KDD 2020 开源论文 | 图神经网络多变量时序预测

©PaperWeekly 原创 · 作者|马敏博
学校|西南交通大学硕士生
研究方向|命名实体识别
本次分享的论文是 KDD 2020 的一篇工作,出发点是为了更好地建模多变量时间序列数据中成对变量之间的潜在空间依赖。作者提出了一种通用的图神经网络框架 MTGNN,通过图学习模块融合外部知识和变量之间的单向关系,再使用 mix-hop 传播层和膨胀 inception 捕获空间和时序依赖。

论文标题:
Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks
论文来源:
KDD 2020
论文链接:
https://arxiv.org/abs/2005.11650
代码链接:
https://github.com/nnzhan/MTGNN
-
背景 -
挑战 -
MTGNN框架 -
实验解读 -
个人总结

背景
多变量时序预测在经济、金融、生物信息和交通等领域有广泛应用。相较于单变量时序预测,需要建模的问题更复杂,因为每个变量不仅与其历史值有关,还要考虑变量之间的依赖关系。
然而,现有的多变量时序预测方法并没有有效地探索变量之间的潜在空间依赖关系。统计方法如 VAR 和 GP 假设变量之间存在线性依赖关系,随着变量的增加,模型复杂度二次方增长,容易导致过拟合。深度学习方法如 LSTNet [1] 和 TPA-LSTM [2],虽然能够捕获非线性关系,但是无法明确地建模成对变量之间的依赖关系。

挑战
时空图神经网络是最适合多变量时序预测任务的图神经网络类型,因为多变量时序预测问题需要考虑时间维和空间维的信息表达。通常时空图神经网络以多变量时序数据和外部图结构作为输入,预测时序数据的未来值或标签。相较于未利用结构信息的方法,能够取得较大提升。但是,该方法仍然存在两个方面的挑战:
-
未知的图结构 :使用图神经网络建模时序预测任务时,大多依赖于预定义的图结构。但是,大多数情况下,多变量时序预测是没有明确的图结构,需要从数据中去学习变量之间的关系(图)。
-
图结构与图神经网络共同学习:现有方法大多专注于如何设计合适的图神经网络结构,却忽略了有时图结构(通常为邻接矩阵)有可能不是最优的,也需要在训练中优化。因此,对于时序问题,如何在一个 end2end 的框架下同时学习图结构和图神经网络是一个问题。

