赛尔原创 | IJCAI 2019 New SOTA: 基于可迁移的BERT模型进行故事结尾预测
论文名称:Story Ending Prediction by Transferable BERT
论文作者:李忠阳,丁效,刘挺
原创作者:哈工大 SCIR 博士生 李忠阳
下载链接:http://ir.hit.edu.cn/~zyli/papers/ijcai19.pdf
1. 简介
最近的研究进展显示通过集成一个预训练好的语言模型和微调操作可以提升下游NLP系统的性能,例如GPT和BERT模型。然而,这一框架仍存在一些基本问题,例如不能够有效利用其它语义相关任务可以提供的有监督信息。在这篇论文中,我们展示了一个叫做Transferable BERT (TransBERT)的训练框架。对于一个目标任务,它不仅可以学习大规模未标注数据中的通用语言知识,而且可以有效利用各种语义相关任务提供的有监督信息。具体地,针对故事结尾预测任务,我们提出了三种语义相关的中间迁移任务,包括自然语言推断、情感分类和后续动作预测,在预训练模型的基础上来进一步训练BERT。这使得BERT可以学到更好的初始化参数。最终,我们在Story Cloze Test (SCT)两个版本的测试集上分别取得了91.8%和90.3%(Blind Test)的准确率,大幅超越了前人的模型。
2. 动机

图1. 故事结尾预测任务,以及与自然语言推理任务的关系
图1中展示了故事结尾预测(SCT)任务的定义:给出一个4句话组成的故事上文,从2个候选故事结尾中挑选出正确的那一个结尾。该任务需要模型对故事上下文进行正确的语义理解,并基于此进行常识推理,选择出逻辑合理的那个结尾。同时,从本图中我们可以看出该任务和自然语言推理 (NLI) 任务的内在关联:故事上文与正确结尾之间是蕴含关系,而和错误结尾之间是对立(或中立)关系。
