一文详解 SpringBoot 多数据源中的分布式事务


作者 | 小涛
责编 | maozz
虽然现在微服务越来越流行,我们的系统随之也拆分出来好多的模块功能。这样做的目的其实就是为了弥补单体架构中存在的不足。
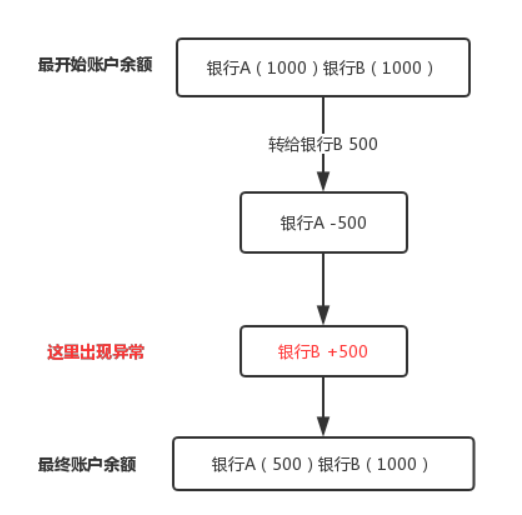
随着微服务的拆分,肯定设计到分库分表,但这之中肯定设计到分布式事务。最典型的例子就是银行转账,比如银行A给银行B转账500 块钱,流程肯定是银行A-500,银行B+500,在这个过程要么都成功,要么都成仁。
首先银行A和银行B的数肯定是在不同的数据库,如果在转账的过程中,银行A首先-500库钱之后,在银行B+500的时候出现了问题,如果事务不回滚,那么就会出现500块钱丢失的问题,也就是出现了事务一致性问题。