MTGNN 各部分之间的联系如下图所示,主要有三个模块组成图学习模块、图卷积模块、时序卷积模块。
下面根据上述两个挑战,介绍下本文的解决方案。
针对挑战1,作者提出了一个图学习层,能够自适应地从数据中抽取稀疏图邻接矩阵。此外,基于学习得到的图邻接矩阵,作者使用图卷积模块进行变量之间空间依赖学习。同时,作者对图卷积模块进行了改进,学习变量之间的单向依赖以及缓解图神经网络中的过度平滑问题。
针对挑战2,图学习层和图卷积模块都是参数化的,两者通过后向传播(梯度下降)方法共同优化。
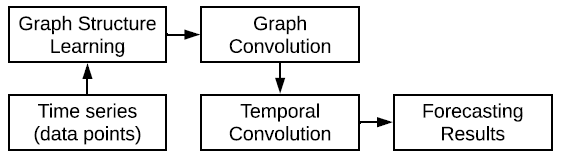
▲ MTGNN概念图
3.1 总体框架
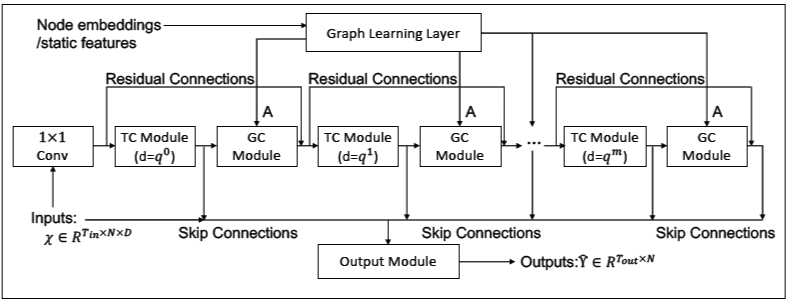
3.2 图学习层
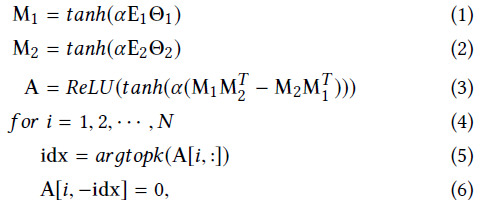
3.3 图卷积模块
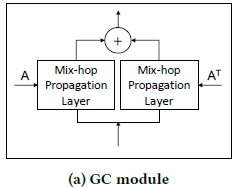
两个 mix-hop 分别处理单个节点的 inflow 信息和 outflow 信息,最终将两个信息相加所谓最终的模块输出信息。
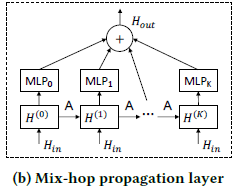
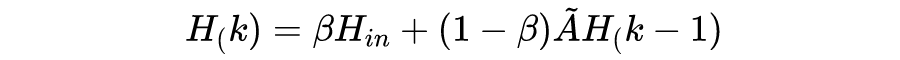
信息传播层递归地传播节点信息,在多层图卷积网络中会遇到一个问题,同一个连通图的节点表征随着网络层数的加深,趋向于一个相同的值,无法区分不同的节点(过度平滑问题)。公式 7 缓解过度平滑的方式为加入了一个初始节点信息保持因子,这样传播过程中节点既可以保持局部性,还可以得到更新的邻居信息。
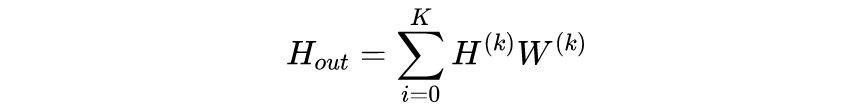
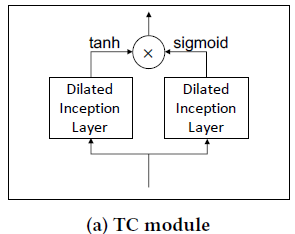
3.4 时序卷积模块
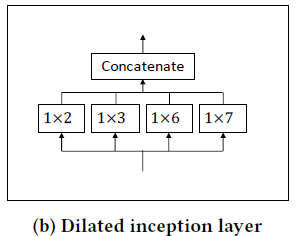
3.5 跳跃连接层和输出层
3.6 学习算法

▲ 学习算法流程
着重介绍下课程学习(Curriculum Learning),由 Benjio [5] 在 2009ICML 会议中提出。主要思想为:主张模型先学习“易样本”,再学习“难样本”。这样会带来两个好处:1. 加速模型训练,减少迭代次数;2. 达到更好的局部最优。在这个问题中,如何定义样本的难易是最关键的。
在本文的任务长期预测中,比较容易想到的是短期预测效果是肯定优于长期预测的,那么可以先学习短期的,再逐渐学习长期的。我这里介绍的比较口语化,原文从 loss 层面介绍,我理解的是如果长期预测,越长步数的预测值偏差越大,导致总 loss 会更大,即使取平均,相较于短期预测也会产生更大的 loss。
if self.iter%self.step==0 and self.task_level<=self.seq_out_len:
self.task_Level +=1其中 self.step 对应超参 step_size1,所以,若想 task_level 达到 seq_out_len,对于 batch_size 和 step_size1 的设置要合适。(感兴趣的可以去看下源码,这里不过多介绍。)

