Presto on Apache Kafka 在 Uber的大规模应用

作者 | Uber Engineering
本文最初发布于Uber官方博客,InfoQ经授权翻译如下
Uber 的目的就是要让全世界变得更好,而大数据是一个非常重要的部分。Presto 和 Apache Kafka 在 Uber 的大数据栈中扮演了重要角色。Presto 是查询联盟的事实标准,它已经在交互查询、近实时数据分析以及大规模数据分析中得到应用。Kafka 是一个支持很多用例的数据流中枢,比如 pub/sub、流处理等。在这篇文章中,我们将探讨如何将这两个重要的服务结合起来,即在 Uber 的 Kafka 上,通过 Presto 实现轻量级的交互式 SQL 查询。
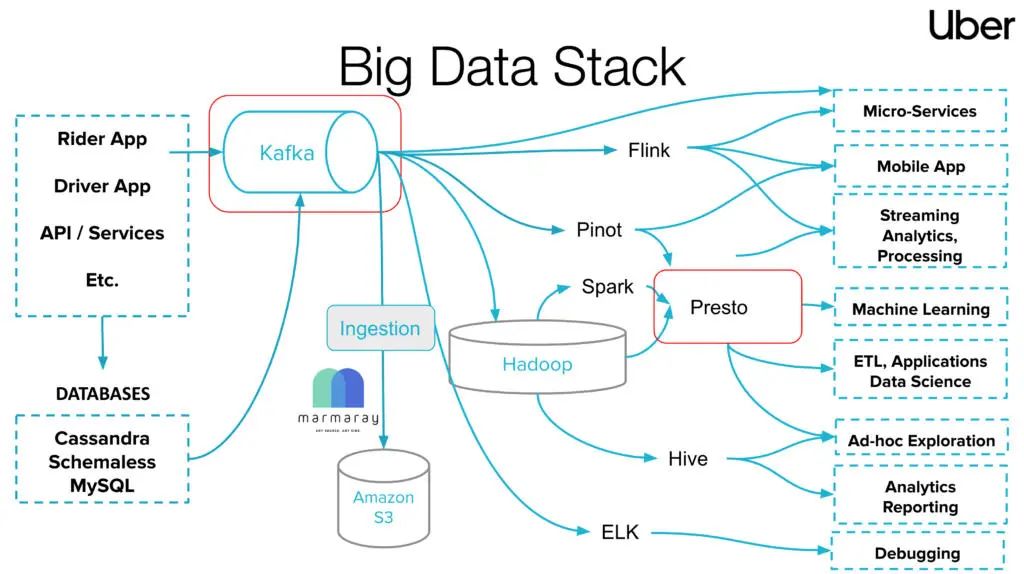
图 1:Uber 的大数据栈
Uber 通过开源的 Presto,可以对任何数据源进行查询,不管是动态数据还是静态数据。Presto 的多功能性让我们可以做出智能的、数据驱动的业务决策。我们运营着大约 15 个 Presto 集群,跨越 5000 多个节点。我们拥有 7000 个每周活跃的用户,他们每天都会进行 50 万次的查询,从 HDFS 中读取 50PB 左右的数据。现在,Presto 可以通过可扩展的数据源连接器,查询多种数据源,比如 Apache Hive、Apache Pinot、AresDb、MySQL、Elasticsearch 和 Apache Kafka。你还可以在我们之前的一些博文中找到更多有关 Presto 的信息:
《在 Uber 使用 Presto 和 Apache Parquet 进行工程数据分析》(Engineering Data Analytics with Presto and Apache Parquet at Uber)
《构建一个更好的大数据架构:认识 Uber 的 Presto 团队》(Building a Better Big Data Architecture: Meet Uber’s Presto Team)