JTA + Atomikos解决分布式事务
JTA(java Transaction API)是JavaEE 13 个开发规范之一。Java 事务API,允许应用程序执行分布式事务处理——在两个或多个网络计算机资源上访问并且更新数据。JDBC驱动程序的JTA支持极大地增强了数据访问能力。事务最简单最直接的目的就是保证数据的有效性,数据的一致性。
Atomikos是一个为Java平台提供增值服务的并且开源类事务管理器。
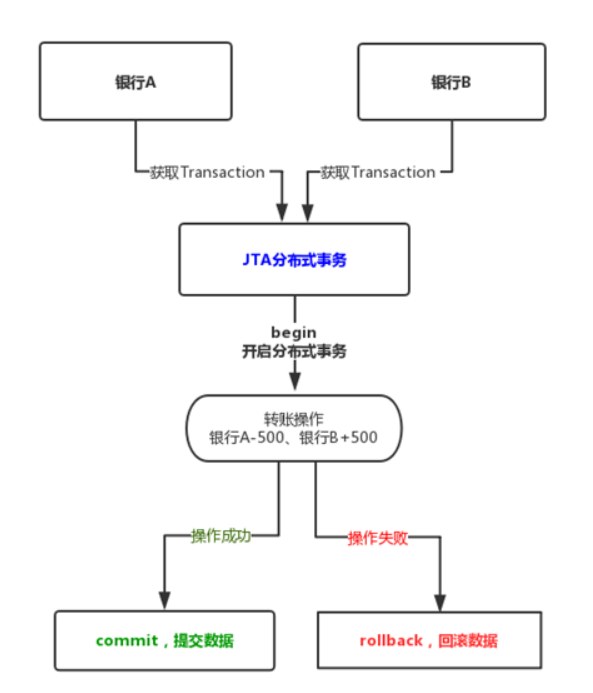
工作原理:分布式事务包括事务管理器和支持XA的资源管理器。资源管理器就是我们的DB,事务管理器就是承担调节和控制所有参与DB所设计到的事务。
个人理解:Atomikos 获取到数据库的连接之后,会屏蔽数据库底层事务控制,然后全部交给 Atomikos,进行统一的调度和控制。
接下来,我们简单的做一个基于 SpringBoot 的分布式事务控制。
1、首先我们要引入需要引入的maven库
<!--分布式事务-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
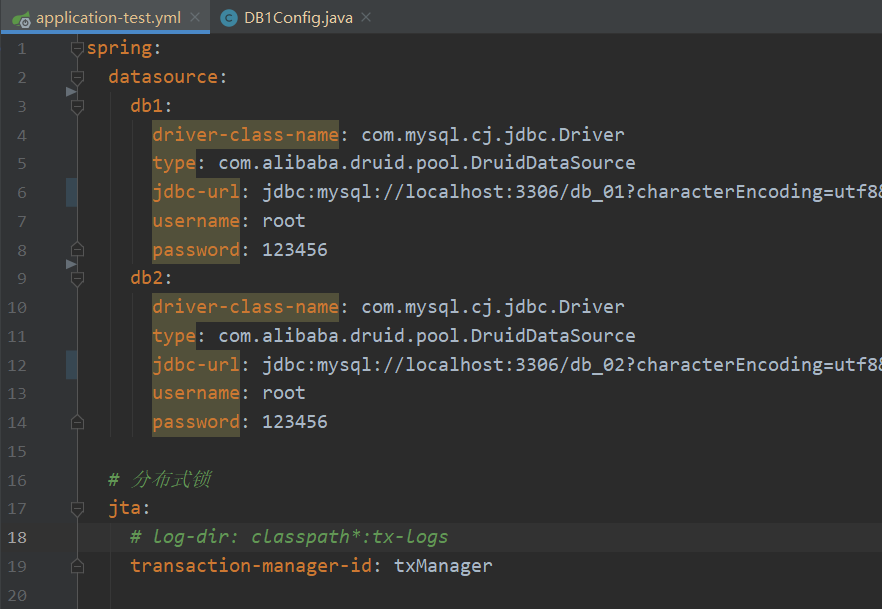
2、配置数据源
3、配置类
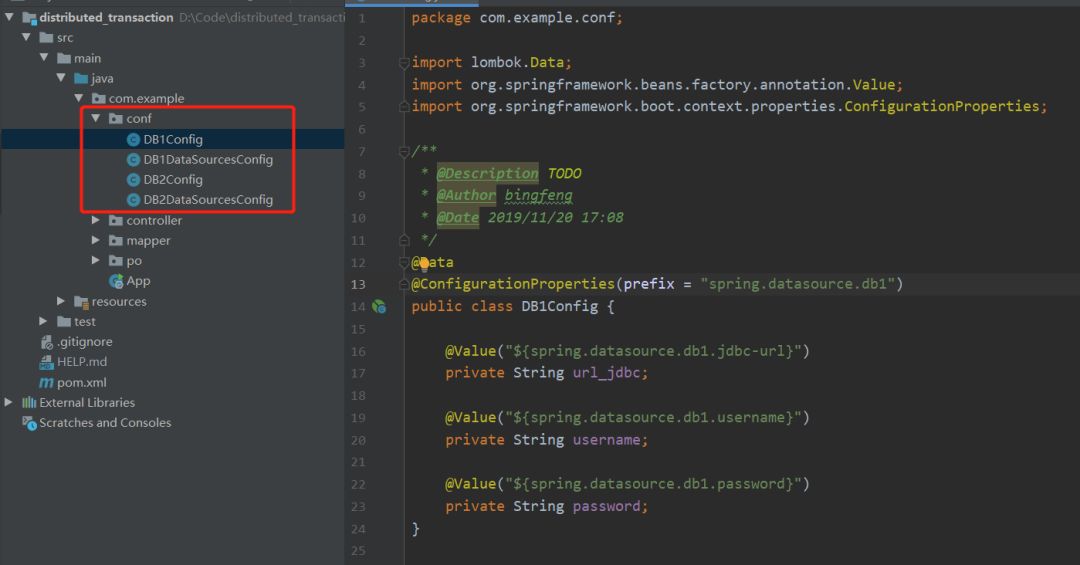
最主要的配置
@Configuration
@MapperScan(basePackages = "com.example.mapper.db1", sqlSessionFactoryRef = "db1SqlSessionFactory")
public class DB1DataSourcesConfig {
@Primary
@Bean(name = "db1DataSource")
public DataSource dataSource(DB1Config DB1Config) {
// 设置数据库连接
MysqlXADataSource mysqlXADataSource = new MysqlXADataSource();
mysqlXADataSource.setUrl(DB1Config.getUrl_jdbc());
mysqlXADataSource.setUser(DB1Config.getUsername());
mysqlXADataSource.setPassword(DB1Config.getPassword());
mysqlXADataSource.setPinGlobalTxToPhysicalConnection(true);
// 交给事务管理器进行管理
AtomikosDataSourceBean atomikosDataSourceBean = new AtomikosDataSourceBean();
atomikosDataSourceBean.setXaDataSource(mysqlXADataSource);
atomikosDataSourceBean.setUniqueResourceName("db1DataSource");
return atomikosDataSourceBean;
}
@Primary
@Bean(name = "db1SqlSessionFactory")
public SqlSessionFactory sqlSessionFactory(@Qualifier("db1DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean sessionFactoryBean = new SqlSessionFactoryBean();
sessionFactoryBean.setDataSource(dataSource);
sessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:/mapper/db1/*.xml"));
org.apache.ibatis.session.Configuration configuration = new org.apache.ibatis.session.Configuration();
configuration.setMapUnderscoreToCamelCase(true);
sessionFactoryBean.setConfiguration(configuration);
return sessionFactoryBean.getObject();
}
@Primary
@Bean(name = "db1SqlSessionTemplate")
public SqlSessionTemplate sqlSessionTemplate(@Qualifier("db1SqlSessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
这样基本就配置完了,这里我只写了一个数据库的配置,另外一个同这个一样,就是数据库信息变了而已。

