攻击」是一种战术行为,能够将对手送回到他们的出发点)。人类对于这些感官输入的处理和反应速度相对来说要慢一些,这是因为我们的生物信号比智能体的电子信号要慢一些。这里有一个反应时间测试的例子,链接乳腺,你可以自己动手试试:
https://faculty.washington.edu/chudler/java/redgreen.html
因此,我们智能体的卓越表现可能要归功于它们更快的视觉处理和运动控制能力。然而,通过人为地降低它们攻击的准确率、增加其反应时间,我们发现这只是它们取得成功的众多因素中的一个。在更加深入的研究中,我们训练了内置 1/4 秒(267 毫秒)延迟的智能体。也就是说,这些智能体在观察世界之前会有 267 毫秒的滞后,这与统计出的人类电子游戏玩家的反应时间相当。尽管如此,这些带有反应延迟的智能体仍然比人类玩家的表现要好:人类玩家中的强者在智能体面前只有 21% 的胜率。
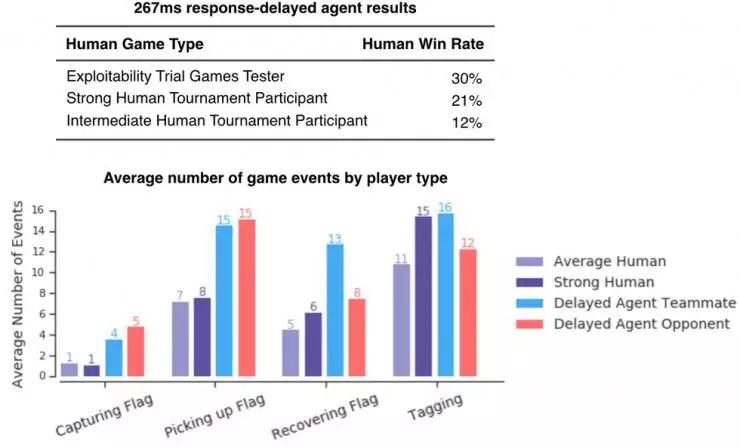
人类玩家在反应延迟的智能体面前,其胜率也很低,这说明即使反应延迟的时间与人类相当,智能体也比人类玩家表现好。除此之外,通过观察人类玩家和反应延迟的智能体的玩游戏情况,我们可以看到二者发生攻击事件的数目相当,说明这些智能体在这个方面与人类相比并不具有优势。
通过无监督学习,我们构建了智能体和人类的原型行为模式,发现智能体实际上是学习到了人类相类似的行为,例如跟随队友以及在对手的基地蹲点。

示例中,经过训练的三个智能体可以自动发现行为。
通过强化学习和种群水平的演进,这些行为逐渐出现在训练过程中。而随着智能体学会通过更加复杂的方式进行协作,就会逐渐淘汰掉像跟随队友这样的简单行为。
FTW 智能体种群的训练过程。左上角:30 个智能体在训练和相互演化的过程中得到的 Elo 等级评分。右上角:这些演化事件的遗传树。底部的图片显示了在智能体的训练过程中知识、内部奖励以及行为概率的变化情况。
未来的研究
尽管本论文重点关注的是 CTF,但我们的工作对于科学研究的贡献是通用的,我们非常乐见其他研究者基于我们的技术在各不相同的复杂环境中开发相关技术。自从最初发布这些实验结果以来,我们看到了许多人成功地将这些方法扩展到了「Quake III Arena」的完整游戏中,包括专业的游戏地图、更多 CTF 之外的多玩家游戏模式,以及更多的道具拾捡和使用动作。初步的结果表明,智能体可以在多种游戏模式和多张地图中表现出很强的竞争力,并且在测试比赛中开始逐渐对我们人类研究者的技能提出了挑战。实际上,这项工作中提出的一些概念(如基于种群的多智能体强化学习),构成了我们针对「星际争霸 2」设计的「AlphaStar agent」智能体(https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/)的基石。
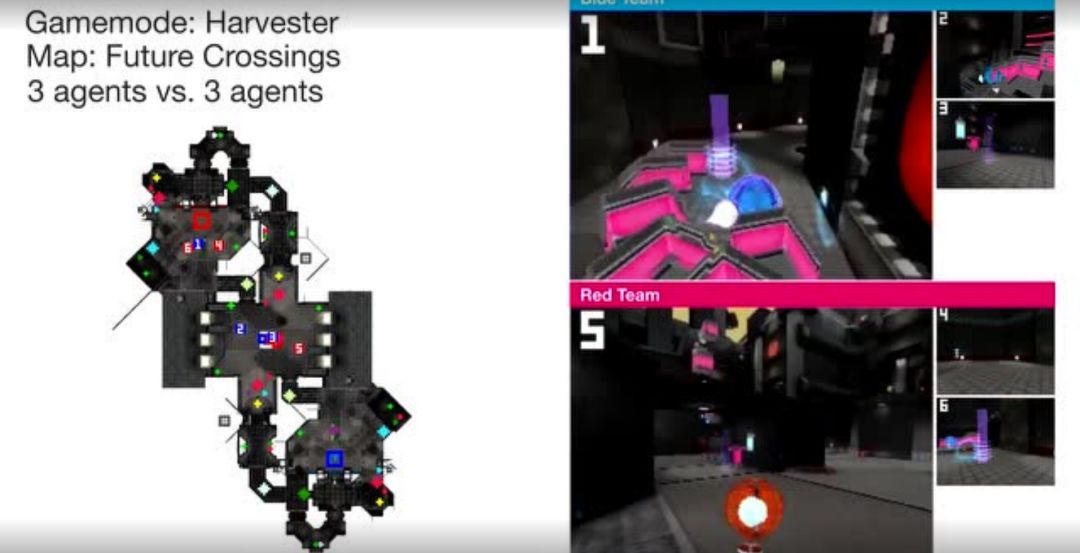

【注:微信只能插入三个视频,敬请扫描二维码查看】在另外两个「Quake III Arena」多人游戏模式下的完整版锦标赛地图上进行游戏的智能体:「Future Crossing」地图上的收割者模式,以及「Ironwood」地图上的单旗夺旗模式
总的来说,这项工作强调了多智能体训练在推动人工智能发展上显示的潜力:利用多智能体训练所提供的自然学习信息,同时也能促使我们开发出甚至可以与人类合作的鲁棒的智能体。
论文下载地址:https://arxiv.org/abs/1807.01281
完整的补充讲解视频:https://youtu.be/dltN4MxV1RI
via https://deepmind.com/blog/capture-the-flag-science/
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。