Uber 是 Apache Kafka 部署规模最大的公司之一,每天处理数万亿条消息和多达 PB 的数据。从图 2 可以看出,Apache Kafka 是我们技术栈的基础,支持大量不同的工作流,其中包括一个 pub-sub 消息总线,用于从 Rider 和 Driver 应用中传送事件数据,诸如 Apache Flink® 的流分析,把数据库变更记录传送到下游用户,并且把各种各样的数据摄入到 Uber 的 Apache Hadoop® 数据湖中。我们已经完成了许多有趣的工作,以保证其性能、可靠性和用户友好,比如:
《Uber 的多区域 Kafka 的灾难恢复》(Disaster Recovery for Multi-Region Kafka at Uber)
《使用消费者代理实现无缝 Kafka 异步排队》(Enabling Seamless Kafka Async Queuing with Consumer Proxy)
《使用 Apache Flink、Kafka 和 Pinot 进行实时精确的广告事件处理》(Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot)
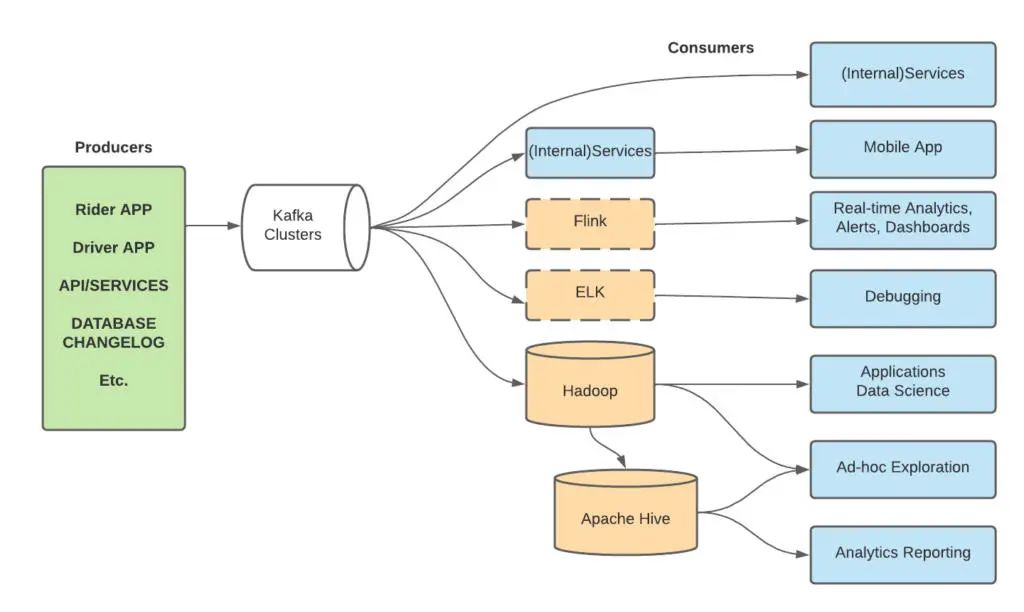
图 2:Uber 的 Kafka 项目
多年来,Uber 的数据团队对于 Kafka 流的分析需求不断增加,这是由于实时数据的及时、临时的数据分析为数据科学家、工程师和运营团队提供了宝贵的信息。
下面是 Kafka 团队的一个典型请求示例:运营团队正在调查为何一些消息没有被一个关键的服务所处理,从而会对最终用户造成直接影响。运营团队随后收集了一些 UUID,这些 UUID 报告了问题,并要求检查它们是否存在于服务的输入 / 输出 Kafka 流中。如图 3 所示,该请求可以被表述为查询:“Kafka 主题 T 中是否缺少 UUID 为 X 的顺序?”