测试
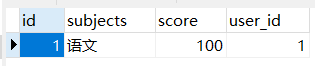
这里设计到两个数据的修改,学生姓名和学生分数成绩,这两个数据分别存储在不同的数据库。我们通过接口先修改用户信息,接着再修改用户的分数信息。
没有修改前的数据
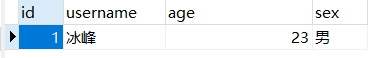
我们先没不加事务,先看下如果再修改分数的时候出现异常,用户信息会不会回滚回去。
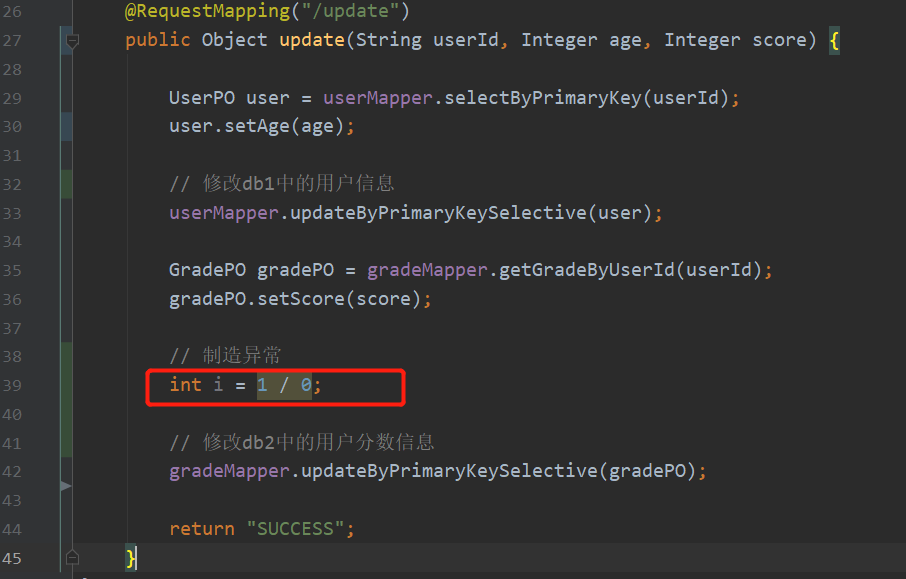

结果
首先代码在39行报错,如果按照我们的逻辑,如果修改分数失败,那么相应的用户的年龄修改也是不成功的,但是结果显示用户的年龄还是被修改了,显然这个接口并没有被分布式事务所管理。


