成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
数据库
关注
24
数据库(
Database
)或数据库管理系统(
Database management systems
)是按照数据结构来组织、存储和管理数据的仓库。目前数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。
综合
百科
VIP
热门
动态
论文
精华
精品内容
【2023新书】MySQL书谱:数据库开发人员和管理员的解决方案第4版,972页pdf
专知会员服务
59+阅读 · 2023年8月2日
【SIGMOD2023】量子机器学习:数据库研究的基础、新技术与机遇,87页ppt
专知会员服务
34+阅读 · 2023年7月7日
数据库发展研究报告(2023年),53页pdf
专知会员服务
47+阅读 · 2023年7月5日
数据库行业发展报告
专知会员服务
40+阅读 · 2022年10月19日
【干货书】图数据科学:图算法,分析方法,平台,数据库,和用例,415页pdf
专知会员服务
79+阅读 · 2022年10月7日
华为发布业界首个《云原生数据库白皮书》,25页pdf
专知会员服务
50+阅读 · 2022年8月20日
推荐!《开发稳健的模型、算法、数据库和工具,并应用于网络安全和医疗保健领域》佐治亚理工学院219页博士学位论文,含答辩slides!
专知会员服务
26+阅读 · 2022年7月22日
【干货书】高效的MySQL性能最佳实践和技术,Efficient MySQL Performance Best Practices and Techniques
专知会员服务
24+阅读 · 2022年3月24日
基于深度学习的数据库自然语言接口综述
专知会员服务
32+阅读 · 2021年9月27日
【SIGMOD2021】数据库与人工智能交叉技术综述
专知会员服务
69+阅读 · 2021年7月14日
2021年金融级数据库容灾技术报告(附PDF全文)
专知会员服务
20+阅读 · 2021年7月11日
数据库发展研究报告(2021年)
专知会员服务
49+阅读 · 2021年6月29日
SIGMOD 2021最佳论文奖出炉,MIT等获数据管理最佳论文,苹果获得工业最佳论文
专知会员服务
19+阅读 · 2021年6月24日
《数据库管理系统的内存高效搜索树》,CMU博士、姚班助理教授张焕晨获SIGMOD Jim Gray博士论文奖
专知会员服务
8+阅读 · 2021年5月21日
基于机器学习的数据库技术综述
专知会员服务
55+阅读 · 2021年1月2日
参考链接
子主题
WAIM
AliSQL
JIIS
WISE
International Conference on Extending DB Technology
International Symposium on Spatial and Temporal Databases
SIGMOD
DPD
SQL
DMKD
IR
TODS
SSTD
KAIS
VLDB
JCIS
HeroDB
CIKM
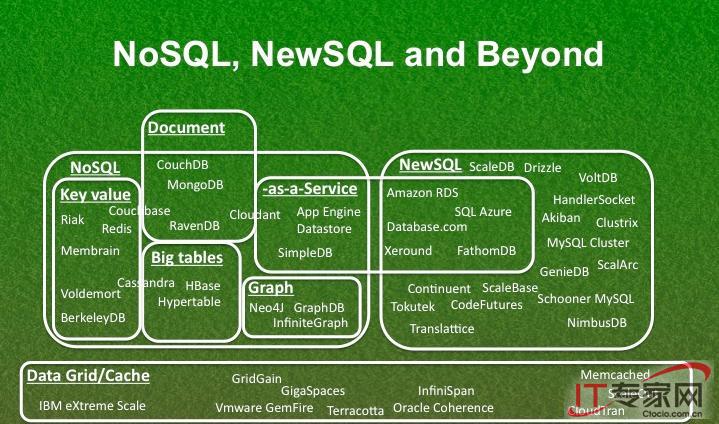
NoSQL
SSDBM
ICDM
VLDBJ
TKDE
AEI
IPL
Information Systems
TKDD
International Conference on Web Age Information Management
ESWC
International Conference on Conceptual Modeling
TOIS
International Conference on Mobile Data Management
ICDT
Sybase
SIAM International Conference on Data Mining
APWeb
WebDB
DEXA
PostgreSQL
DASFAA
Sql Server
SDM
oracle 数据库
SIGKDD
IJIS
JASIST
DKE
数据库技术
ISWC
GeoInformatica
Mysql
PAKDD
Pacific-Asia Conference on Knowledge Discovery and Data Mining
区块链
IJKM
WSDM
JSIS
ECIR
I&M
International Conference on Innovative Data Systems Research
International Conference on Scientific and Statistical DB Management
JDM
CIDR
ICDE
JGITM
Information Sciences
数据库性能
TWEB
SQLite
ECML-PKDD
IJCIS
数据库管理员(DBA)
OceanBase
JWS
txtSQL
PODS
IPM
EJIS
NewSQL
IJSWIS
IJGIS
ApsaraDB
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top