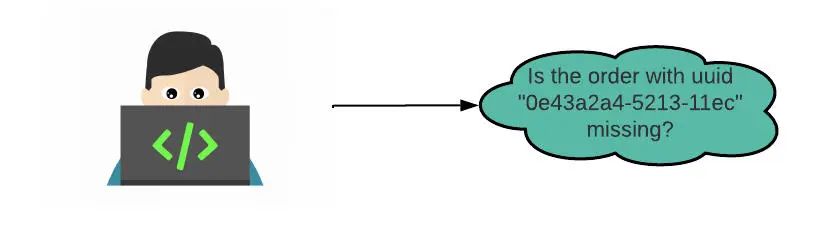
图 3:假定用例:检查 Kafka 主题中是否缺少 UUID X 的顺序
这样的问题一般都是由大数据进行实时分析来解决。在这个领域的各种技术中,我们专注于两类开源解决方案,即:流处理和实时 OLAP 数据存储。
流处理引擎,例如 Apache Flink、Apache Storm™ 或 ksql 可以持续地处理流,并且输出经过处理的流或者增量的维护可更新的视图。由于用户想要在以前的事件中执行点查询或者执行分析查询,所以这种流处理并不适用于以上问题。
另一方面,实时 OLAP 数据存储,如 Apache Pinot、Apache Druid 和 Clickhouse,则更适合。这些 OLAP 存储配备了高级的索引技术,所以可以为 Kafka 数据流建立索引,从而实现低延迟的查询。实际上,Uber 早在数年之前就已经开始使用 Apache Pinot,而现在,Pinot 已经成为 Uber 数据平台中的一个重要技术,它可以为多个关键任务进行实时分析应用。你可以看看我们以前发表的博文,讨论 Uber 如何使用 Pinot。
但是,实时 OLAP 需要一个非同寻常的加载过程,以创建一个从 Kafka 流中摄入的表,并对该表进行优化以达到最好的性能。另外,OLAP 存储还需要存储和计算资源来提供服务,因此这种解决方案被推荐给那些反复查询表并要求较低延迟的用例(如面向用户的应用),但不包括临时性的故障排除或探索。
所以,这个问题促使 Kafka 和 Presto 团队共同寻找一种基于下列因素的轻量级解决方案:
它重用了现有的 Presto 部署,这是一项成熟的技术,在 Uber 已有多年实战检验。
它不需要任何加载:Kafka 主题可以被发现,并且在创建后可以立即被查询。
Presto 以其强大的跨数据源的查询联合能力而闻名,因此可以让 Kafka 和其他数据源(如 Hive/MySQL/Redis)进行关联,从而获得跨数据平台的洞察力。
然而,这种 Presto 方法也存在其局限性。例如,由于 Kafka 连接器没有建立索引,所以它的性能比实时 OLAP 存储要差。另外,对于 Uber 的可扩展性需求,在连接器上还有其他挑战需要解决,我们将在下一节详细说明。
Presto 已经有一个 Kafka 连接器,支持通过 Presto 查询 Kafka。然而,这个解决方案并不完全适合我们在 Uber 的大规模 Kafka 架构。其中存在一些挑战:
Kafka Topic 和 Cluster Discovery:在 Uber,我们将 Kafka 作为一种服务来提供,用户可以随时通过自助服务门户向 Kafka 搭载新的主题。因此,我们必须要有一个动态的 Kafka 主题发现。但是,当前 Presto Kafka 连接器中的 Kafka 主题和集群发现是静态的,因此需要我们在每次搭载新主题时都要重启连接器。