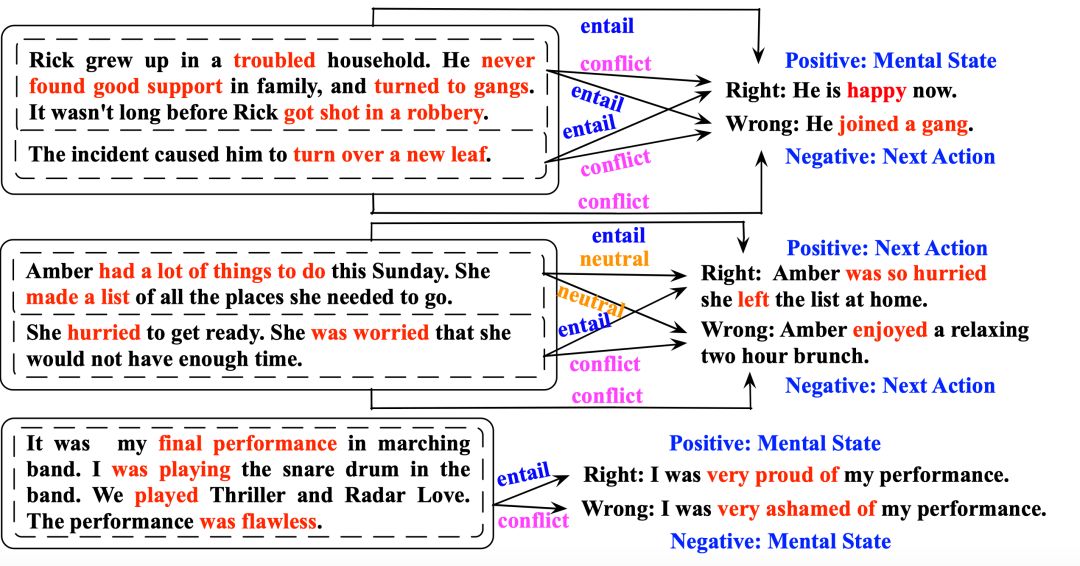
图2. 故事结尾预测与自然语言推理、情感分类、后续动作预测任务的关系
除了自然语言推理任务,我们发现故事结尾预测还和其他任务有内在的紧密关联,包括情感分析和后续动作预测任务。因为我们发现故事结尾预测任务的很多故事都是在描述情感和后续动作,两个候选结尾也通常描述了2种对立的情感或动作。图2中标注了一些故事结尾预测任务和自然语言推理、情感分析、动作预测任务之间的关联。更具体的讨论和分析可参见论文。
3. 方法
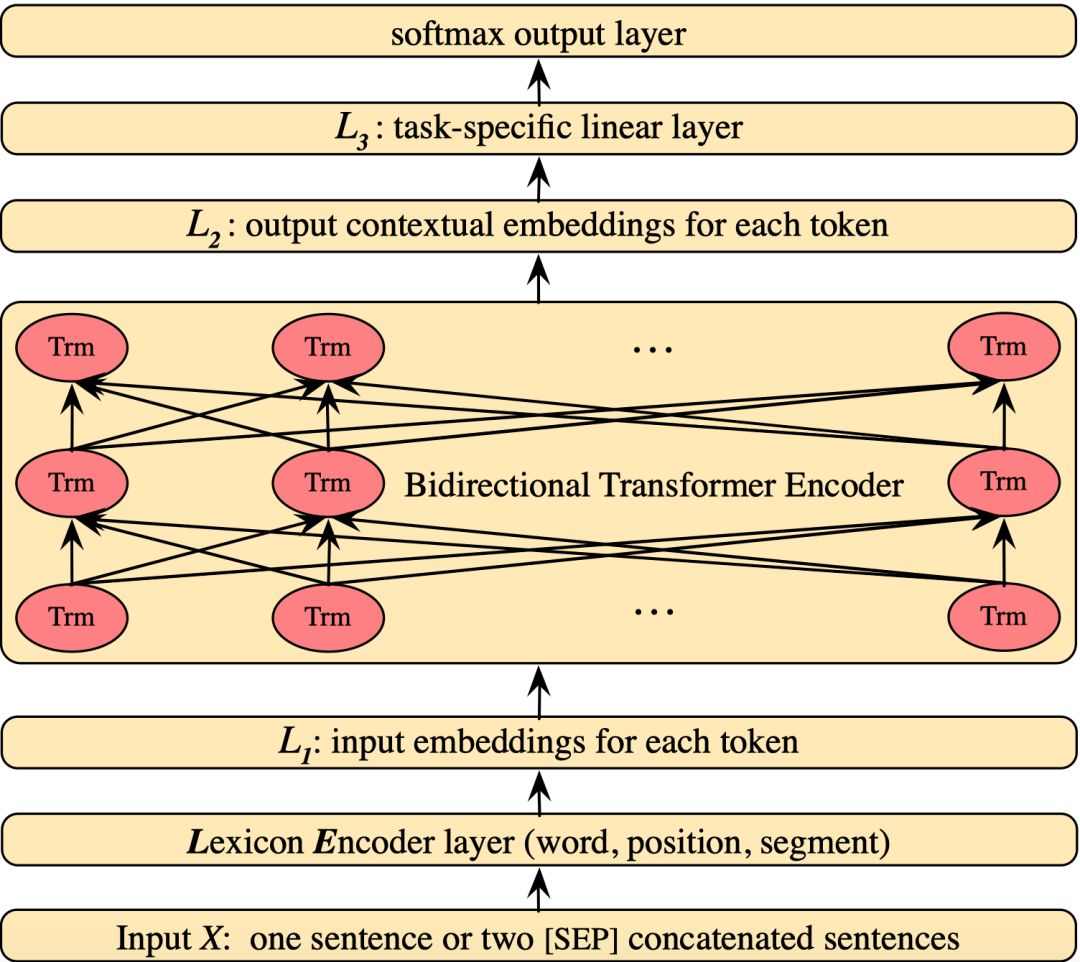
图3. BERT模型图
图3中显示了最近NLP领域大热的BERT模型图。GPT和BERT模型是相似的,都是采用两阶段的大规模无标注数据预训练和目标任务微调,来提升目标任务的性能。这本质上是一种迁移学习:预训练从大规模无标注数据中学习通用的语言知识,在微调阶段将通用语言知识迁移到目标任务中。
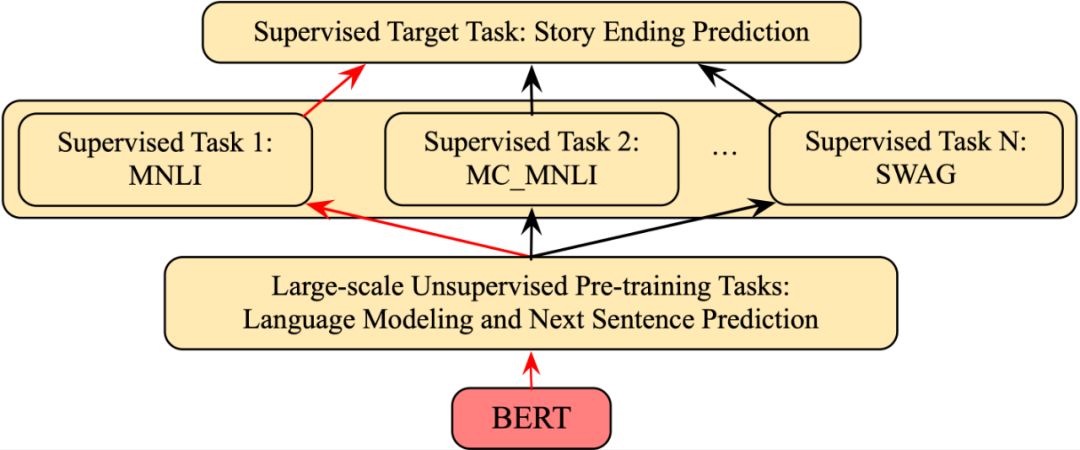
图4. 本文使用的训练框架:TransBERT
然而,我们认为这种两阶段应用方式仍然存在一些问题:只利用了大规模无标注数据中的通用语言知识,却没有有效利用大量人工标注的有监督数据集中的信息。因此,我们提出了图4中针对BERT模型的三阶段训练框架:大规模无标注数据的预训练、中规模语义相关有监督任务的有监督训练、小规模目标任务上的微调。该训练框架不仅可以学习大规模未标注数据中的通用语言知识,而且可以有效迁移各种语义相关任务提供的有监督信息到目标任务上。