实验解读
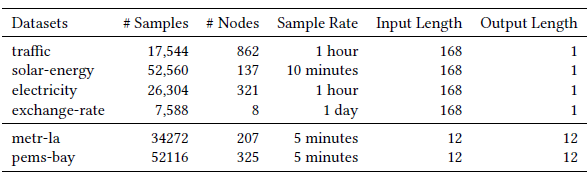
▲ 实验数据集
-
LSTNet [1] -
TPA-LSTM [2] -
DCRNN [6] -
STGCN [7] -
Graph WaveNet [8] -
ST-MetaNet [9] -
GMAN [10] -
MRA-BGCN [11]
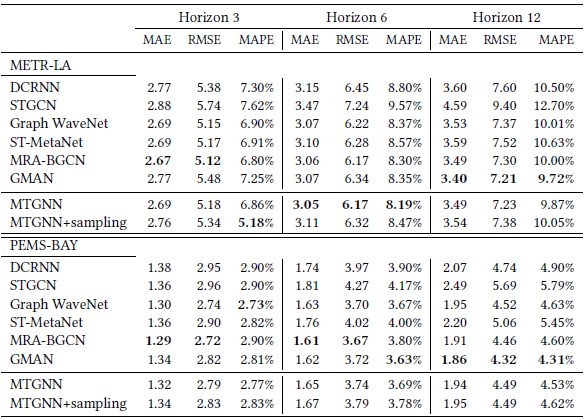
论文中做了多种实验,这里我主要介绍下与时空图神经网络相关的基线模型对比。从实验结果来看,MTGNN 可以取得 SOTA 或者与 SOTA 相差无几的效果。相较于对比的方法,其主要优势在于不需要预定的图。其中 Graph WaveNet 是本文作者在 IJCAI 2019 的工作,也是自适应构建邻接矩阵,但是需要结合预定图才能取得较好的效果。

个人总结
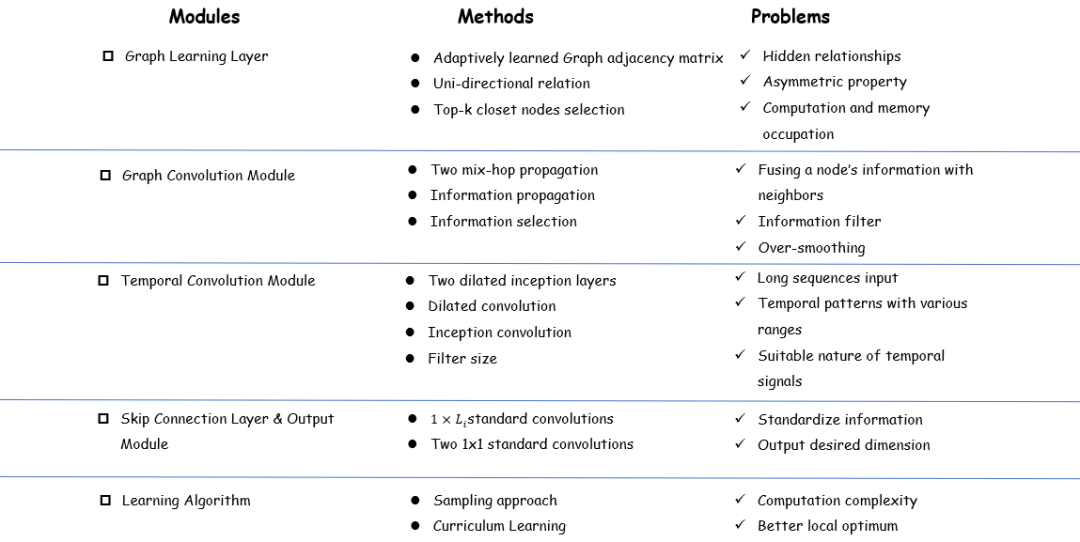
▲ 个人总结

参考文献
[1] Modeling long-and short-term temporal patterns with deep neural networks
[2] Temporal pattern attention for multivariate time series forecasting
[3] MixHop:Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
[4] DAGCN: Dual Attention Graph Convolutional Networks
[5] Curriculum Learning
[6] Diffusion convolutional recurrent neural network: Data-driven traffic forecasting.
[7] Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting
[8] Graph WaveNet for Deep Spatial-Temporal Graph Modeling.
[9] Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning
[10] GMAN: A Graph Multi-Attention Network for Traffic Prediction
[11] Multi-Range Attentive Bicomponent Graph Convolutional Network for Traffic Forecasting
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