数据模式发现:与 Kafka 主题和集群发现类似,我们将模式注册作为一项服务提供,并支持用户自助加载。因此,我们需要 Presto-Kafka 连接器能够按需检索最新的模式。
查询限制:对于我们来说,限制每一个查询能够从 Kafka 中消耗的数据数量非常重要。Uber 拥有很多大型的 Kafka 主题,其字节率可以达到 500M/s。我们知道,与其他替代方案相比,Presto-Kafka 查询速度相对缓慢,而要从 Kafka 中提取大量数据的查询,则要花费相当长的时间。这对于用户的体验和 Kafka 集群的健康都是不利的。
配额控制:作为一个分布式的查询引擎,Presto 可以以非常高的吞吐量同时消耗 Kafka 的消息,这可能会导致 Kafka 集群的潜在集群退化。限制 Presto 的最大消费吞吐量对于 Kafka 集群的稳定性至关重要。
Uber 的数据生态系统为用户提供了一种方法,可以编写一个 SQL 查询,并将其提交给 Presto 集群执行。每个 Presto 集群都有一个协调器节点,负责解析 SQL 语句,规划查询,并为人工节点执行的任务进行调度。Presto 内部的 Kafka 连接器允许将 Kafka 主题作为表格使用,主题中的每条消息在 Presto 中被表示为一行。在收到查询时,协调器会确定查询是否有适当的过滤器。一旦验证完成,Kafka 连接器从 Kafka 集群管理服务中获取集群和主题信息,从模式服务中获取模式。然后, Presto 工作器与 Kafka 集群并行对话,获取所需的 Kafka 消息。我们还为 Presto 用户在 Kafka 集群上设置了一个代理配额,这可以防止集群的降级。
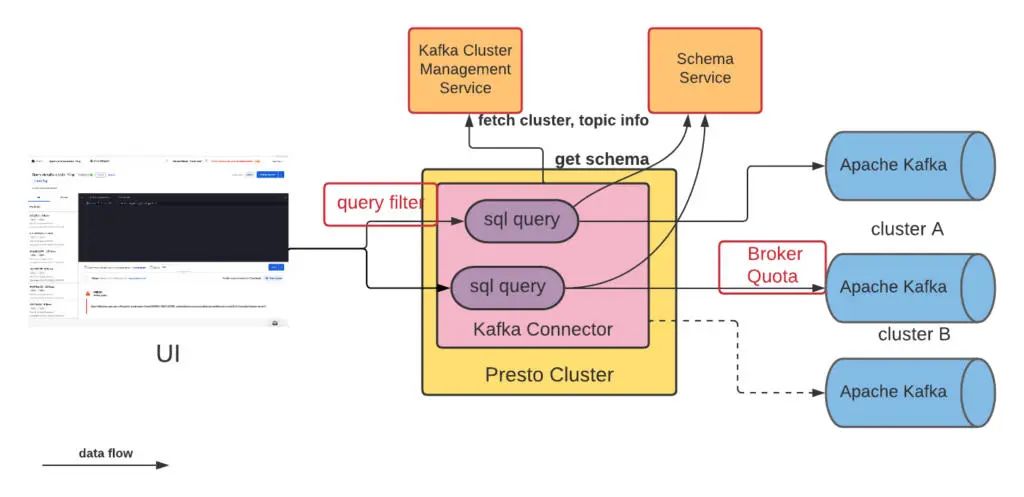
图 4:高级架构
下面几节将深入探讨我们为克服现有 Presto Kafka 连接器的局限性所做的改进,使其能够用于大规模用例。
我们做了一些改变以实现按需的集群 / 主题和模式发现。首先,Kafka 主题元数据和数据模式是在运行时通过 KafkaMetadata 获取的,我们提取了 TableDescriptionSupplier 接口来提供这些元数据,然后我们扩展了该接口并实现了一个新的策略,在运行时从内部 Kafka 集群管理服务和模式注册中心读取 Kafka 主题元数据。同样地,我们重构了 KafkaClusterMetadataSupplier,并实现了一个新的策略,在运行时读取集群元数据。由于集群元数据是按需获取的,我们也能够在一个 Kafka 连接器中支持多个 Kafka 集群。为所有这些元数据增加一个缓存层,以减少对 Kafka 集群管理模式服务的请求数量。
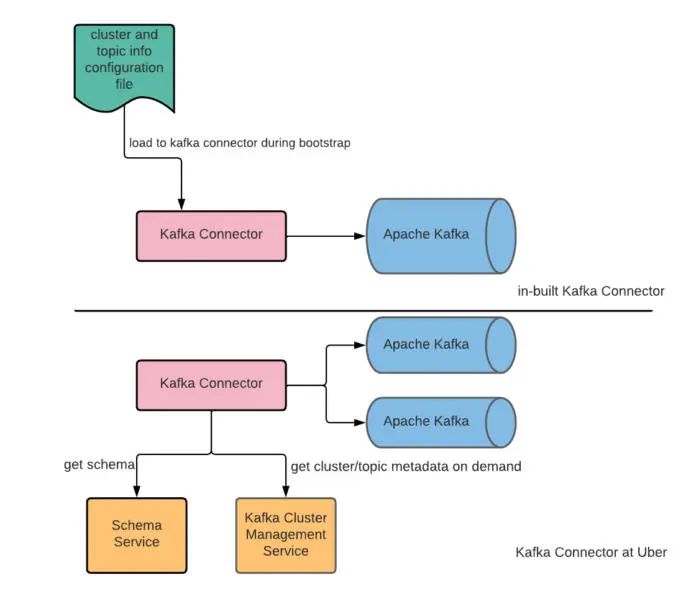
图 5:Kafka 集群 / 主题和数据模式发现