4. 实验
4.1 数据集
表1. 数据集统计

本文使用了ROCStoriesV_1.0和ROCStoriesV_1.5两个版本的目标任务数据集进行实验评估。数据集统计和划分见表1。第二阶段的中规模有监督任务分别采用了如下数据集:自然语言推理(SNLI,MNLI,MC_MNLI),情感分析(Twitter,IMDB),后续动作预测(SWAG)。关于数据集的更多细节详见论文。
4.2 实验结果
表2. 不同版本BERT模型在ROCStoriesV_1.0测试集上的2阶段训练实验结果

本工作中我们采用了谷歌公布的预训练好的BERT模型。由于存在多个不同版本(单语还是多语,是否进行lower case处理)的BERT模型,我们首先进行了初步的实验。结果如表2所示:(monolingual, uncased)版本的BERT_base模型取得了88.1%的准确率,(monolingual, cased)版本的BERT_large模型取得了90.0%的准确率。
表3. ROCStoriesV_1.0测试集上的实验结果
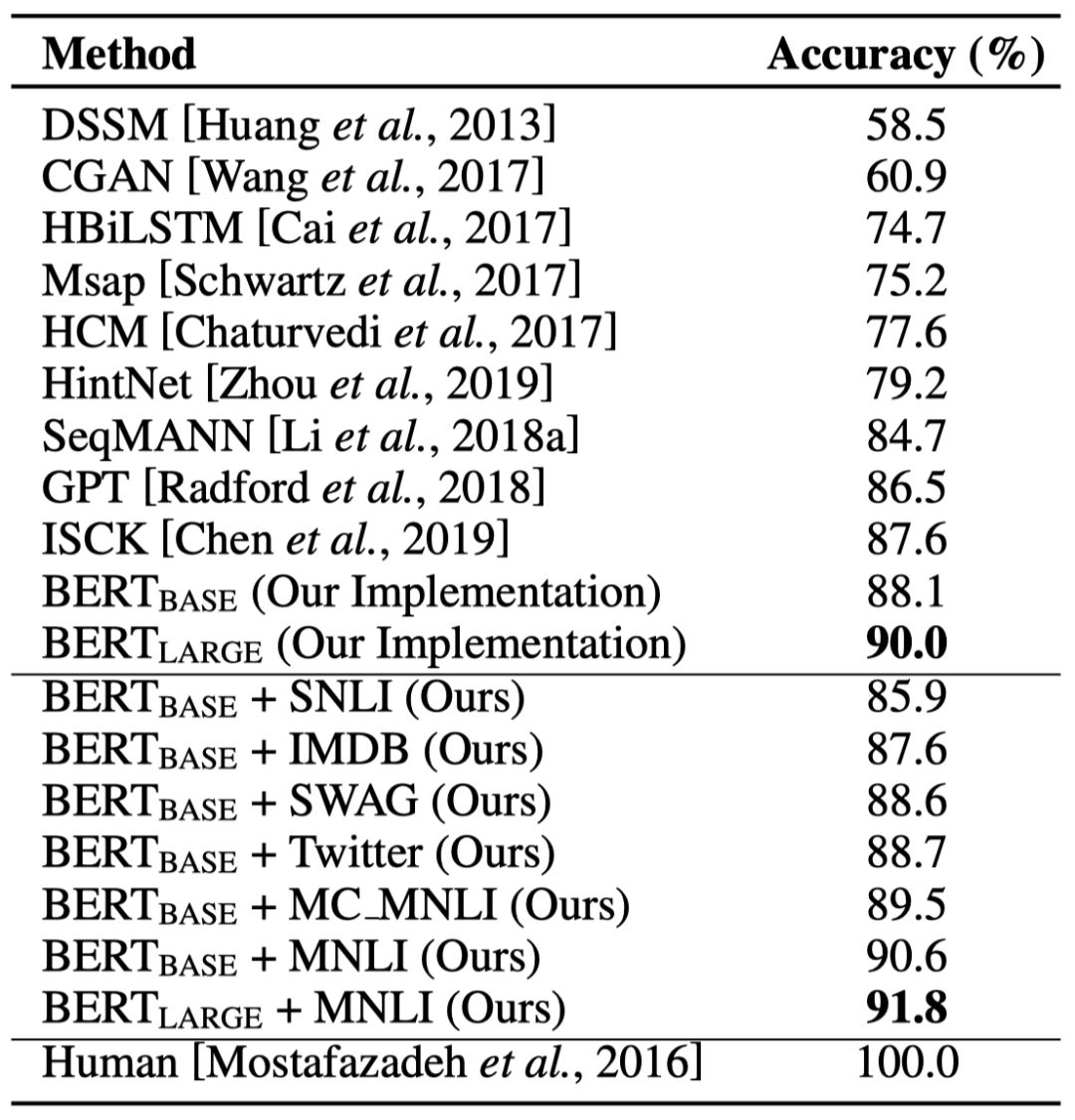
表3中展示了本文主要的实验结果。采用SNLI和IMDB作为第二阶段的有监督数据集,导致性能下降。采用SWAG, Twitter, MC_MNLI和MNLI都带来了一定的性能提升。其中采用MNLI作为第二阶段的有监督任务对BERT模型在SCT任务上的性能提升最大,分别将BERT_base和BERT_large提升到了90.6%和91.8%的准确率。同时,BERT_large+MNLI在ROCStoriesV_1.5 Blind测试集上取得了90.3%的准确率(未在表3中显示)。关于对实验结果的更多分析和讨论详见论文。