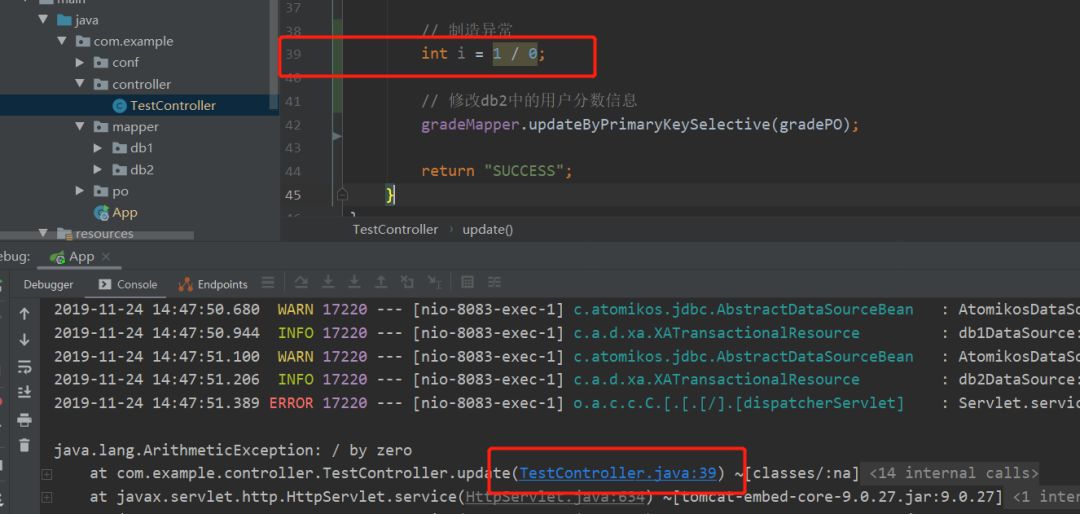
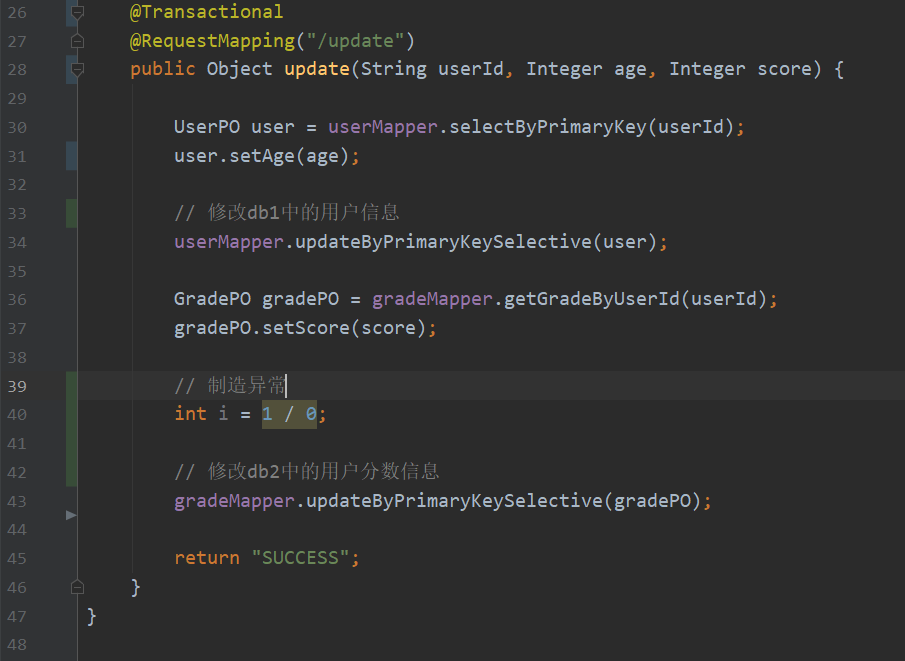
我们先把数据改回原来,然后我们再把事务加上,看还不会出现这种问题。(方法上加@Transactional注解即可)

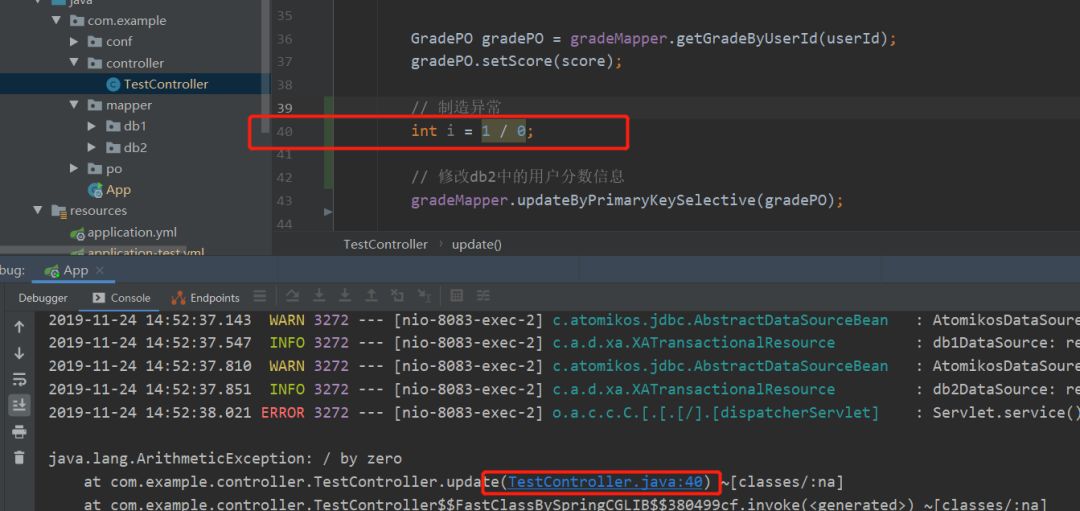
综合结果
加了分布式事务之后,通过结果就可以看到,如果后面的结果出现了错误,前面的数据也是会进行回滚的,保证了事务的前后一致性,确保了数据的安全准确。
总结:以上就是 JTA + Atomikos 实现分布式事务的整个过程,相对实现功能来说还是比较简单的,以上的测试是基于单个的 SpringBoot 项目的,相对于真正的微服务来说,这样的方式我还没有进行测试,如果需要进行微服务之间的事务管理,也可以通过 mq 或者 dubbo 去进行事务的一致性管理。
本文为作者投稿,版权归作者个人所有。

热 文 推 荐