为了提高 Kafka 和 Presto 集群的可靠性,我们希望避免大型查询读取过多的数据。为了实现这一点,我们增加了列过滤器的执行,检查 Kafka 的 Presto 查询的过滤器约束中是否存在 _timestamp 或 _partition_offset。没有这些过滤器的查询将被拒绝。
Kafka 是 Uber 的一个重要的基础设施,有很多实时用例,Kafka 集群的退化可能会产生巨大的影响,所以我们要不惜一切代价避免它。作为一个分布式的查询引擎,Presto 可能会启动数百个消费者线程,从 Kafka 并发地获取消息。这种消费模式可能会耗尽网络资源,并导致潜在的 Kafka 集群退化,这是我们想要防止的。
我们可以做的一件事是,在 Presto 集群层面上限制消费率,但从 Presto 方面来说,这不是很容易实现。作为一种选择,我们决定利用 Kafka 的代理配额来实现我们的目标。我们做了一个改变,允许我们从连接器配置中指定一个 Kafka 消费者客户端 ID。有了这个改变,我们就能为 Presto 中的所有工作者使用一个静态的 Kafka 客户端 ID,而且他们将受制于同一个配额池。
当然,这种方法是有代价的。多个 presto 查询同时进行,将需要更长的时间来完成。这是我们不得不作出的牺牲。在现实中,由于我们拥有查询过滤器,所以大部分的查询都可以在一定的时间里完成。
在推出该特性后,我们看到在做临时探索时,生产力有了很大的提高。在这之前,工程师们需要花费数十分钟甚至更长的时间来查询我们上面提到的例子的数据,但现在我们可以写一个简单的 SQL 查询 SELECT * FROM kafka.cluster.order WHERE uuid= '0e43a4-5213-11ec',结果可以在几秒钟内返回。
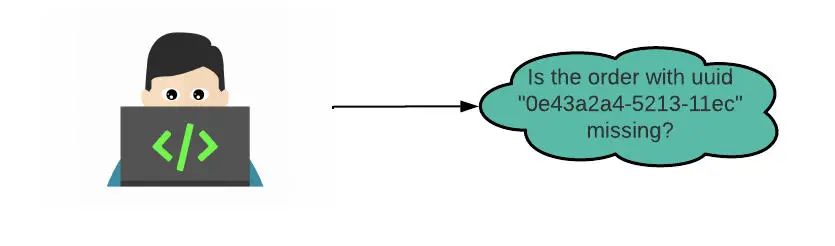
图 6:假设的用例。检查 Kafka 主题中是否缺少 UUID X 的顺序
截至写这篇博文时,越来越多的用户开始采用 Presto on Kafka 进行临时探索。每天有 6000 个查询,我们也从 Presto 用户那里得到了很好的反馈,他们说 Presto on Kafka 让他们的数据分析变得更加容易。
在未来,我们计划将我们所做的改进贡献给开源社区。你也可以查看我们的 PrestoCon 演讲,了解更多关于我们所做工作的细节。
作者介绍:
Yang Yang,Uber 流数据团队软件工程师,致力于在 Uber 构建高度可扩展、可靠的 Kafka 生态系统,包括 uReplicator、Kafka Consumer Proxy 等内部工具。
Yupeng Fu,Uber 数据团队首席软件工程师。领导几个流团队构建可扩展、可靠和性能良好的流解决方案。他还是 Apache Pinot 的提交者。
Hitarth Trivedi,Uber 数据分析团队的高级软件工程师。他主要负责 Presto 的工作。
原文链接:
https://eng.uber.com/presto-on-apache-kafka-at-uber-scale/

你也「在看」吗?👇