表4. 采用不同故事上文组合的实验结果
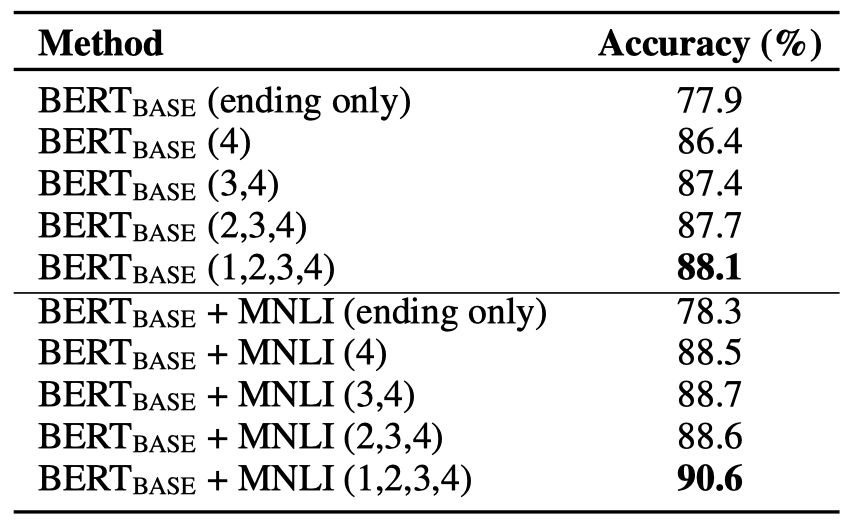
我们也进行了相关实验来验证BERT模型能否充分利用所有4句话组成的上文,实验结果如表4所示。可以看出随着故事上文长度和信息量的增加,BERT模型表现出越来越好的性能。
表5. 采用不同NLI关系类别的实验结果

我们还进行了实验来验证自然语言推理(NLI)任务中的3种关系哪个是最有用的,实验结果如表5所示(E表示Entailment,N表示Neutral,C表示Contradiction)。可以看出,移除Contradiction类别后,准确率从88.1%下降到了86.2%,说明Contradiction是最有用的,其次是Entailment。当采用全部三种关系ENC时,取得了最好的性能。
5. 结论
在本论文中,我们展示了一个三阶段的TransBERT训练框架,该训练框架不仅可以学习大规模未标注数据中的通用语言知识,而且可以有效迁移各种语义相关任务提供的有监督信息到目标任务上,例如故事结尾预测。该三阶段训练框架使得模型可以学习到针对目标任务的更好的初始化参数,相比之前的两阶段训练更有优势。针对故事结尾预测任务, 我们提出采用自然语言推理、情感分析和后续动作预测来作为第二阶段的有监督迁移任务。最终,采用MNLI数据集强化训练过的BERT_large模型在故事结尾预测任务上的两个版本数据集上分别取得了91.8%和90.3%的SOTA准确率。
本期责任编辑:刘一佳
本期编辑:赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




