

摘要
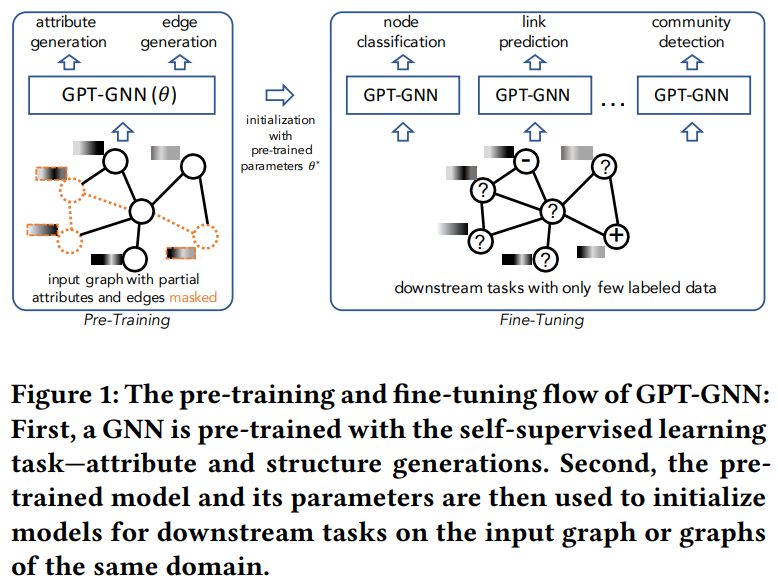
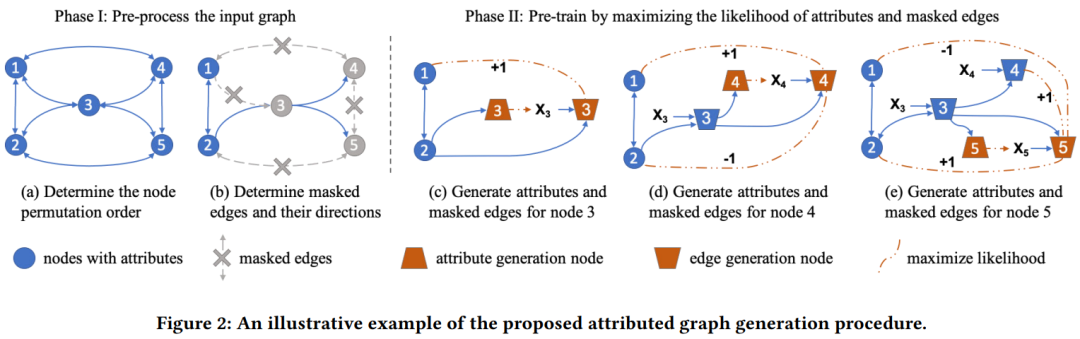
图神经网络(GNNs)已被证明在建模图结构的数据方面是强大的。然而,训练GNN通常需要大量指定任务的标记数据,获取这些数据的成本往往非常高。减少标记工作的一种有效方法是在未标记数据上预训练一个具有表达能力的GNN模型,并进行自我监督,然后将学习到的模型迁移到只有少量标记的下游任务中。在本文中,我们提出了GPT-GNN框架,通过生成式预训练来初始化GNN。GPT-GNN引入了一个自监督属性图生成任务来预训练一个GNN,使其能够捕获图的结构和语义属性信息。我们将图生成的概率分解为两部分:1)属性生成和2)边生成。通过对两个组件进行建模,GPT-GNN捕捉到生成过程中节点属性与图结构之间的内在依赖关系。在10亿规模的开放学术图和亚马逊推荐数据上进行的综合实验表明,GPT-GNN在不经过预训练的情况下,在各种下游任务中的表现显著优于最先进的GNN模型,最高可达9.1%。
**关键词:**生成式预训练,图神经网络,图表示学习,神经嵌入,GNN预训练
成为VIP会员查看完整内容
相关内容

专知会员服务
78+阅读 · 2020年3月1日

相关VIP内容
专知会员服务
78+阅读 · 2020年3月1日
相关资讯
相关论文